

| Introduction
As the world is busy taking help from ChatGPT to solve their day-to-day queries and enterprises are getting ready to apply the power of Large Language Models to their business use cases, everyone has unanimously agreed and submitted to the magnanimity and potential of these Large Language Models.
One use case which has been around from times much before the terms ‘GPT’ and ‘LLM’ were so popular, is converting a user-provided natural language query to a syntactically correct SQL query that can be directly executed on the database and results can be extracted.
You may have seen one of the early examples of this in action if you are a cricket enthusiast and follow the website AskCricInfo
This use case can be applied to any enterprise which wants to enable its leaders to get a direct handle on critical data and be able to query in plain-spoken language.
Text to SQL is one of the main capabilities of Large Language Models and can be achieved by providing proper prompts directing the model with the required table schema to be considered while generating the query.
In this blog, I will show you the steps to make use of the SQLDatabaseChain feature of LangChain to achieve Text-to-SQL functionality.
Getting started with the Postgresql DB
For this purpose, I will be using Postgresql provided by ElephantSQL
We will have a simple database of authors, the blogs written by them, and a frequency table to record the frequency of publishing blogs.
To start with we will define 3 tables as below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
CREATE TABLE authors ( author_id SERIAL PRIMARY KEY, name VARCHAR(255), Email VARCHAR(100), Social_media_handle VARCHAR(100), followers_count Integer , Area_of_expertise VARCHAR(255) ); CREATE TABLE blogs ( blog_id SERIAL PRIMARY KEY, title VARCHAR(255), author_id INTEGER , publish_date DATE, content TEXT, url VARCHAR(255), category VARCHAR(255), topic VARCHAR(255), FOREIGN KEY (author_id ) REFERENCES authors(author_id ) ); CREATE TABLE author_frequency ( author_frequency_id SERIAL PRIMARY KEY, author_id INTEGER, topic VARCHAR(255), frequency_3_months INTEGER, frequency_12_months INTEGER, period_start DATE, period_end DATE, FOREIGN KEY (author_id ) REFERENCES authors(author_id ) ); |
Using SQLDatabaseChain from LangChain
Now we will start a new jupyter notebook in a working environment or directly work on colab.
1 2 |
!pip install langchain from langchain import OpenAI, SQLDatabase, SQLDatabaseChain |
1 2 3 |
!pip install openai db = SQLDatabase.from_uri("postgresql://USE YOUR POSTGRESQL URI") llm = OpenAI(openai_api_key='USE YOUR OPENAI API KEY',temperature=0) |
Using the SQLDatabaseChain, you can setup your text to sql chain to connect to DB and answer your questions as below.
1 |
db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True) |
1 |
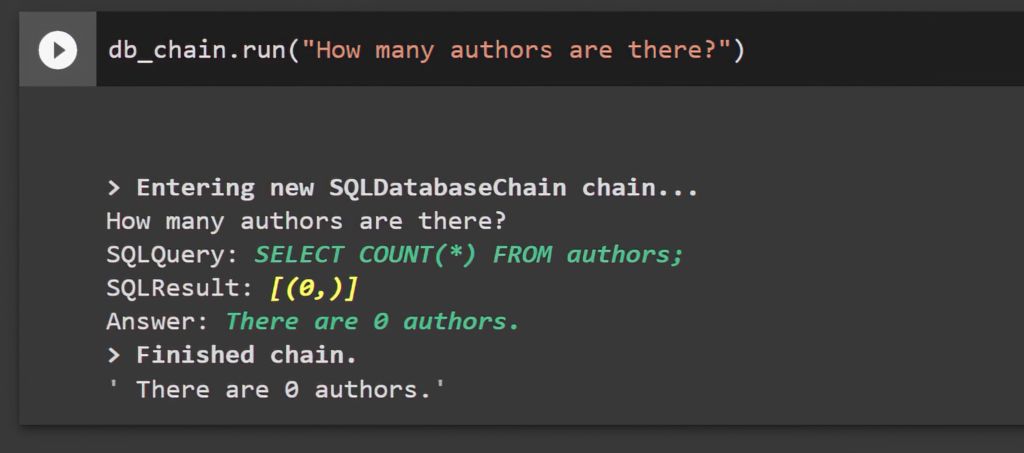
db_chain.run("How many authors are there?") |
You can see the response as below:
1 2 3 4 5 6 7 8 9 |
db_chain.run("How many authors are there?") > Entering new SQLDatabaseChain chain... How many authors are there? SQL Query: SELECT COUNT(*) FROM authors; SQLResult: [(0,)] Answer: There are 0 authors. > Finished chain. There are 0 authors.' |
The chain is working. Now we create some dummy data and then ask some more questions.
Below are some examples of spoken language questions which fetch data from the DB after creating dummy data.
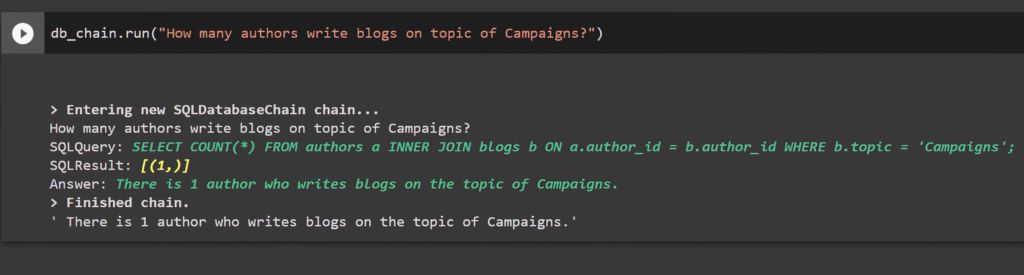
db_chain.run(“How many authors write blogs on topic of Campaigns?”)
1 2 3 4 5 6 7 |
> Entering new SQLDatabaseChain chain... How many authors write blogs on topic of Campaigns? SQL Query: SELECT COUNT(*) FROM authors a INNER JOIN blogs b ON a.author_id = b.author_id WHERE b.topic = 'Campaigns'; SQLResult: [(1,)] Answer: There is 1 author who writes blogs on the topic of Campaigns. > Finished chain. 'There is 1 author who writes blogs on the topic of Campaigns.' |
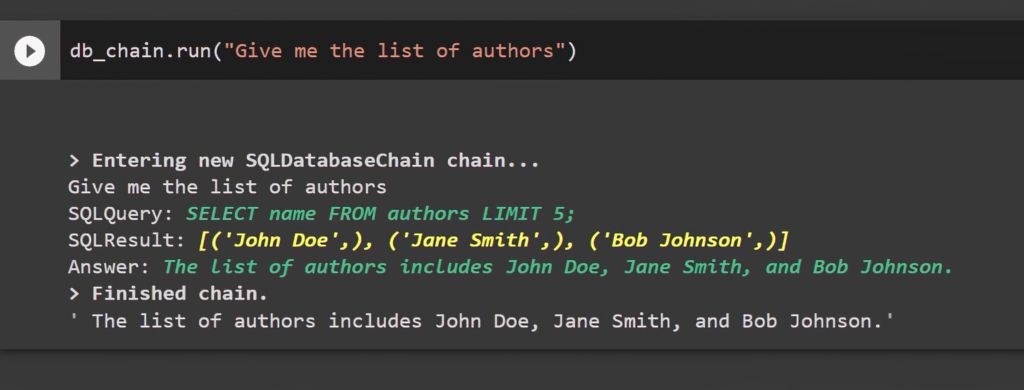
db_chain.run(“Give me the list of authors”)
1 2 3 4 5 6 7 |
> Entering new SQLDatabaseChain chain... Give me the list of authors SQL Query: SELECT name FROM authors LIMIT 5; SQL Result: [('John Doe',), ('Jane Smith',), ('Bob Johnson',)] Answer: The list of authors includes John Doe, Jane Smith, and Bob Johnson. > Finished chain. 'The list of authors includes John Doe, Jane Smith, and Bob Johnson.' |
Let’s try a somewhat complex one –
1 |
db_chain.run("Give me the list of authors who have published blogs on the topic of Campaigns") |
This one does not work and the LLM is fetching some wrong columns which do not exist.
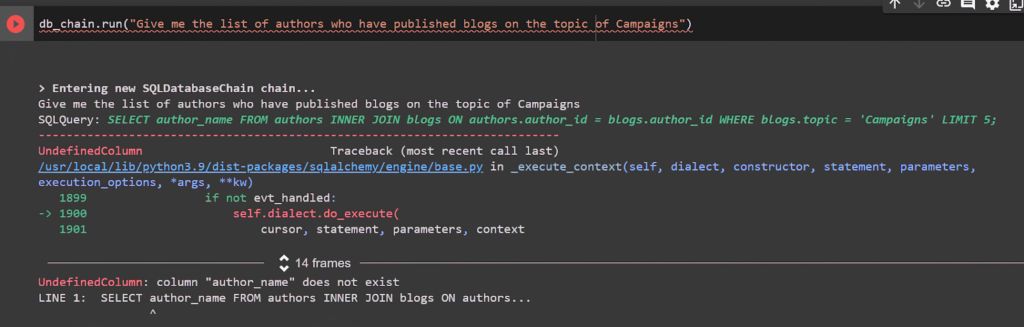 This will require some extra prompts to the LLM.
This will require some extra prompts to the LLM.
Using PromptTemplates from LangChain
Now we use another feature of LLMs – PromptTemplates
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
from langchain.prompts.prompt import PromptTemplate _DEFAULT_TEMPLATE = """Given an input question, first create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer. Use the following format: Question: "Question here" SQLQuery: "SQL Query to run" SQLResult: "Result of the SQLQuery" Answer: "Final answer here" Only use the following tables: {table_info} Use the table authors with author_id as primary key to get the list of authors and the table blogs with blog_id as the primary key to get the list of blogs and join the two tables on author_id. Question: {input}""" PROMPT = PromptTemplate( input_variables=["input", "table_info", "dialect"], template=_DEFAULT_TEMPLATE ) |
As part of the prompt template, you can provide any additional information to be used to build the query.
Now we will modify the prompt to make use of the prompt template defined above.
1 |
db_chain = SQLDatabaseChain(llm=llm, database=db, prompt=PROMPT, verbose=True) |
Now the earlier case works as you can see below and returns proper results.
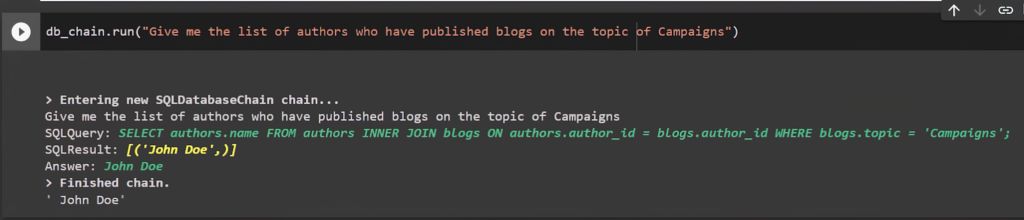
You can control the tokens by explicitly specifying which tables should be used when connecting to the DB to avoid unnecessary tables.
1 2 3 4 |
db = SQLDatabase.from_uri( "postgresql://prqwtgyt:l0V88hosdvn6Ri0LzvPauKCj7mN-q4dI@ziggy.db.elephantsql.com/prqwtgyt" include_tables=['Authors', 'Blogs', 'Author_Frequency'], sample_rows_in_table_info=2, custom_table_info=custom_table_info) |
You can also return and access the intermediate steps of a SQL database chain using the parameter return_intermediate_steps as true. This includes the generated SQL query, and the raw sql result.
To safeguard data-sensitive projects, you may opt for return_direct=True during the initialization of SQLDatabaseChain, which will enable you to directly receive the output of the SQL query, without any extra formatting. This approach will prevent any content within the database from being visible to the LLM. It is worth noting, however, that the LLM will still have access to the database scheme by default, which includes dialect, table, and key names.
Conclusion
Prompt engineering powered by LLMs and supported by the LangChain framework can enable you to write more complex queries on bigger databases bringing to you the power of Language.
This is one of the multiple capabilities which LLMs provide and which is further facilitated by the LangChain framework. You can apply this to different use cases where you want to simplify the interaction with your data and make it more accessible to enterprise users.
In future blogs, we will explore more of these use cases.
Do connect with us to learn how you can apply this to your enterprise and unleash the power of LLMs.