Blogs
Unlocking Customer Insights: Leveraging Langchain and Deeplake for Enhanced Support Transcript Analysis
![]() Understanding the customer is vital for business success, as it allows companies to tailor their products, services, and support interactions to meet customer expectations. However, a significant challenge lies in the vast volume of untapped support interaction data that holds valuable insights. Without a detailed analysis of customer support transcripts, businesses miss out on identifying trends, recurring issues, and areas for improvement.
Understanding the customer is vital for business success, as it allows companies to tailor their products, services, and support interactions to meet customer expectations. However, a significant challenge lies in the vast volume of untapped support interaction data that holds valuable insights. Without a detailed analysis of customer support transcripts, businesses miss out on identifying trends, recurring issues, and areas for improvement.
Analyzing customer support transcripts provides comprehensive insights into customer needs, preferences, and pain points. It empowers companies to make data-driven decisions, enhance their offerings, and deliver personalized experiences. Moreover, proactive analysis helps identify and address customer issues before they escalate, improving satisfaction and fostering long-term relationships. By harnessing the power of detailed analysis, businesses can transform support interaction data into a valuable source of knowledge and gain a competitive edge.
Harnessing the power of Language Models (LLMs) and extracting valuable insights from customer interaction data has become essential for enterprises. The ability to raise timely flags or obtain a summarized view of customer interactions is crucial for understanding customers better and delivering value. In this context, the use of ChatGPT demonstrates how LLMs can be applied to analyze sample transcripts and identify the key issues within a conversation or history.
By leveraging LLMs like ChatGPT, businesses can uncover patterns, trends, and recurring problems in customer interactions. This analysis enables enterprises to proactively address customer concerns, optimize support processes, and enhance the overall customer experience. The sample transcripts serve as a demonstration of how LLM-powered analysis can effectively identify the top problems and provide valuable insights that aid in understanding customers and delivering personalized solutions. The samples have been generated with the help of ChatGPT including a mix of positive and negative conversations.
To bring a proper structure to this application, we will make use of Langchain as the framework and Deeplake as the vector database where we store all the support data.
Let’s get started with the solution.
Install the dependencies
First, we will install the required dependencies using the below statement.
!pip install langchain deeplake openai tiktoken
Set up Deeplake
Deep Lake is a versatile platform that goes beyond embeddings to encompass various types of AI data. It seamlessly integrates the capabilities of Data Lakes and Vector Databases to create, refine, and implement advanced LLM (Language, Learning, and Memory) solutions for enterprises. With Deep Lake, organizations can continuously enhance these solutions and drive iterative improvements as they evolve over time.
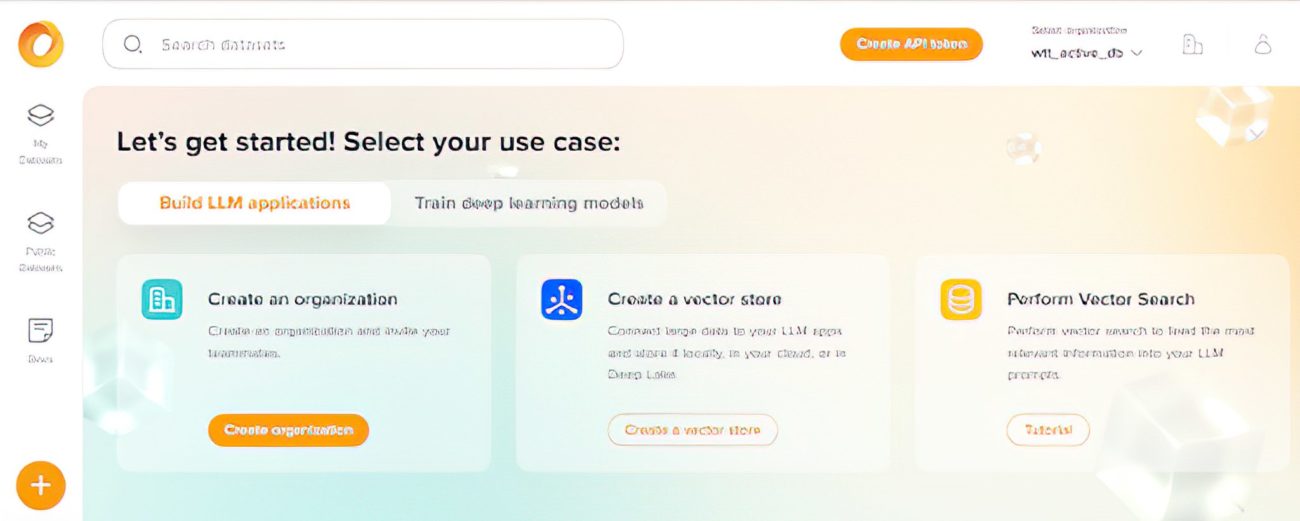
Sign up for Deeplake using Activeloop (https://app.activeloop.ai/) and create a default organization. Create an API key which you will be using in your code so keep it handy.
Also setup the expiration date based on your usage needs.
Import the dependencies
Get started with your jupyter notebook and import all the required dependencies.
Depending on the files you need to handle, you can use the required document loaders.
For embeddings and models, we would make use of Openai. For text splitting, we would use the RecursiveCharacterTextSplitter. For vector store, we would use Deeplake.
import os import getpass from langchain.document_loaders import PyPDFLoader, TextLoader from langchain.embeddings.openai import OpenAIEmbeddings from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter from langchain.vectorstores import DeepLake from langchain.chains import ConversationalRetrievalChain, RetrievalQA from langchain.chat_models import ChatOpenAI from langchain.llms import OpenAI
Setup your environment
Setup your environment parameters for OpenAI and Deeplake
os.environ['OPENAI_API_KEY'] = "YOUR OPENAI API KEY" os.environ['ACTIVELOOP_TOKEN'] = 'YOUR ACTIVELOOP TOKEN FOR DEEPLAKE' os.environ['ACTIVELOOP_ORG'] = 'YOUR ACTIVELOOP ORG'
Document loading and Chunking
We first Load the document using the text loader as we are using a txt transcript here. CharacterTextSplitter is used to chunk the transcripts by providing a reasonable chunk size. The RecursiveCharacterTextSplitter is further applied for chunking by keeping some overlap to have a continuation of context within chunks. This is the recommended one for generic text, as you would definitely have lots of data to chunk and process.
source_text = 'sample_data/message.txt'
dataset_path = 'hub://' + org + '/data'
with open(source_text) as f:
chat_logs = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
pages = text_splitter.split_text(chat_logs) text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100) texts = text_splitter.create_documents(pages) print (texts)
Adding Embeddings into Vectorstore
Next, we will embed chunks and add them to DeepLake.
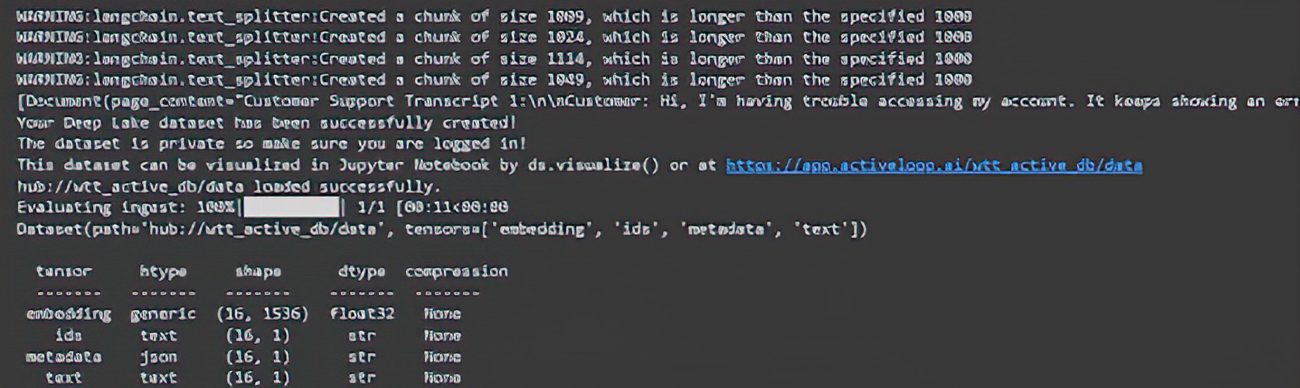
embeddings = OpenAIEmbeddings() db = DeepLake(dataset_path=dataset_path, embedding_function=embeddings, token=os.environ['ACTIVELOOP_TOKEN'], read_only=True) db.add_documents(texts)
By storing the dataset on Activeloop, you can conveniently retrieve it in the future without the need to recalculate embeddings. This feature offers a notable advantage as it saves both time and computational resources.
Set up the LangChain RetrieverQA Chain
LangChain provides a convenient wrapper around Deep Lake, enabling you to utilize it as a Vector Store, further enhancing its functionality. We will set up a retrieverQA chain to be able to connect to deeplake and extract the data related to the query and then pass it on to ChatGPT to give a proper response for the query using the data provided.
You can provide additional parameters to fetch data from the vectorstore by providing the similarity metric to be followed(cosine similarity in this case) and the top k(4) rows to be considered for the response.
retriever = db.as_retriever() retriever.search_kwargs['distance_metric'] = 'cos' retriever.search_kwargs['k'] = 4
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=False)
This gets processed and you see the following
With the link given, you can explore your vector data in deeplake. With a paid account, you can write queries on the data as shown below.
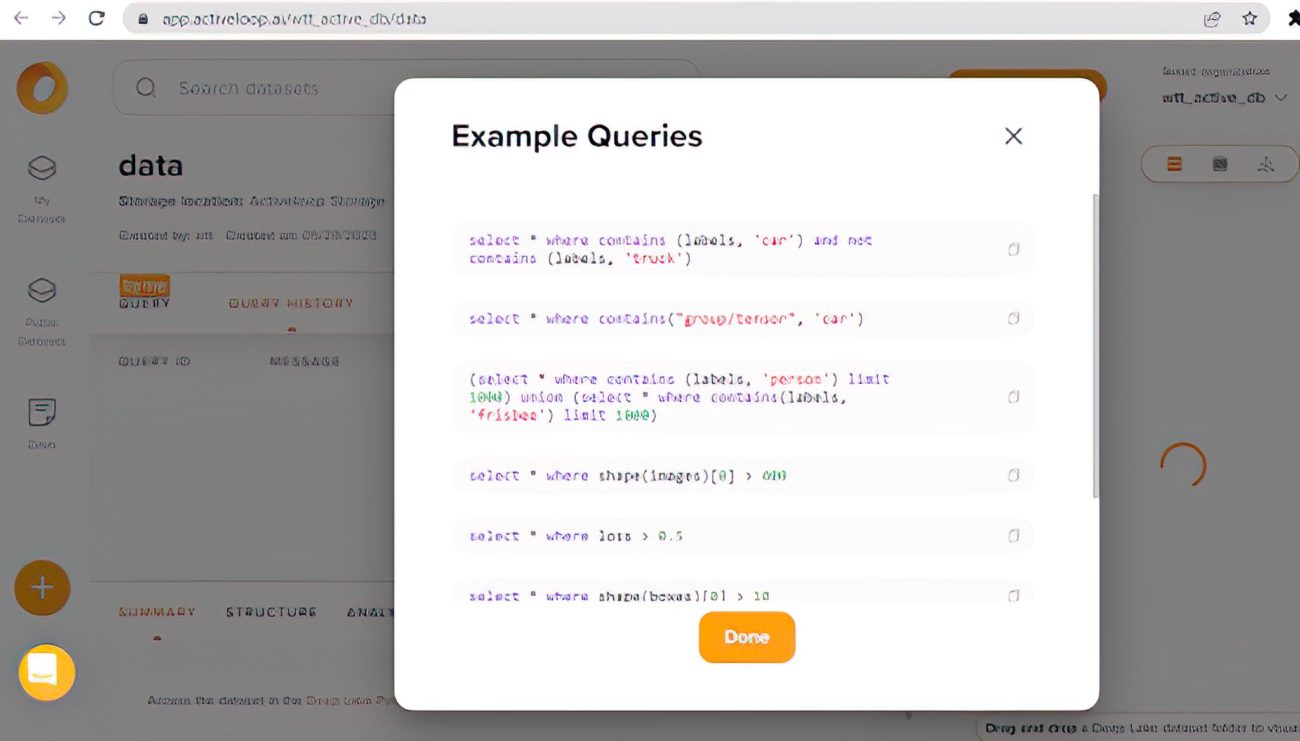
Shoot your query
Now you can start querying on your data. Below are some examples.

And the answer is:

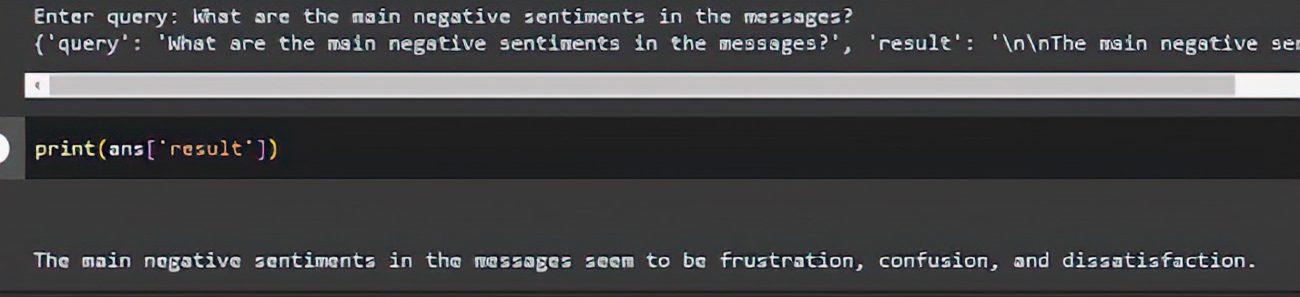
Now, we are all set to use this knowledge base to derive insights on customer engagement, customer behavior, customer issues, and much more. This logic can be further enhanced to extract more valuable insights and ask pointed questions.
Conclusion:
By harnessing the power of Langchain and Deeplake for customer support transcript analysis, businesses get the opportunity to enhance customer experience significantly. By leveraging advanced language models and efficient data storage, businesses can gain valuable insights, address customer needs more effectively, and make data-driven decisions. Embracing these technologies enables businesses to exceed customer expectations and thrive in the digital era.