Blogs
Advanced RAG Multi-Modal Techniques for Accurate Data Extraction
In the vast digital landscape, Portable Document Format (PDF) files have emerged as a ubiquitous medium for sharing and preserving information. From academic papers to business reports, PDFs encapsulate diverse content in a standardized and universally accessible format. While PDFs are renowned for their visual consistency across devices, extracting specific data, especially from tables within these documents, can often be a daunting task.
Another important aspect in this ever-evolving landscape of information technology is the ability to harness the power of Large Language Models (LLMs) by augmenting with accurate context to derive invaluable insights. However, the effectiveness of these models relies heavily on the quality and accuracy of the contextual data they receive. This blog delves into the pivotal role of extracting accurate information from PDF tables for Retrieval Augmented Generation, emphasizing its significance in ensuring LLMs provide correct and reliable answers.
In this blog post, we delve into the crucial use case of retrieving data from PDFs that contain tabular content. From discussing the various scenarios where this capability proves indispensable to exploring the importance of efficient data extraction, we aim to shed light on the significance of harnessing the potential hidden within PDF tables.
|Data retrieval Use Cases and scenarios
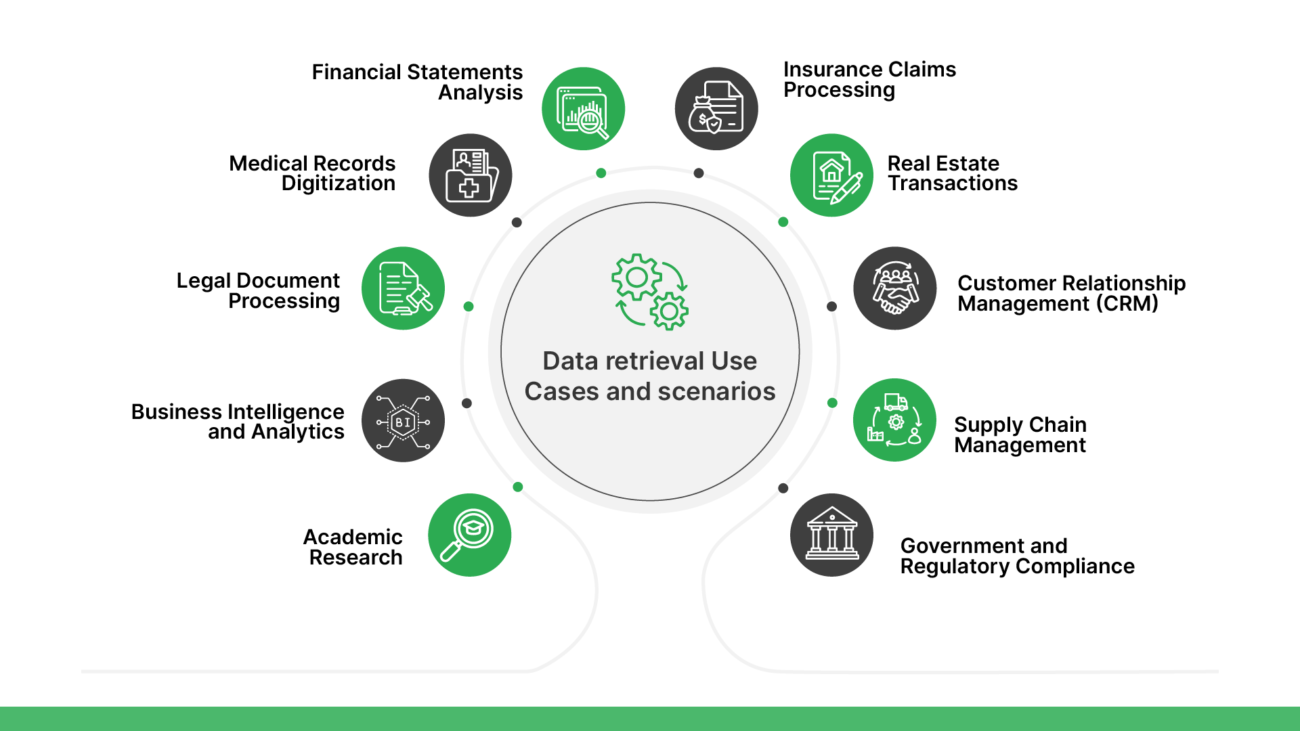
Data extraction from PDF files, including images and tabular data, becomes indispensable in several important use cases:
Financial Statements Analysis: Extracting data from financial reports, invoices, and statements enables financial analysts and accountants to perform comprehensive financial analysis, track expenses, and monitor financial performance accurately.
Medical Records Digitization: Converting medical records, lab reports, and patient charts from PDF format into structured data facilitates electronic health record (EHR) management, patient care coordination, and medical research.
Legal Document Processing: Extracting data from legal contracts, agreements, and court documents streamlines document review processes, enables keyword searching, and supports compliance with legal requirements.
Business Intelligence and Analytics: Extracting data from PDF reports, market research studies, and industry publications provides valuable insights for business decision-making, market trend analysis, and competitive intelligence.
Academic Research: Extracting data from scholarly articles, research papers, and academic journals supports literature reviews, citation analysis, and data aggregation for academic research and publication.
Insurance Claims Processing: Extracting data from insurance claim forms, policy documents, and medical records automates claims processing workflows, improves accuracy, and accelerates claim adjudication and settlement processes.
Real Estate Transactions: Extracting data from property listings, mortgage documents, and title deeds facilitates property valuation, market analysis, and real estate transaction management.
Customer Relationship Management (CRM): Extracting data from customer surveys, feedback forms, and contact lists enables businesses to analyze customer behavior, personalize marketing campaigns, and improve customer engagement and retention.
Supply Chain Management: Extracting data from shipping manifests, inventory reports, and purchase orders enhances supply chain visibility, inventory management, and demand forecasting for efficient supply chain operations.
Government and Regulatory Compliance: Extracting data from regulatory documents, compliance reports, and government publications helps organizations stay informed about regulatory changes, ensure compliance with industry standards, and mitigate legal risks.
Now that we have an overall understanding of different use cases, let’s shed some light on the importance of multimodal data retrieval.
|Importance of Multimodal data retrieval
Data extraction from PDF files offers several benefits that contribute to improved efficiency, accuracy, and decision-making across various industries and domains:
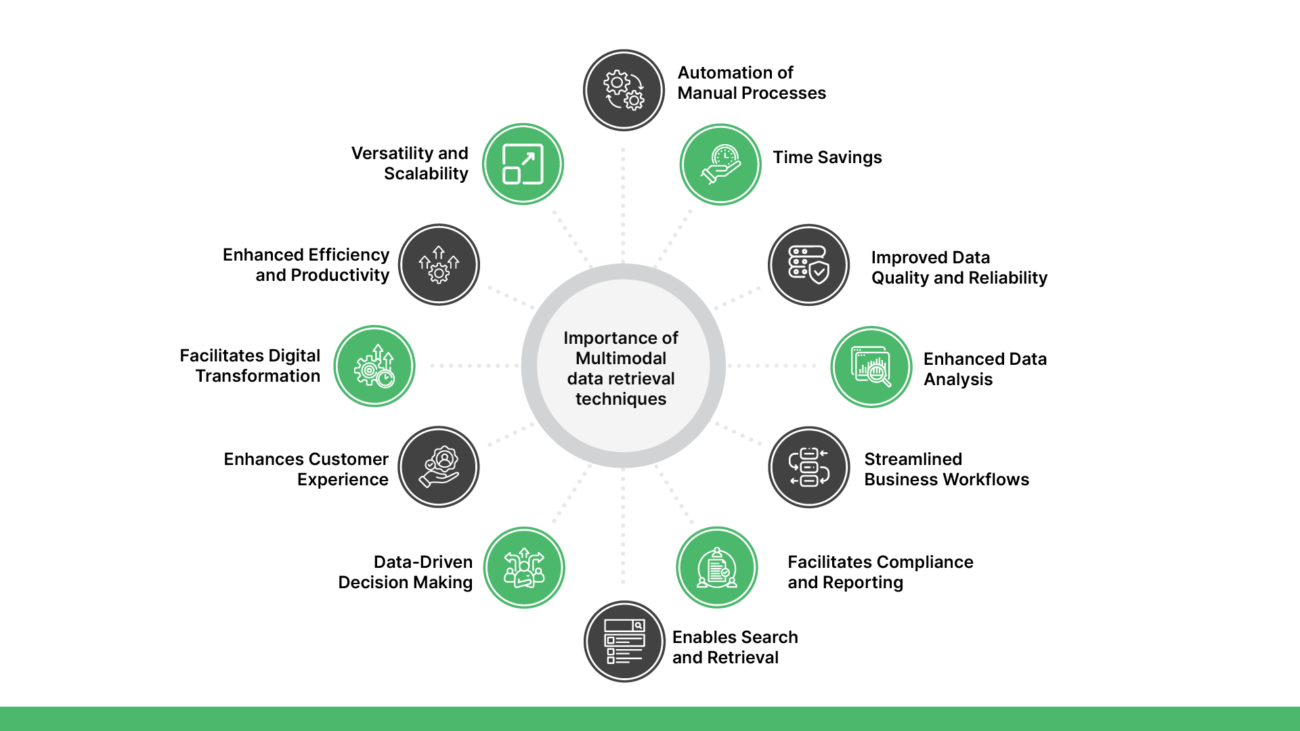 Automation of Manual Processes: Extracting data from PDF files automates manual data entry tasks, reducing the need for human intervention and minimizing the risk of errors associated with manual data entry.
Automation of Manual Processes: Extracting data from PDF files automates manual data entry tasks, reducing the need for human intervention and minimizing the risk of errors associated with manual data entry.
Time Savings: Automated data extraction from PDF files saves time compared to manual data entry methods, allowing organizations to reallocate resources to more strategic tasks and initiatives.
Improved Data Quality and Reliability: Automating multimodal data extraction minimizes errors and ensures consistent, reliable data for enhanced analysis and insights.
Enhanced Data Analysis: Extracted data from PDF files can be transformed into structured formats suitable for analysis using data analytics tools and techniques. This enables organizations to derive actionable insights, identify trends, and make informed decisions based on data-driven analysis.
Streamlined Business Workflows: Data extracted from PDF files can be integrated seamlessly into existing business systems, applications, and databases, streamlining business workflows and enhancing overall operational efficiency.
Facilitates Compliance and Reporting: Automated data extraction ensures consistency and accuracy in data reporting and compliance with regulatory requirements. Extracted data can be used to generate compliance reports, audit trails, and regulatory filings more efficiently.
Enables Search and Retrieval: Structured data extracted from PDF files enables easy search and retrieval of information, improving accessibility and usability of data for users across the organization.
Data-Driven Decision Making: Rapid data extraction from PDFs provides timely insights for informed decisions and supports data-backed strategies in dynamic environments.
Enhances Customer Experience: Streamlined data extraction processes enable organizations to respond to customer inquiries, process orders, and resolve issues more quickly and accurately, leading to improved customer satisfaction and loyalty.
Facilitates Digital Transformation: Data extraction from PDF files is a key component of digital transformation initiatives, enabling organizations to digitize and unlock valuable insights from unstructured data sources, such as scanned documents and image-based PDFs.
Enhanced Efficiency and Productivity: Automating table data extraction reduces manual labor, boosts productivity, and streamlines workflows for efficient data analysis and decision-making.
Versatility and Scalability: Modern multimodal extraction tools offer wide format compatibility and scalability, facilitating efficient data handling across industries and large datasets.
In this blog series, we will explore some of the most effective ways of using PDF data. In the current blog, we will make use of Multi-Modal extraction techniques in Retrieval Augmented Generation to achieve accurate results from a scanned PDF or PDF containing images with text.
Now we have a fair understanding of the importance of multimodal data retrieval. But how to get it going in a specific scenario? Let’s explain this in a step-by-step manner.
|Getting Started
The main prerequisites which will be used in this solution:
- Microsoft’s Table Transformer model which offers a promising solution for detecting tables within images.
- GPT4-V – The Open AI model with multi-modal capabilities.
- Llama-Index for orchestration and data-connectors.
- Other supporting libraries
Dependencies
!pip install llama-index qdrant_client pyMuPDF tools frontend git+https://github.com/openai/CLIP.git easyocr
Import the required libraries to get started with reading the PDF documents.
import matplotlib.pyplot as plt import matplotlib.patches as patches from matplotlib.patches import Patch import io from PIL import Image, ImageDraw import numpy as np import csv import pandas as pd from torchvision import transforms from transformers import AutoModelForObjectDetection import torch import openai import os import fitz device = "cuda" if torch.cuda.is_available() else "cpu" OPENAI_API_TOKEN = "sk-XXXXXXXXXXXXXXXXXXXXXX" openai.api_key = OPENAI_API_TOKEN
Define your model
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", api_key=OPENAI_API_TOKEN, max_new_tokens=1500
)
Load the pdf, extract the pages, and convert the pdf into images.
The pdf used for this blog is taken from https://legaldatalab.law.virginia.edu/hedge_funds/
pdf_file = "Investment_fund.pdf"
# Split the base name and extension
output_directory_path, _ = os.path.splitext(pdf_file)
if not os.path.exists(output_directory_path):
os.makedirs(output_directory_path)
# Open the PDF file
pdf_document = fitz.open(pdf_file)
# Iterate through each page and convert to an image
for page_number in range(pdf_document.page_count):
# Get the page
page = pdf_document[page_number]
# Convert the page to an image
pix = page.get_pixmap()
# Create a Pillow Image object from the pixmap
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
# Save the image
image.save(f"./{output_directory_path}/page_{page_number + 1}.png")
# Close the PDF file
pdf_document.close()
This creates a subfolder with the name of the file and saves all the images here.
View the extracted images created under a folder of the name of the pdf document.
from PIL import Image
import matplotlib.pyplot as plt
import os
image_paths = []
for img_path in os.listdir("./observe"):
image_paths.append(str(os.path.join("./observe", img_path)))
def plot_images(image_paths):
images_shown = 0
plt.figure(figsize=(16, 9))
for img_path in image_paths:
if os.path.isfile(img_path):
image = Image.open(img_path)
plt.subplot(3, 3, images_shown + 1)
plt.imshow(image)
plt.xticks([])
plt.yticks([])
images_shown += 1
if images_shown >= 9:
break
plot_images(image_paths[0:3])

Using Microsoft’s Table Transformer to crop tables from the images and use the cropped data to get the required information.
class MaxResize(object):
def __init__(self, max_size=800):
self.max_size = max_size
def __call__(self, image):
width, height = image.size
current_max_size = max(width, height)
scale = self.max_size / current_max_size
resized_image = image.resize(
(int(round(scale * width)), int(round(scale * height)))
)
return resized_image
detection_transform = transforms.Compose(
[
MaxResize(800),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
structure_transform = transforms.Compose(
[
MaxResize(1000),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
# load table detection model
# processor = TableTransformerImageProcessor(max_size=800)
model = AutoModelForObjectDetection.from_pretrained(
"microsoft/table-transformer-detection", revision="no_timm"
).to(device)
# load table structure recognition model
# structure_processor = TableTransformerImageProcessor(max_size=1000)
structure_model = AutoModelForObjectDetection.from_pretrained(
"microsoft/table-transformer-structure-recognition-v1.1-all"
).to(device)
# for output bounding box post-processing
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(-1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
width, height = size
boxes = box_cxcywh_to_xyxy(out_bbox)
boxes = boxes * torch.tensor(
[width, height, width, height], dtype=torch.float32
)
return boxes
def outputs_to_objects(outputs, img_size, id2label):
m = outputs.logits.softmax(-1).max(-1)
pred_labels = list(m.indices.detach().cpu().numpy())[0]
pred_scores = list(m.values.detach().cpu().numpy())[0]
pred_bboxes = outputs["pred_boxes"].detach().cpu()[0]
pred_bboxes = [
elem.tolist() for elem in rescale_bboxes(pred_bboxes, img_size)
]
objects = []
for label, score, bbox in zip(pred_labels, pred_scores, pred_bboxes):
class_label = id2label[int(label)]
if not class_label == "no object":
objects.append(
{
"label": class_label,
"score": float(score),
"bbox": [float(elem) for elem in bbox],
}
)
return objects
def detect_and_crop_save_table(
file_path, cropped_table_directory="./table_images/"
):
image = Image.open(file_path)
filename, _ = os.path.splitext(file_path.split("/")[-1])
if not os.path.exists(cropped_table_directory):
os.makedirs(cropped_table_directory)
# prepare image for the model
# pixel_values = processor(image, return_tensors="pt").pixel_values
pixel_values = detection_transform(image).unsqueeze(0).to(device)
# forward pass
with torch.no_grad():
outputs = model(pixel_values)
# postprocess to get detected tables
id2label = model.config.id2label
id2label[len(model.config.id2label)] = "no object"
detected_tables = outputs_to_objects(outputs, image.size, id2label)
print(f"number of tables detected {len(detected_tables)}")
for idx in range(len(detected_tables)):
# # crop detected table out of image
cropped_table = image.crop(detected_tables[idx]["bbox"])
cropped_table.save(f"./{cropped_table_directory}/{filename}_{idx}.png")
def plot_images(image_paths):
images_shown = 0
plt.figure(figsize=(16, 9))
for img_path in image_paths:
if os.path.isfile(img_path):
image = Image.open(img_path)
plt.subplot(2, 3, images_shown + 1)
plt.imshow(image)
plt.xticks([])
plt.yticks([])
images_shown += 1
if images_shown >= 9:
break
Crop and extract tabular data from each page.
for file_path in image_paths:
detect_and_crop_save_table(file_path)
Now load the cropped data using SimpleDirectoryReader.
from llama_index import (
ServiceContext,
SimpleDirectoryReader,
)
# Read the cropped tables
image_documents = SimpleDirectoryReader("./table_images/").load_data()
Now your data is ready. Start asking your questions.
response = openai_mm_llm.complete(
prompt="Summarise the Amendments to Partnership Agreement and give the section number",
image_documents=image_documents,
)
print(response)
The response:
The images provided appear to be pages from a Partnership Agreement document, which outlines the terms, conditions, and various provisions related to the operation of a partnership. The document includes amendments and restatements effective as of April 1, 2004. Here is a summary of the key sections and amendments based on the images provided:
- **Capital Contributions (Section 2.01)**: This section likely details the initial contributions made by the partners to the partnership.
- **Allocation of Profits and Losses (Section 3.03)**: This section describes how profits and losses are to be allocated among the partners.
- **Economic Allocations (Section 3.08)**: This section specifies how net gains or losses are allocated among the partners for tax purposes.
- **Adjustment of Basis of Partnership Property (Section 3.10)**: This section addresses the adjustment of the tax basis of partnership property upon the transfer of a partnership interest or other specified events.
- **Taxes Withheld (Section 3.11)**: This section outlines the responsibilities for withholding taxes from distributions to partners.
- **Independent Auditors (Section 8.01)**: This section mandates that the partnership’s books of account and records be audited annually by an independent certified public accountant.
- **General Provisions (Section 9.01 – 9.10)**: These sections cover various general provisions, including amendments to the partnership agreement, powers of attorney, tax matters, and the entire agreement clause.
- **Index of Defined Terms**: An index is provided to define specific terms used throughout the agreement
- **Amendments to Partnership Agreement**: While specific amendments are not detailed in the images, the document mentions that it has been amended and restated, indicating that changes have been made to the original agreement.
The section numbers are provided next to the titles of each section in the images, and they correspond to the detailed provisions within the agreement. The document is structured to cover all aspects of the partnership’s operation, including financial matters, partner responsibilities, and legal compliance.
Please note that the images do not provide the complete text of each section, so this summary is based on the section titles and partial content visible in the images. For a comprehensive understanding of the amendments and the agreement as a whole, one would need to review the full document.
response = openai_mm_llm.complete(
prompt="What is title of Section 9.03?",
image_documents=image_documents,
)
print(response)
Section 9.03 is titled "Amendment of Partnership Agreement."
This approach is useful when the PDF comprises images and tables from which we need to extract details needed for analysis.
|Conclusion
Advanced RAG techniques, coupled with multi-modal capabilities, empower professionals across various domains to unlock the potential hidden within these documents. By automating data extraction, this approach streamlines workflows, enhances data quality, and facilitates data-driven decision-making.
Our in-house document parsing solution Intellexi can extract structured and unstructured data from different types of documents.