Blogs
Orchestrating Pipelines using MLOps Workload Orchestrator

In our previous blogs, we discussed SageMaker Pipelines, their different implementations [1] and the benefits [2] of using SageMaker Project Templates for workflow automation.
In this blog, we discuss how to provision different kinds of pipelines using a different AWS MLOps framework – the Workload Orchestrator.
The blog is organized as follows:
- Introduction
- Types of Implementation
- Architecture Overview
- Pipelines supported by the Orchestrator
- Provisioning the Pipelines: Illustration
- Comparison with SageMaker Project Templates
- Conclusion
Introduction
MLOps Workload Orchestrator is the AWS’s Solutions Implementation for MLOps.
The Orchestrator can be used to provision a pipeline of one’s choice, based on the configuration one provides. It currently supports pipelines for image creation, model deployment and monitoring.
Types of Implementation
There are two kinds of implementation of the Orchestrator.
1. Single Account : This deploys all pipelines provided by the Solution in the same account.
2. Multi-Account : This helps provision multiple environments (development, staging and production) across different AWS accounts.
In this blog, we will discuss the Single Account Implementation of the Workload Orchestrator.
Architecture Overview
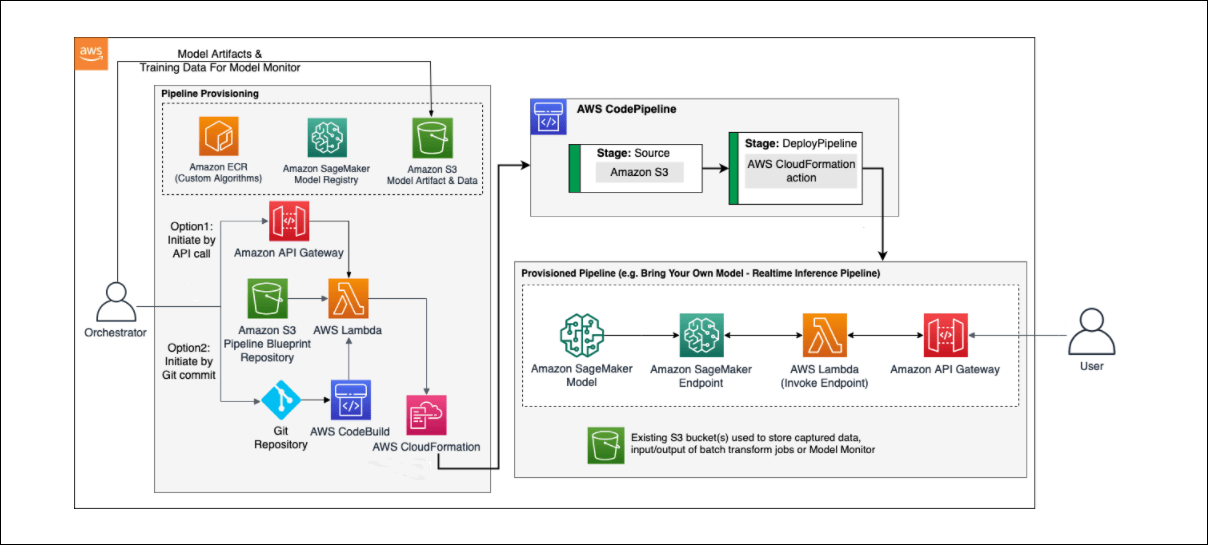 The deployment/inference/monitoring of a model through the Orchestrator involves three steps :
The deployment/inference/monitoring of a model through the Orchestrator involves three steps :
1. Uploading the model to be deployed/monitored (BYOM)
- The model to be deployed is uploaded in the Assets S3 bucket.
- While deploying the Orchestrator component, we can specify a bucket of our choice as the Assets bucket.
- If no bucket is specified, the Orchestrator creates an S3 bucket for uploading of assets to be deployed.
2. Invoking the Orchestrator to generate and deploy the desired pipeline through AWS CodePipeline
- The user invokes AWS CodePipeline to deploy the desired pipeline either by :
- Calling the solution’s Amazon API Gateway.
- Committing the configuration file into an AWS CodeCommit repository
- Based on the kind of pipeline requested by the user, the corresponding template is chosen from the Amazon S3 Pipeline BluePrint Repository. This repository gets generated when the Orchestrator solution is deployed.
- The model gets deployed as a SageMaker Model, and an API is created to point to the endpoint.
3. Storing captured data, input/output of batch transform jobs and Model Monitor
- An S3 bucket is provisioned for the same in the API call or the mlops-config.json as the case may be.
- The S3 bucket can be a different bucket or it may be the same as the Assets Bucket.
- The key is specified along with the bucket name as the input to the JSON.
Pipelines supported by the Orchestrator
- BYOM Real-time Inference Pipeline using Amazon SageMaker Built-in Algorithm
- BYOM Real-time Inference Pipeline using Custom Algorithm
- BYOM Batch Transform Pipeline using Amazon SageMaker Built-in Algorithm
- BYOM Batch Transform Pipeline using Custom Algorithm
- Custom Algorithm Image Builder Pipeline
- Data Quality Monitor Pipeline
- Model Quality Monitor Pipeline
- Model Bias Monitor Pipeline
- Model Explainability Monitor Pipeline
In this blog, the focus will be on model deployment and image building pipelines. The monitoring pipelines will be discussed in our next blog.
Provisioning the Pipelines: Illustration
To provision a pipeline, we first need to deploy the Orchestrator, and then make a POST call to the /provisionpipeline endpoint of the API Gateway.
Deploying the Orchestrator
1. Click this to start the deployment using AWS Cloud Console.
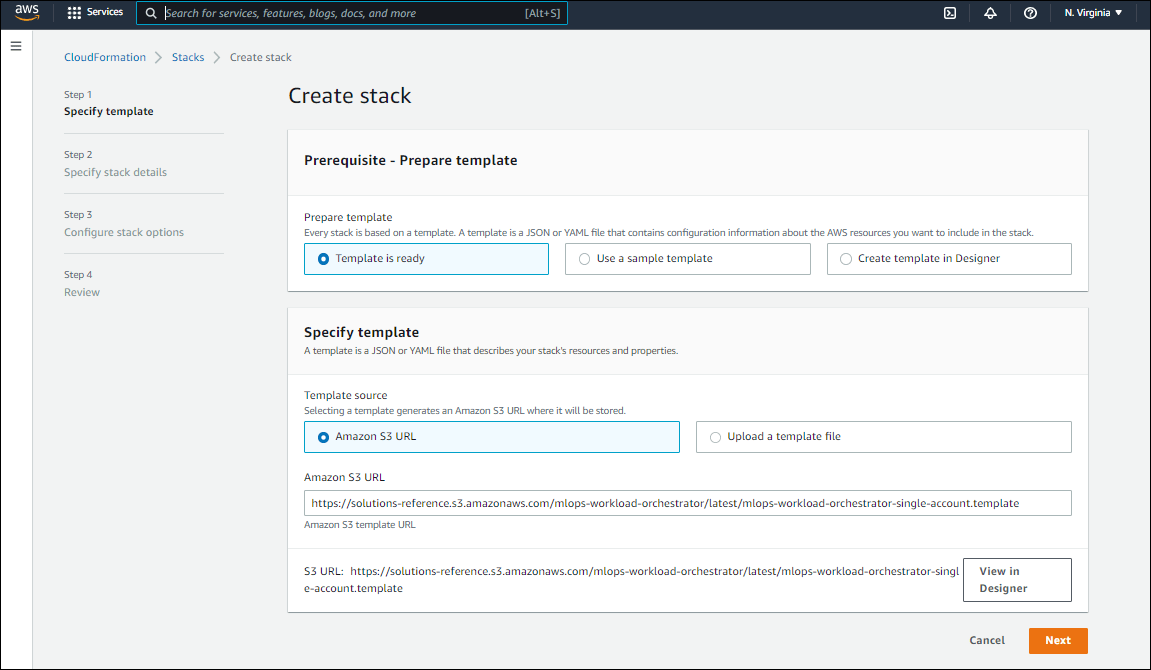
2. Click ‘Next’ and fill in the various options that appear in the next link .
- Provide a name of your choice as the Stack name. The name chosen in this case is ‘mlops-workload’.
- Provide a Notification Email. This is a required field. The pipeline related notifications will be received at this mail.
- Provide the CodeCommit Repo URL Address (Optional). This will be used to connect to the AWS framework.
- Mention the S3 bucket (Assets Bucket) that you are using to store the artifacts (models, dockerfiles, etc). As specified, this bucket should be in the same AWS region as the one where the stack is getting deployed, and should have versioning enabled. If no bucket is provided, a new S3 bucket will be provisioned.
- Provide the name of an existing Amazon ECR repository for custom algorithms. If not specified, a new ECR repo will be created.
- Specify whether you would want to use the SageMaker Model Registry (as opposed to uploading models in the Assets Bucket).
- If you want the solution to create a Model Registry, specify ‘Yes’, else you can use a repository of your choice.
- Specify ‘Yes’ to allow detailed error messages in the API response. This allows inclusion of any detailed message of any server-side errors in the API call’s response
(For the purpose of this blog, the stack name used is ‘mlops-workload’ and the default options are chosen.
This will lead to creation of a new Assets bucket, where the model and docker artifacts will be placed and sourced from.)
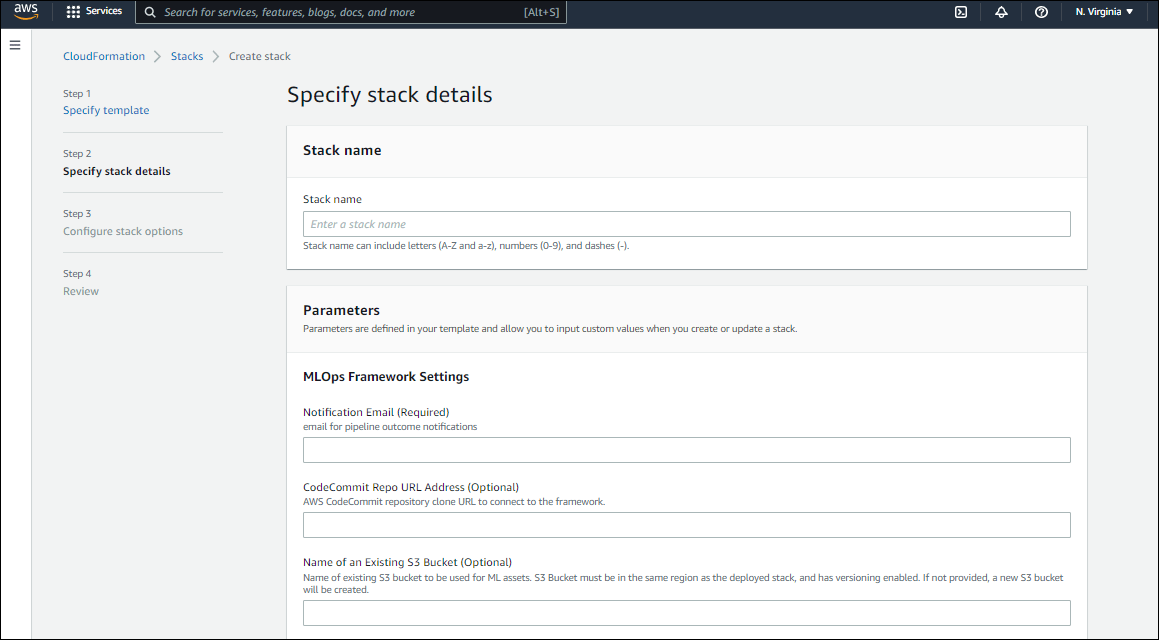
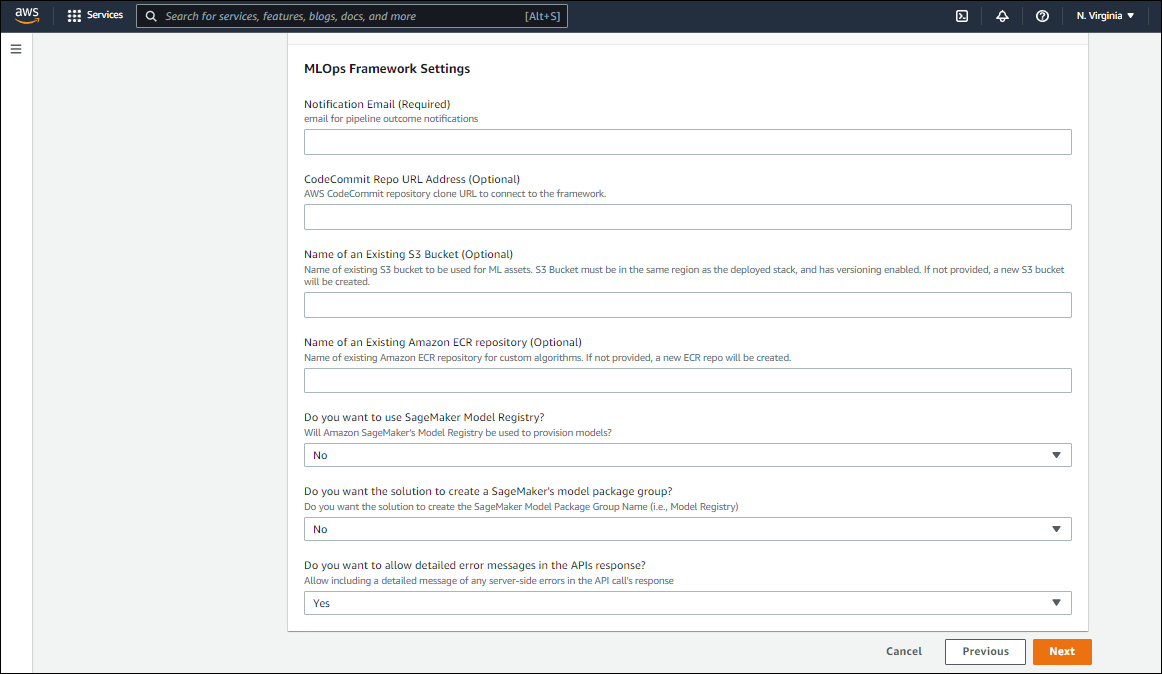
- Click ‘Next’.
- Keep the default options in the ‘Configure stack options’ and click ‘Next’.

- On the Review Stack page, under the Capabilities section, check in ‘I acknowledge that AWS CloudFormation might create IAM resources.’ and choose ‘Create Stack’.
The following assets get created once the Stack gets ready.

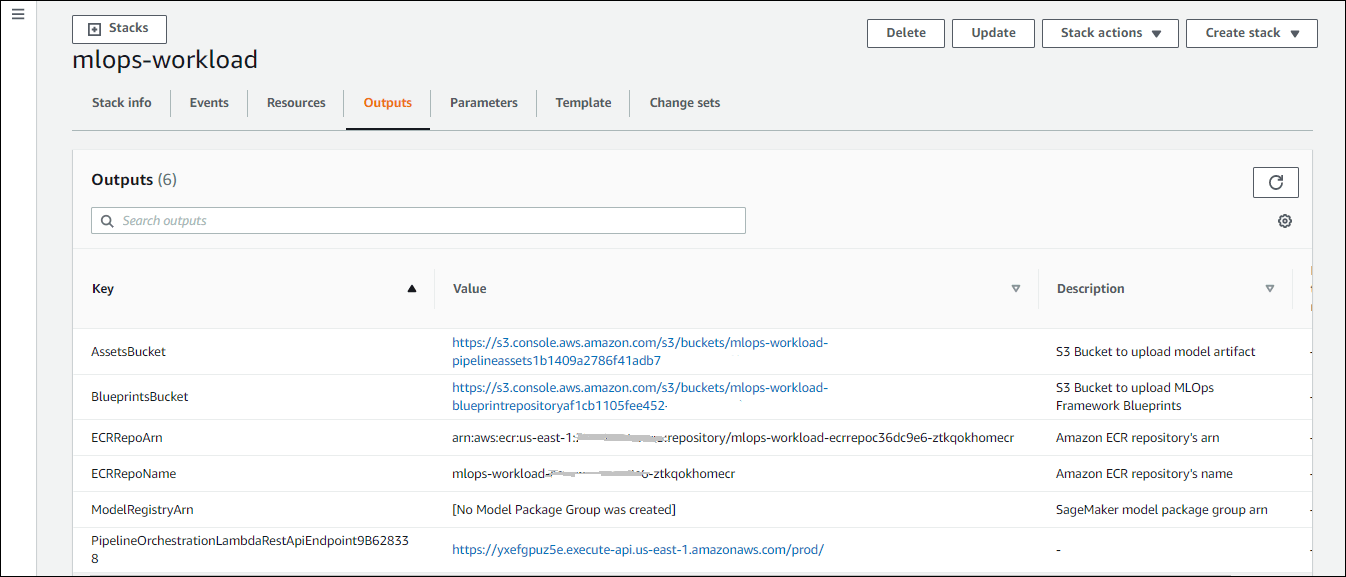
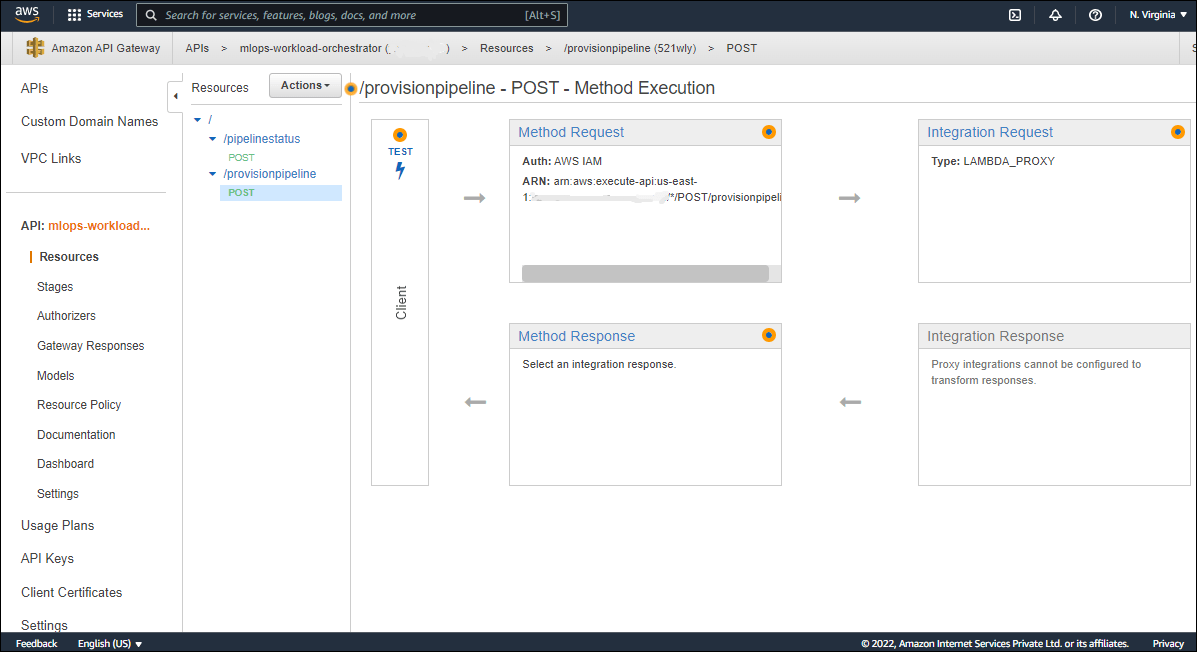
Once the deployment is done, we have an API created for the Orchestrator, available in the Amazon API Gateway.
This creates two API endpoints – pipelinestatus and provisionpipeline, both of which can be invoked using the POST method.

Invoking AWS CodePipeline through API Gateway
To invoke a pipeline of your choice, click on ‘POST’ under /provisionpipeline, and then on ‘Test’.
This shows the Request Body using which we can make a call to the API. The call will be made using a JSON object which specifies the various attributes required for the pipeline, as discussed next.

Required Attributes per Pipeline Type
Depending on the kind of pipeline required, we need to pass the relevant parameters to the JSON. The parameters are detailed below, along with the specific ones required for each pipeline type.
REQUIRED PIPELINE ATTRIBUTES
| pipeline_type | Type of the pipeline to provisionReal-time inference with SageMaker Built-in Algorithms byom_realtime_builtin
Real-time inference with Custom Algorithms byom_realtime_custom Batch transform with SageMaker Built-in Algorithms byom_batch_builtin Batch transform with Custom Algorithms byom_batch_custom Custom Algorithm Docker Image byom_image_builder |
| custom_algorithm_docker | Path to a zip file inside Assets Bucket, containing the necessary files (for example, Dockerfile, assets, etc.) to create a Docker image that can be used by Amazon SageMaker to deploy a model trained using the custom algorithm. |
| custom_image_uri | URI of a custom algorithm image in an Amazon ECR repository |
| ecr_repo_name | Name of an Amazon ECR repository where the custom algorithm image, created by the byom_image_builder pipeline, will be stored. |
| image_tag | custom algorithm’s image tag to assign to the created image using the byom_image_builder pipeline. |
| model_framework | Name of the built-in algorithm used to train the model. |
| model_framework_version | Version number of the built-in algorithm used to train the model. |
| model_name | Arbitrary model name for the deploying model. The model, endpoint and associated configuration is created with extensions of this name. |
| model_artifact_location | Path to a file in Assets Bucket containing the model artifact file (the output file after training a model). |
| model_package_name | Amazon SageMaker model package name (e.g.,” arn:aws:sagemaker:<region>:<account_id>:model-package/<model_package_group_name> /<model_version>”). |
| inference_instance | Instance type for inference (real-time or batch) |
| data_capture_location | Path to a prefix in an S3 Bucket (including the bucket’s name, for example <bucket-name>/<prefix>) to store the data captured by the real-time Amazon SageMaker inference endpoint. |
| batch_inference_data | Path to a file in an S3 Bucket (including the bucket’s name, for example <bucket-name>/<path-to-file>) containing the data for batch inference. This parameter is not required if your inference type is set to real-time. |
| batch_job_output_location | Path to a prefix in an S3 Bucket (including the bucket’s name, for example <bucket-name>/<prefix>) to store the output of the batch transform job. |
The exact parameters required for each pipeline type are detailed below.
Inference with an Amazon SageMaker Built-in Model
| Real-time | Batch |
|---|---|
| {“pipeline_type” : “byom_realtime_builtin“,
“model_framework“: “xgboost“, “model_framework_version“: “1“, “model_name“: “my-model-name“, “model_artifact_location“: “path/to/model.tar.gz“, “data_capture_location“: “<bucket-name>/<prefix>“, “inference_instance“: “ml.m5.large“, “endpoint_name“: “custom-endpoint-name“ } |
{ “pipeline_type” : “byom_batch_builtin“,
“model_framework“: “xgboost“, “model_framework_version“: “1“, “model_name“: “my-model-name“, “model_artifact_location“: “path/to/model.tar.gz“, “inference_instance“: “ml.m5.large“, “batch_inference_data“: “<bucket-name>/<prefix>/inference_data.csv“, “batch_job_output_location“: “<bucket-name>/<prefix>“ } |
Inference with a Custom Algorithm for a Machine Learning Model
| Real-time | Batch |
|---|---|
| { “pipeline_type” : “byom_realtime_custom“,
“custom_image_uri“: “docker-image-uri-in-Amazon-ECR-repo“, “model_name“: “my-model-name“ “model_artifact_location“: “path/to/model.tar.gz“, “data_capture_location“: “<bucket-name>/<prefix>“, “inference_instance“: “ml.m5.large“, “endpoint_name“: “custom-endpoint-name“ } |
{“pipeline_type” : “byom_batch_custom“,
“custom_image_uri“: “docker-image-uri-in-Amazon-ECR-repo“, “model_name“: “my-model-name“, “model_artifact_location“: “path/to/model.tar.gz“, “inference_instance“: “ml.m5.large“, “batch_inference_data“: “<bucket-name>/<prefix>/inference_data.csv“, “batch_job_output_location“: “<bucket-name>/<prefix>“ } |
Custom Algorithm Image Builder Pipeline
| { “pipeline_type“: “byom_image_builder“,
“custom_algorithm_docker“: “path/to/custom_image.zip“, “ecr_repo_name“: “name-of-Amazon-ECR-repository“, “image_tag“: “image-tag“ } |
The demonstration of the pipelines in this blog is done using the following models and docker artifact :
1. Salary Predictor based on Years of Experience :
The linear learner model is used to demonstrate real-time and batch inference for the built-in model algorithm scenario.
The trained model is available here.
2. Customer Churn Predictor :
This uses a custom xgboost image and is used to demonstrate real-time and batch inference for the custom algorithm scenario.
The trained model is available here.
3. Dockerfile – This takes a tensorflow base image and installs tensorflow-model-server on top of it.
These artifacts are stored in the Assets S3 bucket under the models and the model-artifacts folders.
The actual JSONs with which the POST method is called for the different use cases, are shown below.
Another S3 bucket (inference-data-mlops) is provided here to store the data captured by the real-time endpoint, and to store the input and output of the batch processing job.
Inference with an Amazon SageMaker Built-in Model
| Real-time | Batch |
|---|---|
| {” pipeline_type” : “byom_realtime_builtin“,
“model_framework“: “linear-learner“, “model_framework_version“: “1“, “model_name“: “linear-learner-realtime“, “model_artifact_location“: “models/linear_learner.tar.gz“, “data_capture_location“: “inference-data-mlops/linear-learner-datacapture“, “inference_instance“: “ml.m5.large“, “endpoint_name“: “linear-learner“ } |
{ “pipeline_type” : “byom_batch_builtin“,
“model_framework“: “linear-learner“, “model_framework_version“: “1“, “model_name“: “linear-model-batch“, “model_artifact_location“: “models/linear_learner.tar.gz“, “inference_instance“: “ml.m5.large“, “batch_inference_data“: “<inference-data-mlops/input-data/salary.csv“, “batch_job_output_location“: “inference-data-mlops/output“ } |
Inference with a Custom Algorithm for a Machine Learning Model
| Real-time | Batch |
|---|---|
| { “pipeline_type” : “byom_realtime_custom“,
“custom_image_uri“: “683313688378.dkr.ecr.us-east-1.amazonaws.com/sagemaker-xgboost:0.90-1-cpu-py3“, “model_name“: “churn-prediction-realtime“ “model_artifact_location“: “models/churn-prediction.tar.gz“, “data_capture_location“: “inference-data-mlops/churn-datacapture“, “inference_instance“: “ml.m5.large“, “endpoint_name“: “churn-predictor“ } |
{“pipeline_type” : “byom_batch_custom“,
“custom_image_uri“: “683313688378.dkr.ecr.us-east-1.amazonaws.com/sagemaker-xgboost:0.90-1-cpu-py3“, “model_name“: “churn-prediction-batch“, “model_artifact_location“: “models/churn-prediction.tar.gz“, “inference_instance“: “ml.m5.large“, “batch_inference_data“: “inference-data-mlops/input-data/churn-dataset.csv“, “batch_job_output_location“: “inference-data-mlops/output“ } |
Custom Algorithm Image Builder Pipeline
| {
“pipeline_type“: “byom_image_builder“, “custom_algorithm_docker“: “docker-artifacts/custom-image.zip“, “ecr_repo_name“: “mlops-workload-ecrrepoc36dc9e6-upugqnnju0mi“, “image_tag“: “latest“ }
|
Each of these json files is passed as an input to the POST call, and the corresponding pipeline starts getting provisioned as shown below.
Real Time Inference with Built-in-Algorithm

Batch Inference with Built-In Algorithm

Real-Time Inference with Custom Algorithm
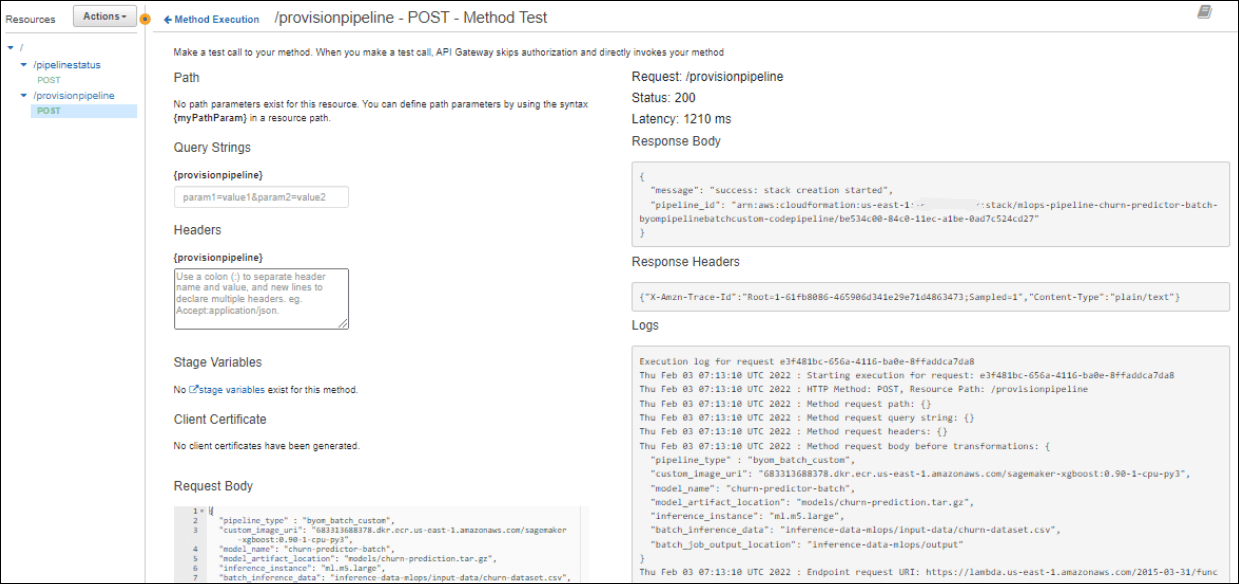
Batch Inference with Custom Algorithm
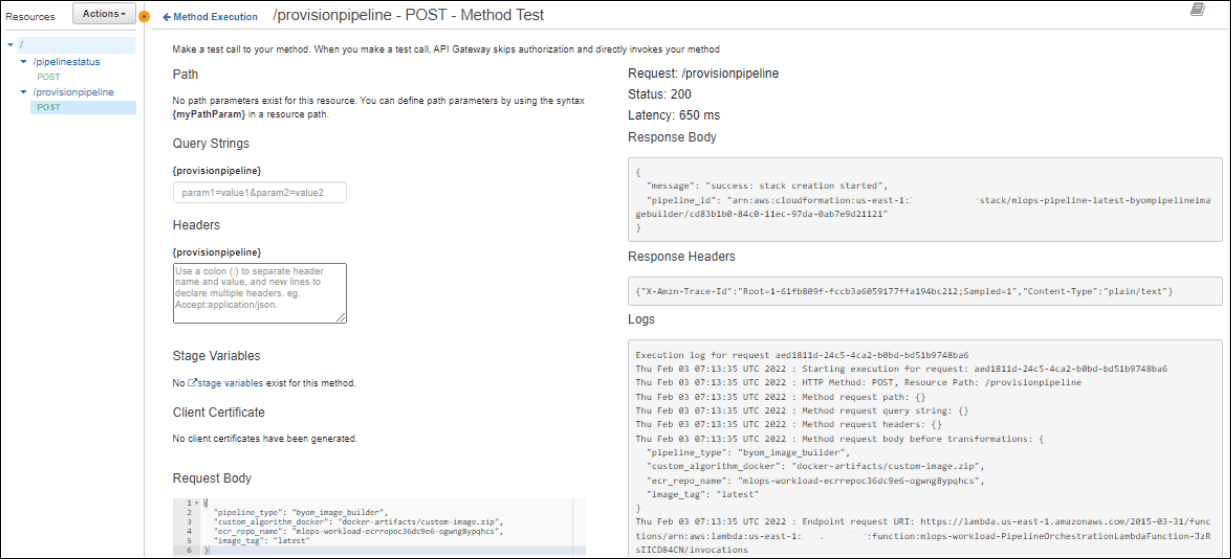
Custom Docker Image with Docker Artifact
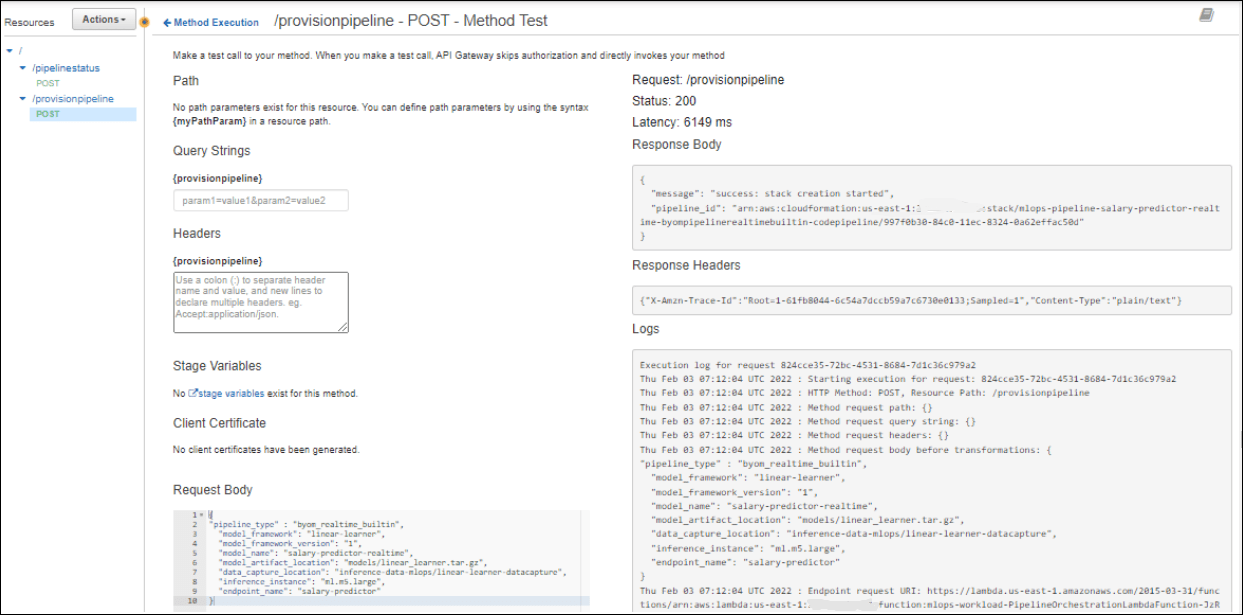
This creates the Stacks which then generate the pipelines.

Comparison with SageMaker Project Templates
SageMaker Project Templates provide an end-to-end MLOps solution, which includes a code repository (AWS CodeCommit or third-party Git repositories such as GitHub and Bitbucket), a CI/CD workflow automation tool (AWS CodePipeline or Jenkins) and different pipeline stages (for model building, training, deployment and monitoring). This is a better approach when the focus is on designing an end-to-end MLOps platform.
The Workload Orchestrator is not a good choice for this scenario for the following reasons:
- Different pipelines will have to be provisioned independently, and then connected to work as part of an integrated solution.
- The Orchestrator currently supports only image building, model deployment and monitoring pipelines. This will need to be extended to support model training.
On the other hand, if the requirement is to only to build a docker image or deploy a pre-trained model for real time or batch inference, it is better to do the same using the specific pipeline provisioned by the Orchestrator, rather than going for an end-to-end MLOps Project Template, which includes more resources than required for this.
Conclusion
The Workload Orchestrator is a powerful tool which can be used to provision the kind of pipelines we want. In this blog, we demonstrate how to deploy the Orchestrator, the different kinds of resources used by the Orchestrator, and pipeline provisioning for model deployment and docker file creation. We also compared its relative pros and cons vis-a-vis SageMaker Project Templates.