Blogs
Best Practices in CI/CD for optimizing SDLC – Part II


This is the second part of our DevOps Best Practices blog series.
In the first part, we focussed on how all project assets have to be under a single source control, how artifacts move within pipelines, how development should happen in short-lived branches, and how builds can be performed through the pipeline with one click. We also elaborated on the pace and hygiene of automated tests, their ability to run concurrently with multiple test suites, while ensuring everything is continuously scanned for security issues.
In this concluding part, we will elaborate on the best practices that, when adopted with those from the previous blog, will maximize DevOps success.
1. Quality scanning/Code reviews are part of the process
Code scans, like security scans, should be part of every developer’s day-to-day operations. This includes the following:
- Static analysis of code for company-approved style/formatting
- Static analysis of code for security problems, hidden threats
- Runtime analysis of code for errors and other issues
While there are tools that can perform the analytical component, not all businesses use them in an automated manner. A recurring pattern we find is eager development teams promising to employ these tools (e.g. Sonarqube) for the next project, only to forget about them or entirely ignore the warnings and errors shown in the analysis reports after some time has passed.
Code quality scanning, like security checks, should be a part of the Pull Request process. You should enforce excellent quality practices by prohibiting merges if a particular number of warnings is present, rather than merely presenting the final findings to developers.
2. Database updates are automated & have their updated lifecycle
As more businesses implement continuous delivery, we’re seeing a worrying trend of treating databases as if they’re separate from the delivery process. This could not be more untrue.
Databases (along with other supporting systems like message queues, caches, and service discovery solutions, among others) should be treated as any other software project. This refers to:
- Version control should be used to keep track of their setup and content.
- Version control should also include all associated scripts, maintenance tasks, and upgrade/downgrade instructions.
- Configuration modifications, like any other software update, should be approved (passing from automated analysis, pull request review, security scanning, unit testing, etc.)
- Each new version of the database should be installed, upgraded, and rolled back using dedicated pipelines.
The last point is particularly crucial. Many programming frameworks (e.g., rails migrations, Java Liquibase, ORM migrations) allow the application to manage DB migrations on its own. When the program starts up for the first time, it may usually upgrade the associated database to the correct schema. This method, while convenient, makes rollbacks extremely complex and should be avoided.
Database migration should be treated as if it were a standalone software upgrade. You should have database-only automated pipelines, and application pipelines should not interact with the database in any way. This will give you the most freedom when it comes to database upgrades and rollbacks because you’ll be able to decide when and how they happen.
Several firms have excellent application code pipelines, but they pay little attention to database update automation. Database management should be given the same (if not greater) priority as the application itself.
This means that databases should be automated in the same way that application code is:
- Changesets from databases should be kept in source control.
- Create pipelines that automatically update your database whenever a new changeset is created.
- Create dynamic temporary environments for databases where changesets are reviewed before being merged.
- On database changesets, conduct code reviews and other quality tests.
- Have a plan in place for reverting to a previous state if a database upgrade fails.
It also helps if you automate the transfer of production data into test data, which you can use in your application code’s test environments. In most circumstances, keeping a copy of all production data in test environments is inefficient (or even impossible owing to security constraints). It is preferable to have a limited subset of anonymized/simplified data that can be processed more quickly.
3. Database updates are forward and backward compatible
Application rollbacks are well understood, and we now have specific tools for doing rollbacks following a botched application deployment. We can reduce downtime even more by using progressive delivery approaches like canaries and blue/green deployments.
Because of the inherent condition of databases, progressive delivery strategies do not work, but we may plan database upgrades and employ evolutionary database design concepts.
You can make all your database changesets backwards and forwards compatible by following an evolutionary design, allowing you to rollback application and database changes at any moment with no bad effects.
If you wish to rename a column, for example, instead of simply generating a changeset that renames the column and completing a single database upgrade, you should instead follow the steps below:
- Only adds a new column with the new name to a database changeset (and copies existing data from the old column). The old column is still being written/read by the application code.
- The application code now writes to both columns, but reads from the new column, as part of an upgrade.
- When upgrading an application, make sure that the application code only writes/reads to the new column.
- The old column is removed as part of a database upgrade.
Because each database modification spans multiple deployments, the procedure necessitates a well-organized team. However, the benefits of this method cannot be emphasized. You can go back to the previous version at any point during the process without losing data or incurring downtime.
4. Deployments must follow a single path (CI/CD server)
Keeping with the idea of immutable artefacts and deployments that send what was deployed to production, we must also ensure that the pipelines are the only single path to production.
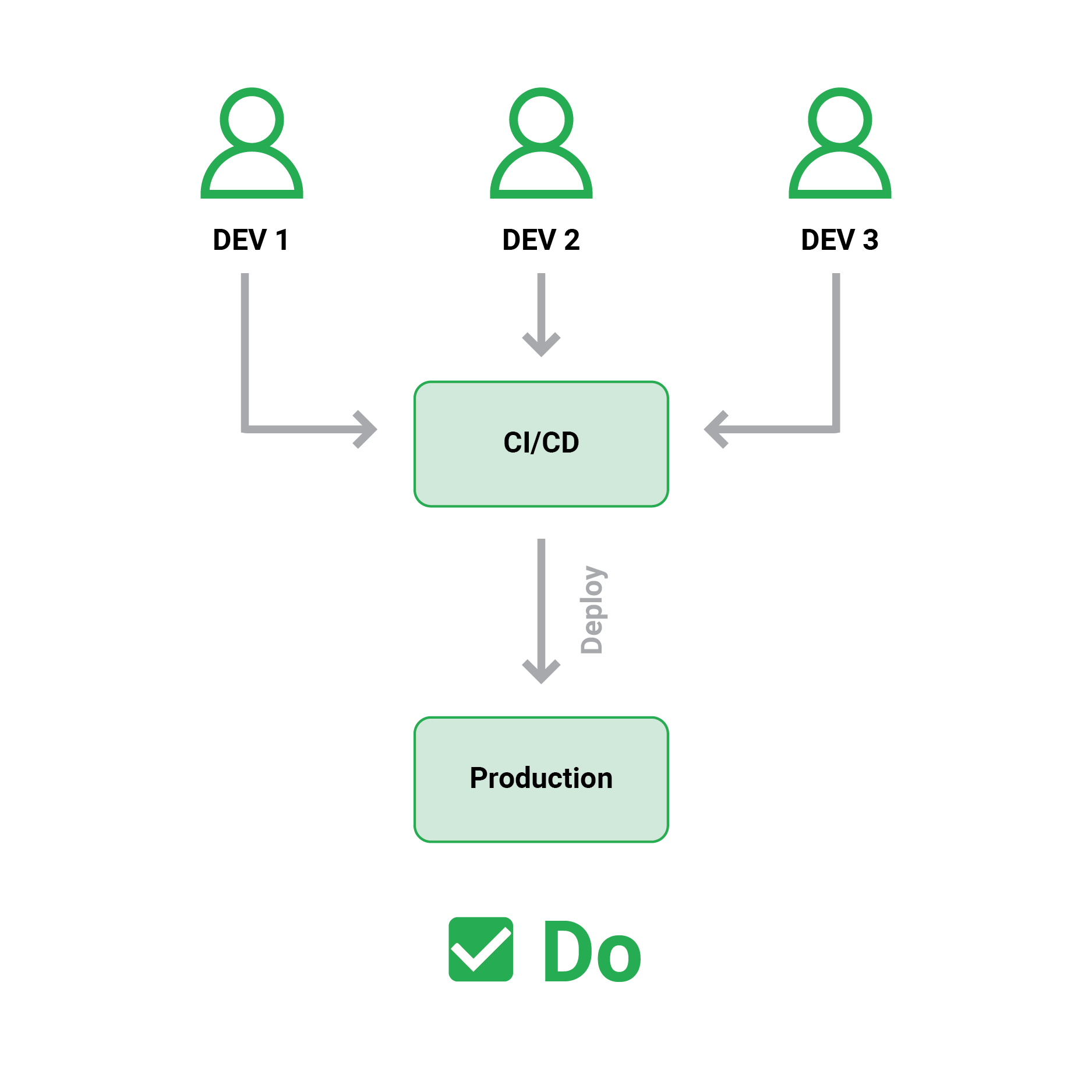
The most important aspect of using CI/CD pipelines properly is to ensure that the CI/CD platform is the sole application that can be deployed to production. This method ensures that production settings do exactly what they’re supposed to do (i.e., the last artefact that was deployed).
Several businesses, either enable developers to deploy straight from their workstations or even “inject” their artefacts into a pipeline at various stages.
This is a very risky technique since it eliminates the traceability and monitoring that a proper CI/CD framework provides. It enables developers to deploy to production features that were previously not committed to source control. Many failure deployments are caused by a missing file on a developer’s workstation that was not in source control.
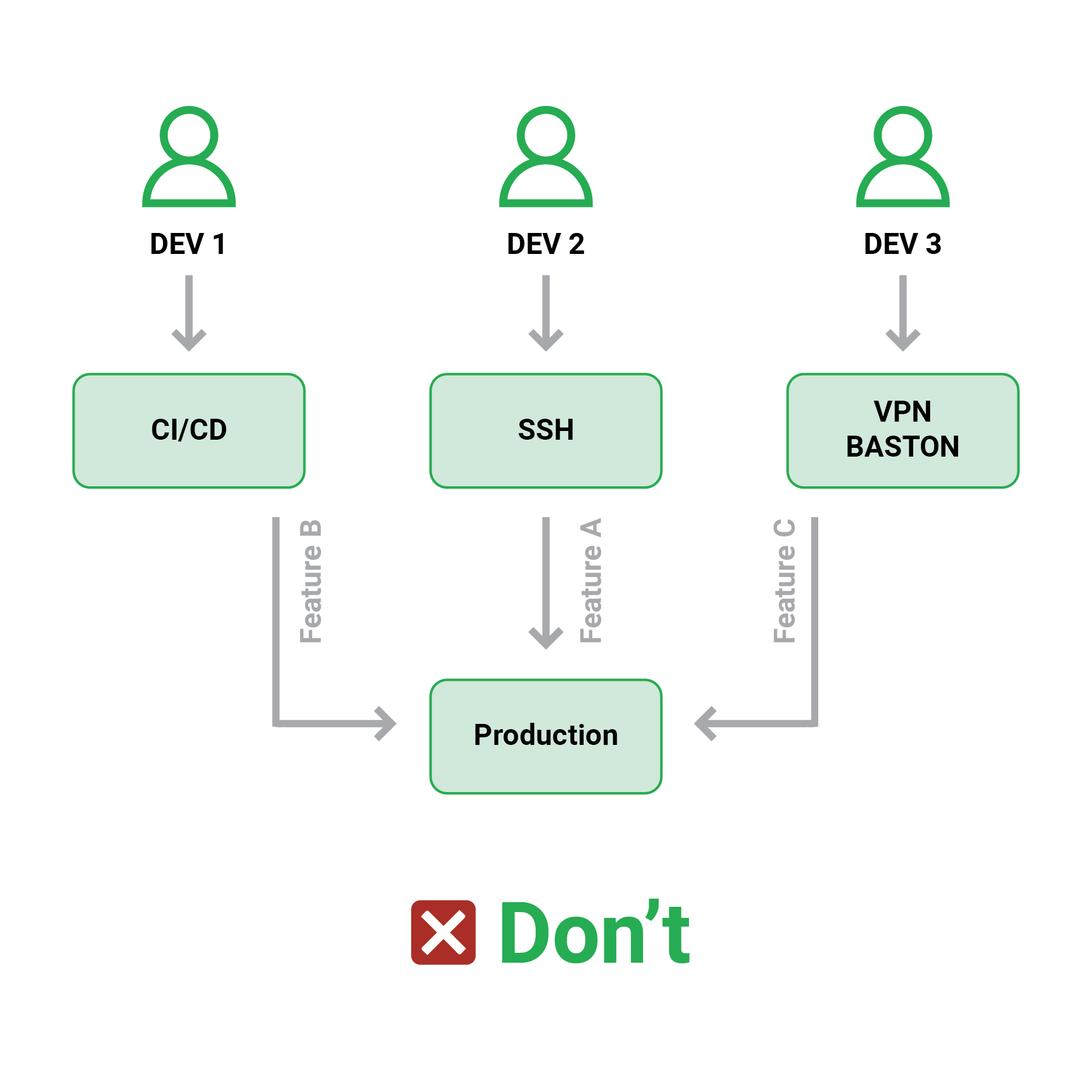
In summary, deployments have only one critical path, which is strictly controlled by the CI/CD platform. At the network/access/hardware level, deployment of production code from developer workstations should be restricted.
Traditional deployments take an all-or-nothing strategy, with all application instances upgrading to the latest software version. This is a fairly easy deployment method, however it makes rollbacks difficult.
You should instead look at:
- Blue/Green deployments create a fresh set of instances of the new version while keeping the old one around for easy rollbacks.
- Only a portion of application instances migrate to the new version in a canary release. The majority of people are still directed to the old version.
When these strategies are combined with gradual database deployments, you can reduce the amount of downtime associated with new deployments. Rollbacks are also simple, as you simply change your load balancer/service mesh to the previous configuration in both circumstances, and all users are redirected to the original version of the application.
5. Metrics and logs can detect & send successful or failure messages to developers
Even if you utilize progressive delivery, having a pipeline that deploys your application isn’t enough if you want to know what the real result of the deployment is. Large software projects frequently experience deployments that appear “successful” at first sight but quickly reveal regressions.
After a deployment, many development teams simply run a visual check/smoke test and call it a day if everything “looks” good. This method, however, is insufficient and can soon result in the introduction of minor defects or performance difficulties.

Adoption of application (and infrastructure) metrics is the correct approach. This includes the following:
- Application event logs in detail
- Metrics that count and monitor the application’s essential features
- Information tracing that can provide you with a detailed understanding of what a single request is doing
Once these indicators are in place, a before/after comparison of these metrics should be used to assess the impact of deployment. This indicates that metrics should not just be used for post-incident troubleshooting, but also as a preventative strategy against botched installations.
 Choosing which events to track and where to store logs is a difficult task. It’s best to follow a gradual redefining of important KPIs based on previous deployments for large apps. The following is a suggested workflow:
Choosing which events to track and where to store logs is a difficult task. It’s best to follow a gradual redefining of important KPIs based on previous deployments for large apps. The following is a suggested workflow:
- Place logs and metrics on occurrences that you believe will indicate a deployment failure.
- Test a few deployments to determine whether your analytics can spot the ones that fail.
- If a failure deployment is not identified in your metrics, it suggests your metrics are insufficient. Fine-tune your metrics so that the next time a deployment fails in the same way, you’ll be aware of it ahead of time.
Too often, development teams focus on “vanity” metrics, or indicators that appear nice on paper but don’t tell the whole story of a poor deployment.
6. Automatic rollbacks are in place
This follows on from the prior best practice. You can take solid metrics to the next level by having automated rollbacks that rely on them if you already have them in place (that can verify the success of a deployment).
Many firms have excellent metrics in place, yet they are only used manually:
- Before deploying, a developer examines several crucial KPIs.
- Deployment is triggered.
- The developer examines the analytics on an as-needed basis to determine what went wrong with the deployment.
While this strategy is often used, it is ineffective. Depending on the complexity of the application, the time required monitoring metrics can range from 1-2 hours so that the deployment’s effects can be seen.
It’s not uncommon for deployments to be categorized as “failed” after 6-24 hours, either because no one paid attention to the right metrics or because individuals simply ignored warnings and failures, assuming they weren’t related to the deployment.
Several companies are also obliged to deploy only during business hours because that is when there are enough human eyes to look at KPIs.
The deployment procedure should include metrics. After a deployment, the deployment pipeline should immediately consult metrics and compare them to a known threshold or their former state. The deployment should then be marked as complete or even rolled back in a fully automated manner.
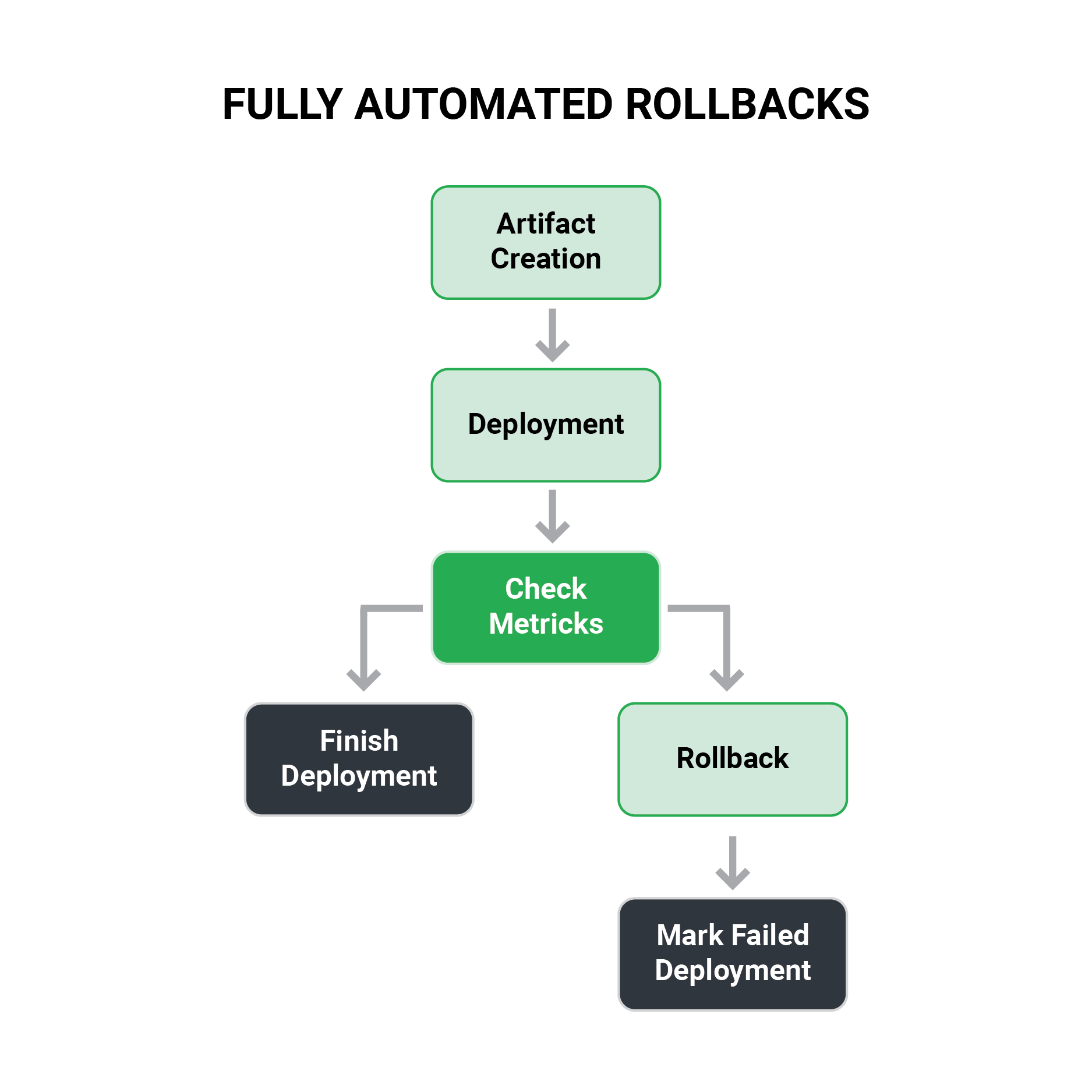
This is the holy grail of deployments because it eliminates the human aspect and is a step toward Continuous Deployment (instead of Continuous Delivery). With this strategy, you can:
- You may run deployments at any time, knowing that metrics will be scrutinized with the same care, even if it’s 3 a.m.
- Early regressions can be detected with pinpoint accuracy.
- Rollbacks (typically a stressful action) are now managed by the deployment platform, allowing non-technical people easy access to the deployment process.
- You may run deployments at any time, knowing that metrics will be scrutinized with the same care, even if it’s 3 a.m.
- Early regressions can be detected with pinpoint accuracy.
- Rollbacks (typically a stressful action) are now managed by the deployment platform, allowing non-technical people easy access to the deployment process.
As a result, a developer can go home after deploying at 5 p.m. on Friday. Either the change will be authorized (and will still be in place on Monday) or it will be automatically rolled back with no negative consequences.
7. CI/CD script should be parameterized, not hard coded
Environment variables are dynamically named values that can be used to entirely dynamic and parameterize CI/CD pipelines. To make jobs portable and provider agnostic, it’s preferable to constantly deleting hardcoded values and replacing them with parameterized environment variables.
Your staff will no longer be responsible for storing and keeping track of these credentials thanks to automation. Some of this information is hardcoded into Jenkins, GitHub, and other CI/CD technologies by default. Before you begin, remove any hardcoding from your tools; otherwise, the data could be exploited.
Putting these best practices to work in your enterprise.
Automating the process of building, testing, and releasing software is the primary goal of DevOps (or the CI/CD practice). This will require access to DevOps tools that will simplify automation while simultaneously providing visibility into the progress of the development cycle. The mechanism that tracks DevOps performance metrics throughout the SDLC is needed to raise alerts that will trigger actions for quick recovery when something goes wrong while releasing or deploying the software.
“Analysis paralysis” is a direct result of being overwhelmed by decisions on how to go about your DevOps transformation journey. To get a clear picture and jumpstart your DevOps transformation, you can find out how we can guide you through the process here.