Blogs
Best Practices in CI/CD for optimizing SDLC – Part 1


DevOps is the proverbial cookie everyone wants a bite out of. However, history has proven that not everyone is successful. While there is nothing bad about failures, they shouldn’t slip through unnoticed and un-rectified.
Knight Capital, an American global financial services firm engaging in market making, electronic execution, and institutional sales and trading, went bankrupt in 45 minutes because one deployment failed. Since there are only a few stories like that, their rarity makes us think it will never happen to us. The point that needs to be focused on is that DevOps does not fail when the damage is done, but when organizations are unable to leverage it the way it is supposed to. Gartner says, that by 2023, 90% of DevOps initiatives will have failed to meet expectations.
If your organization does not want to become a part of this statistic, you need to understand what is being done wrong and how to correct it. In this two-part blog, we will be delving into the best practices of DevOps that need to be adopted to ensure minimal chances of failure.
If you are already aware of CI/CD, you can skip to the best practices.
 What is Continuous Integration?
What is Continuous Integration?
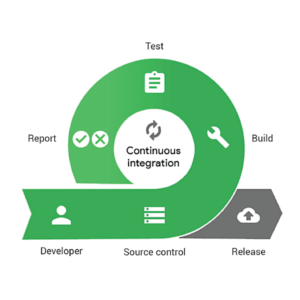
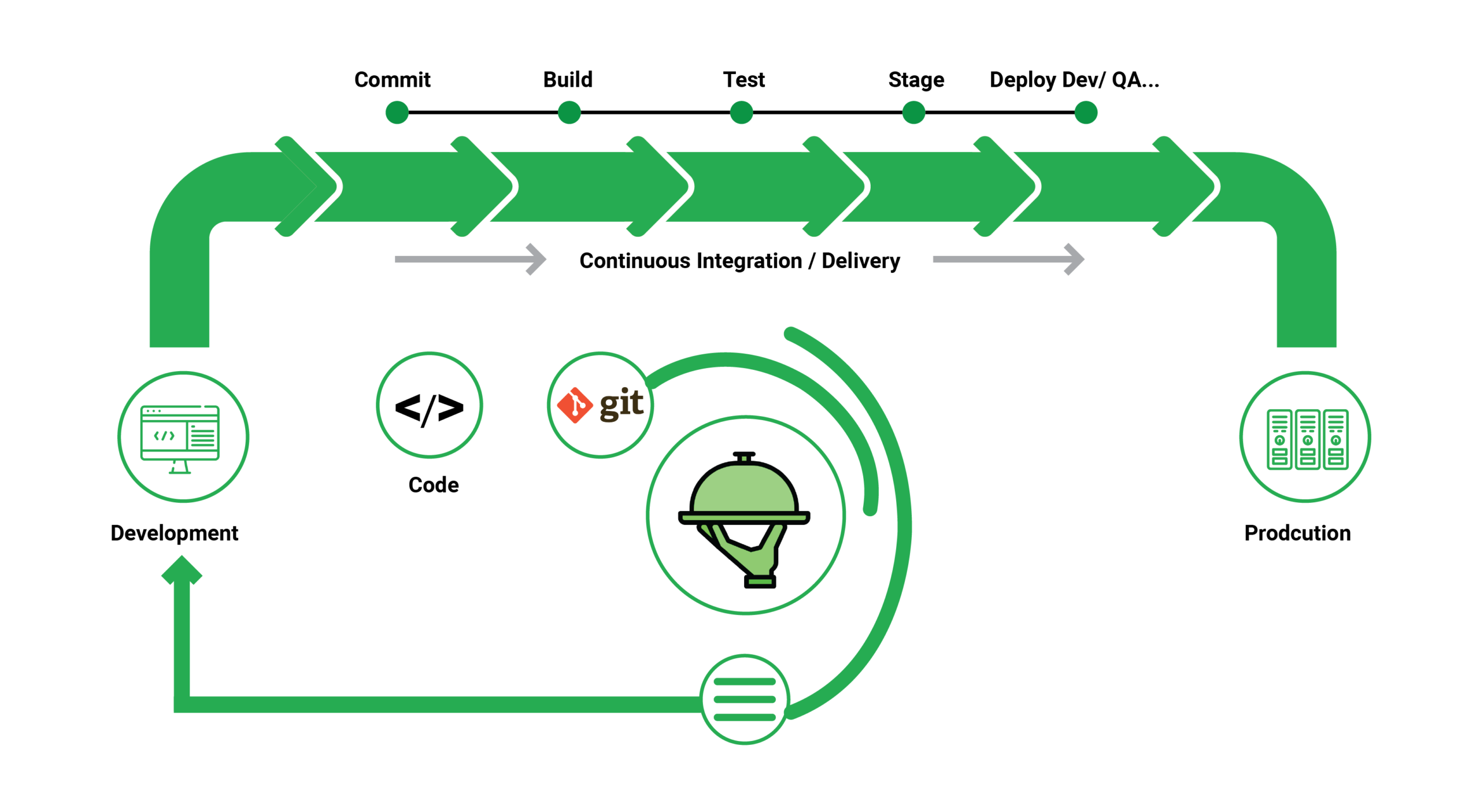
The practice of having everyone working on the same software project and communicating their modifications to the codebase on a regular basis and then testing that the code still works as it should after each change is known as continuous integration, or CI. Continuous integration is an important aspect of the DevOps method to software development and release, which emphasizes collaboration, automation, and quick feedback cycles.
Continuous integration begins with routinely committing changes to a source/version control system so that everyone is working from the same blueprint. Each commit starts a build and a series of automated tests to ensure that the behavior is correct and that the change hasn’t broken anything. Continuous integration is not only advantageous in and of itself, but it is also the initial step in establishing a CI/CD pipeline.
What is Continuous Deployment?
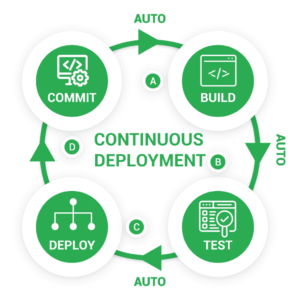
Continuous deployment takes the DevOps strategy of automating build, test, and deployment stages to its logical conclusion. If a code update passes all of the pipeline’s preceding phases, it is automatically sent to production without the need for manual intervention. Continuous deployment allows you to deliver new features to your users as quickly as possible without compromising on quality.
A mature, well-tested continuous integration and continuous delivery stage underpins continuous deployment. Small code changes are pushed to master on a regular basis, placed through an automated build and test process, promoted via multiple pre-production environments, and then deployed to live if no issues are detected. By establishing a comprehensive and dependable automated deployment pipeline, releasing can become a non-event that occurs numerous times each day.
What is Continuous Delivery?
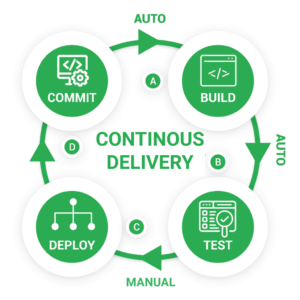
Continuous delivery aims to make the software release process faster and more reliable, reducing the time it takes to gather feedback and delivering value to users faster than a manual procedure allows. Continuous Delivery (CD) refers to the process of building, testing, configuring, and deploying software from a development environment to a production environment. A Release Pipeline automates the building of infrastructure and deployment of a new build by combining multiple testing or staging environments.
Longer-running integration, load, and user acceptability testing activities are supported by successive environments. The continuous integration and continuous delivery (CI/CD) pipeline has robust automation tools and a better workflow. If followed judiciously, it reduces human errors and improves feedback loops across the SDLC, allowing teams to deliver smaller chunks of releases in less time.
Building a CI/CD pipeline does not work in a fire-and-forget framework. It delivers better with an iterative approach, similar to software development: continually evaluating data and evaluating feedback to improve your process.
7 Best practices for CI/CD development
1. All project assets are in single source control
The ability to manage artifacts is likely the most significant feature of a pipeline. A pipeline, at its most basic level, builds binary/package artifacts from source code and deploys them to the proper infrastructure that supports the deployed application.
The following is the single most important rule to follow when it comes to assets and source code:

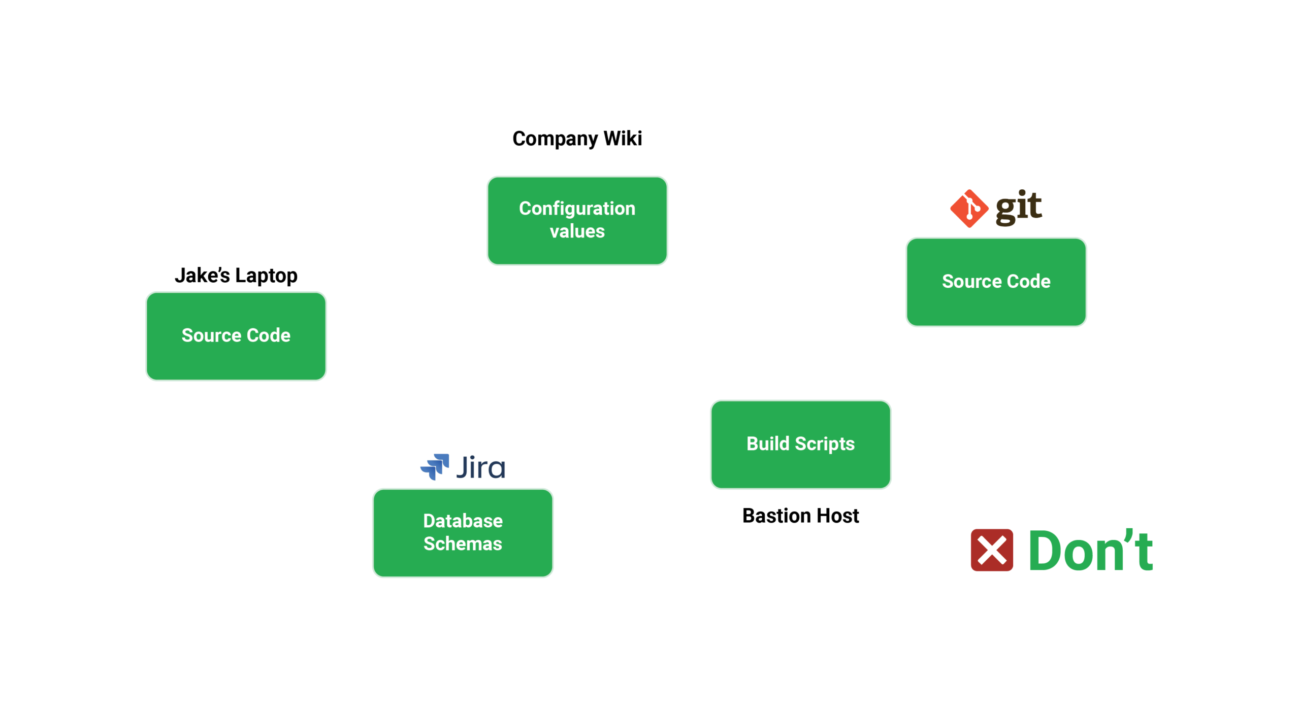
All files that constitute an application should be managed using source control.
Despite the fact that this advice appears to be straightforward, many firms fail to adhere to it. Developers have traditionally utilized version control systems just for source code, neglecting other files such as installation scripts, configuration values, and test results.
Everything that happens during the lifespan of an application should be checked into source control. This includes, but is not limited to, the following:
- Source code
- Build scripts
- Pipeline definition
- Configuration values
- Tests and test data
- Database schemas
- Database update scripts
- Infrastructure definition scripts
- Cleanup/installation/purging scripts
- Associated documentation
The ultimate goal is for anyone to be able to check out anything related to an application and duplicate it locally or in any other environment.
Deployments with a particular script that is only available on a certain machine or on the workstation of a specific team member, or even an attachment in a wiki page, are a prevalent anti-pattern we observe.
All of these resources are audited and have a complete history of all modifications thanks to version control. If you want to view how the application looked six months ago, you may easily do so using the features of your version control system.
It’s worth noting that, while all of these resources should be versioned, they don’t have to be in the same repository. Whether you use many repositories or just one is a decision that requires thought and does not have a clear answer. However, the most critical aspect is to ensure that everything is version controlled.
Despite the fact that GitOps is a rising technique of leveraging Git operations for promotions and deployments, you don’t have to follow GitOps to follow this best practice. Regardless of the software paradigm you use, having historical and auditing information for your project assets is always a good thing.
Verifying that a new feature is ready for production deployment is one of the major functions of a CI/CD pipeline. This happens over time since each stage in a pipeline effectively performs extra checks for that feature.
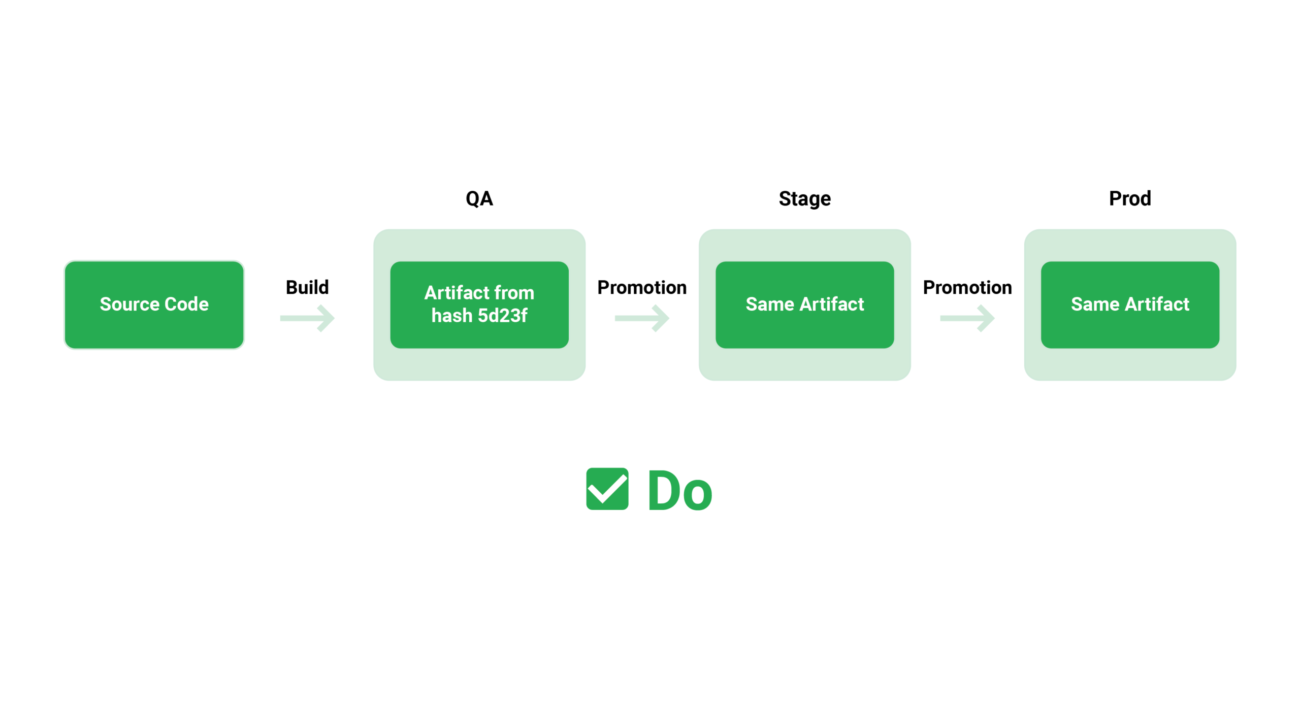
However, for this paradigm to operate, you must ensure that whatever is being tested and prodded within a pipeline is also what is deployed. In reality, this means that a feature/release should be packaged once and deployed in the same way to all subsequent environments.
Eventually, many organizations fall into the trap of developing distinct artefacts for development, staging, and production environments because they haven’t yet mastered a single configuration architecture. This means they’re deploying a slightly different version of the pipeline’s results. When it comes to botched deployments, configuration differences and last-minute modifications are two of the most common causes, and having a different package for each environment exacerbates the situation.
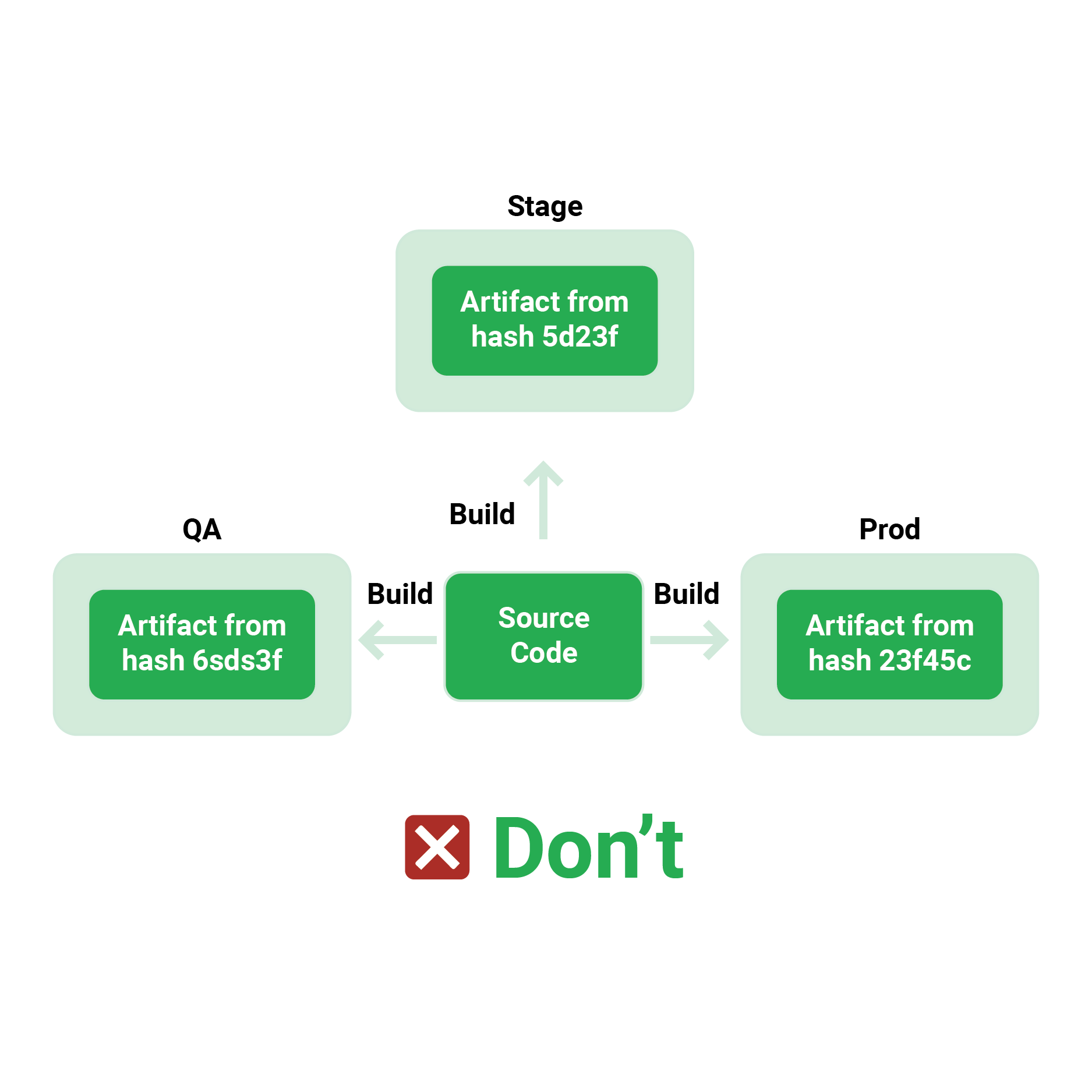
Rather than developing numerous versions for each environment, it is common practice to have a single artefact that merely changes settings between them. With the introduction of containers and the ability to create a self-contained package of an application in the form of Docker images, there is no reason to ignore this best practice.
Regarding configuration there are two approaches:
- All configurations are contained in the binary artifact/container, which changes the active one depending on the running environment (simple to start, but not particularly versatile). This is not a good strategy.)
- The container is completely unconfigured. It uses a discovery method like a key/value database, a filesystem volume, or a service discovery mechanism to fetch needed configuration on demand during execution (the recommended approach).
The end result is an assurance that the precise binary/package that is deployed in production was also tested in the pipeline.
2. Artifacts move within pipelines (and not source revisions)
The fact that a deployment artefact should only be built once is a corollary to the previous statement (the same artifact/package should be deployed in all environments).
The whole point of containers (and, in the past, VM images) is to have immutable artefacts. An application is only constructed once, using the most recent or soon-to-be-released features.
Once the artefact is created, it should be able to flow from one pipeline stage to the next without changing. Containers are the ideal vehicle for immutability because they allow you to construct an image once (at the start of the pipeline) and then promote it to production with each pipeline step.
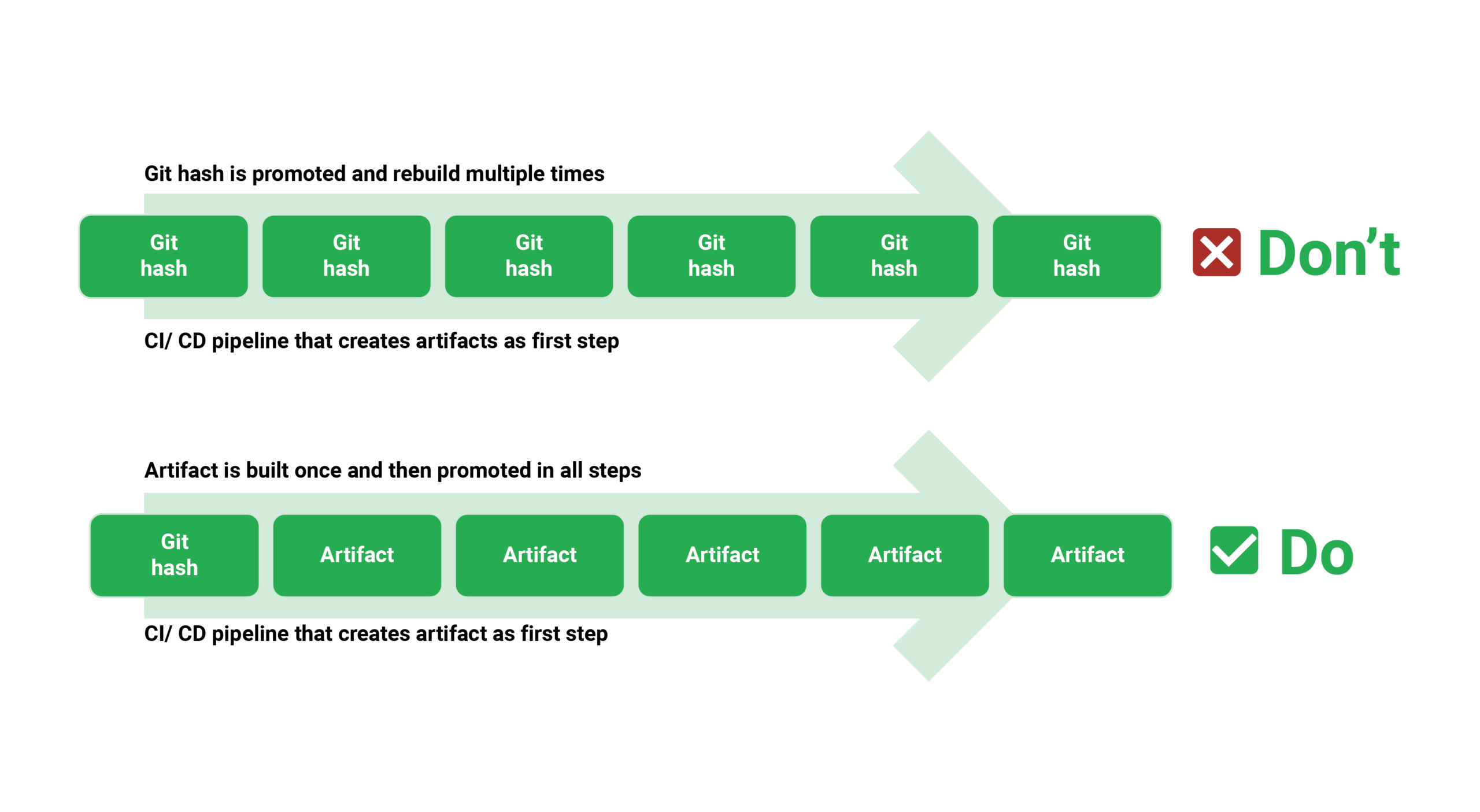
Moreover, organizations are emphasizing commits rather than container images, which is a frequent anti-pattern. A source code commit travels through the pipeline stages, and each step is recreated by repeatedly checking out the source code.
For two key reasons, this is a terrible practice. First and foremost, it slows down the pipeline since packaging and compiling software is a time-consuming operation that should not be repeated at each step.
Second, it violates the preceding rule. Recompiling a code change at each pipeline stage opens the possibility of a different artefact being produced than before. You no longer have the assurance that what is deployed in production is the same as what was tested in development.
3. Development should happen with short-lived branches (one per feature)
A sound pipeline includes many quality gates (such as unit tests or security scans) that assess a feature’s quality and suitability for production deployment. Not all features are expected to reach production right immediately in a development environment with a high velocity (and a large development team). Some features may even conflict with one another in the early stages of deployment.
A pipeline should have the ability to veto individual features and choose only a subset of them for production deployment to enable for fine-grained quality gating amongst features. The simplest way to get this guarantee is to use the feature-per-branch methodology, which assigns separate source control branches to short-lived features (those that can be completed in a single development sprint).
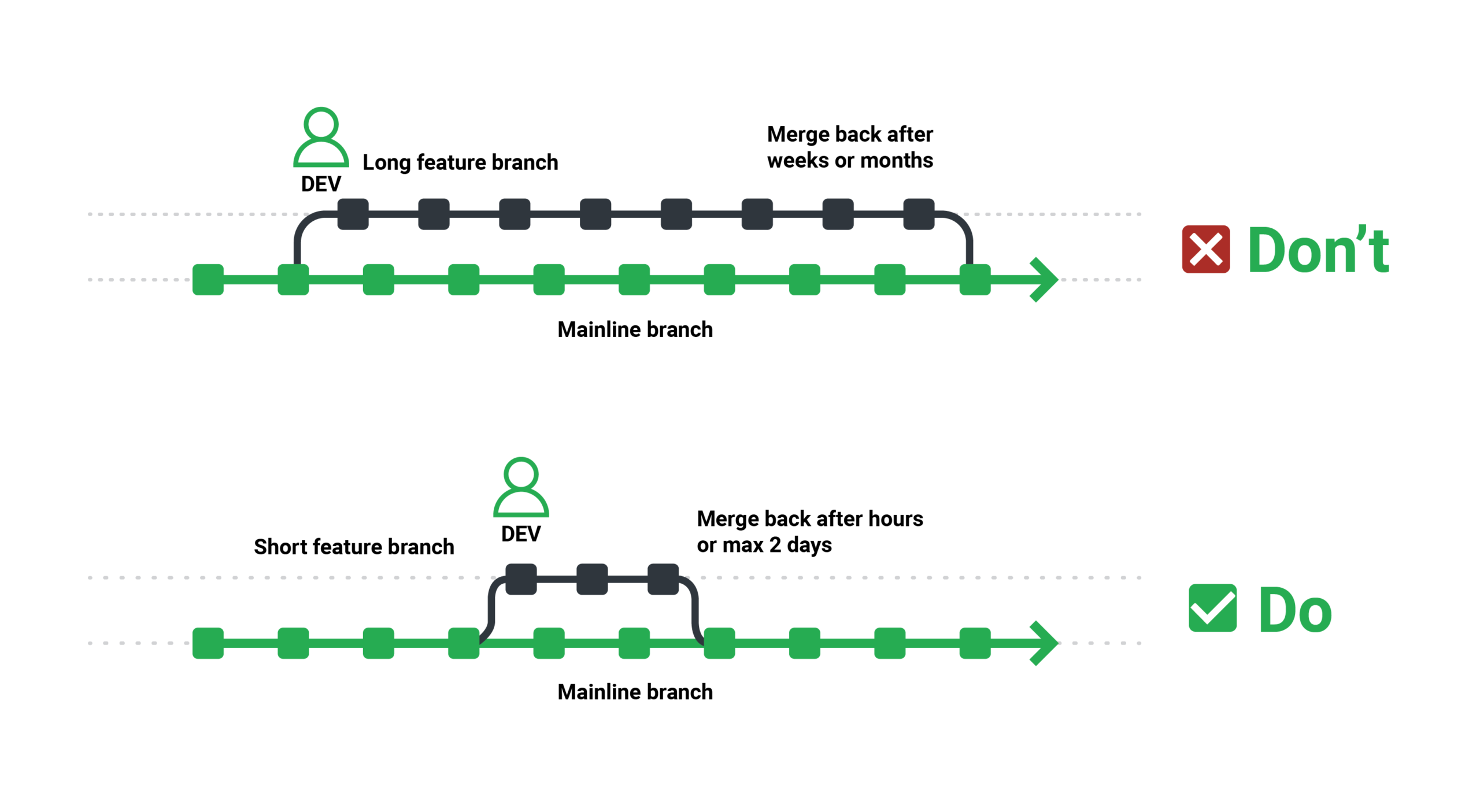 Because everything focuses around specific features, the pipeline design is quite straightforward. When test suites are run against a code branch, only the new feature is tested. A branch’s security scan reveals issues with a new functionality.
Because everything focuses around specific features, the pipeline design is quite straightforward. When test suites are run against a code branch, only the new feature is tested. A branch’s security scan reveals issues with a new functionality.
Individual features can then be deployed and rolled back, or entire branches can be blocked from being merged into the mainline code.
Consequently, some businesses still have long-lived feature branches that accumulate many, unrelated features in one batch. This not only makes merging a nuisance, but it also makes it tough if a particular feature is determined to be troublesome (as it is difficult to revert it individually).
Short-lived branches evolve in lockstep with trunk-based development and include toggles. This could be your ultimate goal, but only if you’ve mastered the short-term branches first.
4. Builds can be performed through pipeline with a one click.
Automation is at the heart of CI/CD pipelines. It’s simple to automate something that was already simple to operate in the first place.
A simple build of a project should, in theory, be a single command. That command typically invokes the build system or a script (e.g., shell, PowerShell) to take the source code, run some basic tests, and package the resulting artifact/container.
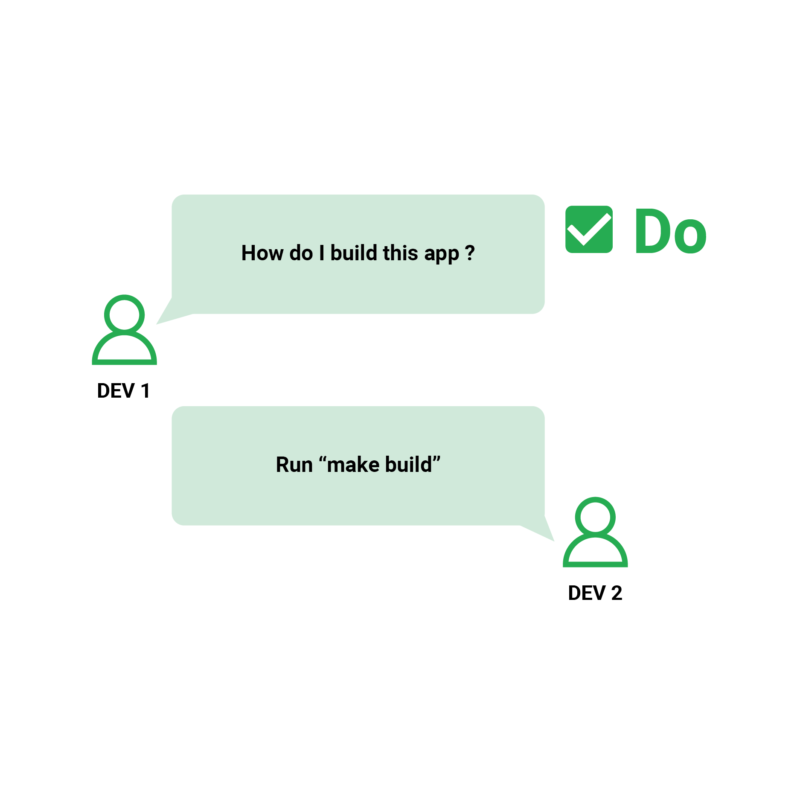
It’s fine if more complex inspections (like load testing) necessitate extra stages. However, the basic build (which produces a deployable artefact) should just require one command. A new developer should be able to check out a fresh copy of the source code, run this single command, and get a deployable artifact almost instantly.
The same technique applies to deployments (which should be accomplished with a single command). Then, if you need to develop a pipeline, you can simply insert that one step into any part of it.
However, numerous manual processes are still required to get a basic construction up and operating in certain companies. Extra files should be downloaded, properties should be changed, and large checklists should be followed should all be automated within the same script.

If it takes more than 15 minutes for a new employee in your development team to do a simple build (after checking out the code on their desktop), you almost surely have this issue.
A well-designed CI/CD pipeline simply replicates what can be done on a local workstation. Before moving to a CI/CD platform, the basic build and deploy process should be well-oiled.
Both developers and operators/system administrators benefit greatly from a quick build.
Developers are satisfied when the feedback loop between a commit and its side effects is as short as possible. Because the error in the code is still fresh in your mind, it’s incredibly straightforward to correct. It’s quite inconvenient to have to wait an hour for developers to identify unsuccessful builds.
Both at the CI platform and on the local station, builds should be quick. Multiple features are attempting to join the code mainline at any given time. If constructing them takes a long time, the CI server may get overburdened.
Fast builds also assist operators significantly. It’s usually a stressful affair to push hot changes into production or roll back to previous releases. The less time you spend on this, the better. Rollbacks that take 30 minutes are far more difficult to work with than three-minute rollbacks.
In conclusion, a basic construction should be really quick. In a perfect world, it would take less than five minutes. If it takes longer than 10 minutes, your team should look into the reasons for the delay and try to reduce it. Caching methods in modern build systems are excellent.
- Instead of using the internet, get library requirements from an internal proxy repository.
- Avoid using code generators unless necessary.
- Separate your unit (quick) and integration (slow) tests, and utilize unit tests only for the most basic builds.
- To get the most out of Docker layer caching, fine-tune your container images.
If you’re considering switching to microservices, one of the benefits you should consider is faster builds.
It’s all over the news these days. The event with the left pad. The trick of dependence ambiguity. While both instances have significant security consequences, the truth is that saving your dependencies is a critical pillar for the integrity of your builds.
External dependencies in the form of libraries or accompanying tools are used by every significant piece of code. Of course, you should always keep your code in Git. However, you should keep all external libraries in some form of artifact repository.
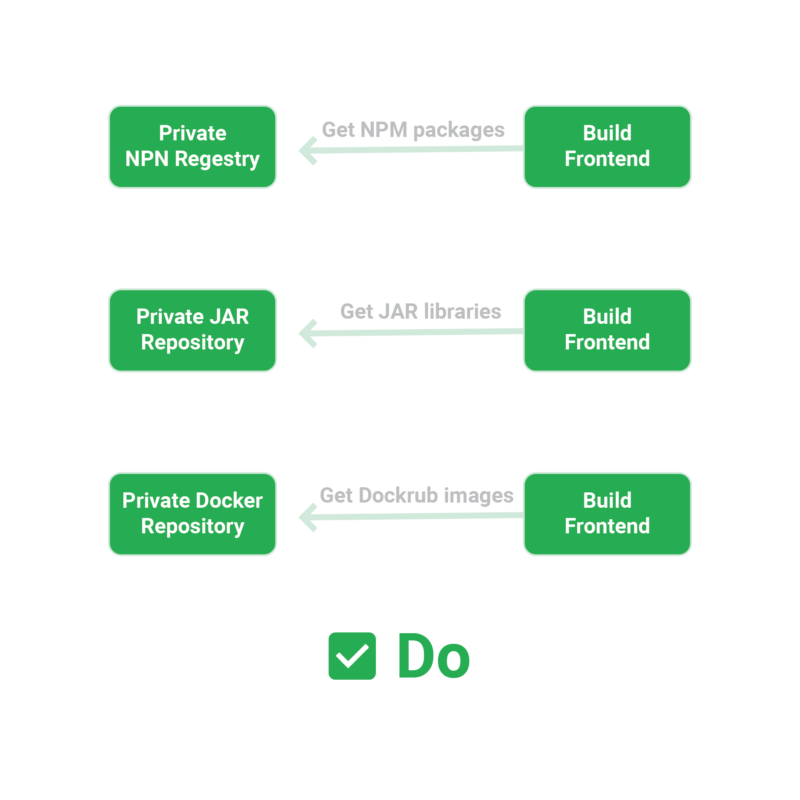
Spend some time gathering our dependencies and figuring out where they come from. Apart from code libraries, a complete build requires other less evident moving elements, such as your base docker images or any command-line utilities required for your builds.
The easiest way to ensure that your build is stable is to disable internet connectivity on your development servers entirely (essentially simulating an air-gapped environment). Try starting a pipeline build with all of your internal services available (git, databases, artefact storage, container registry) but no external services available, and see what happens.
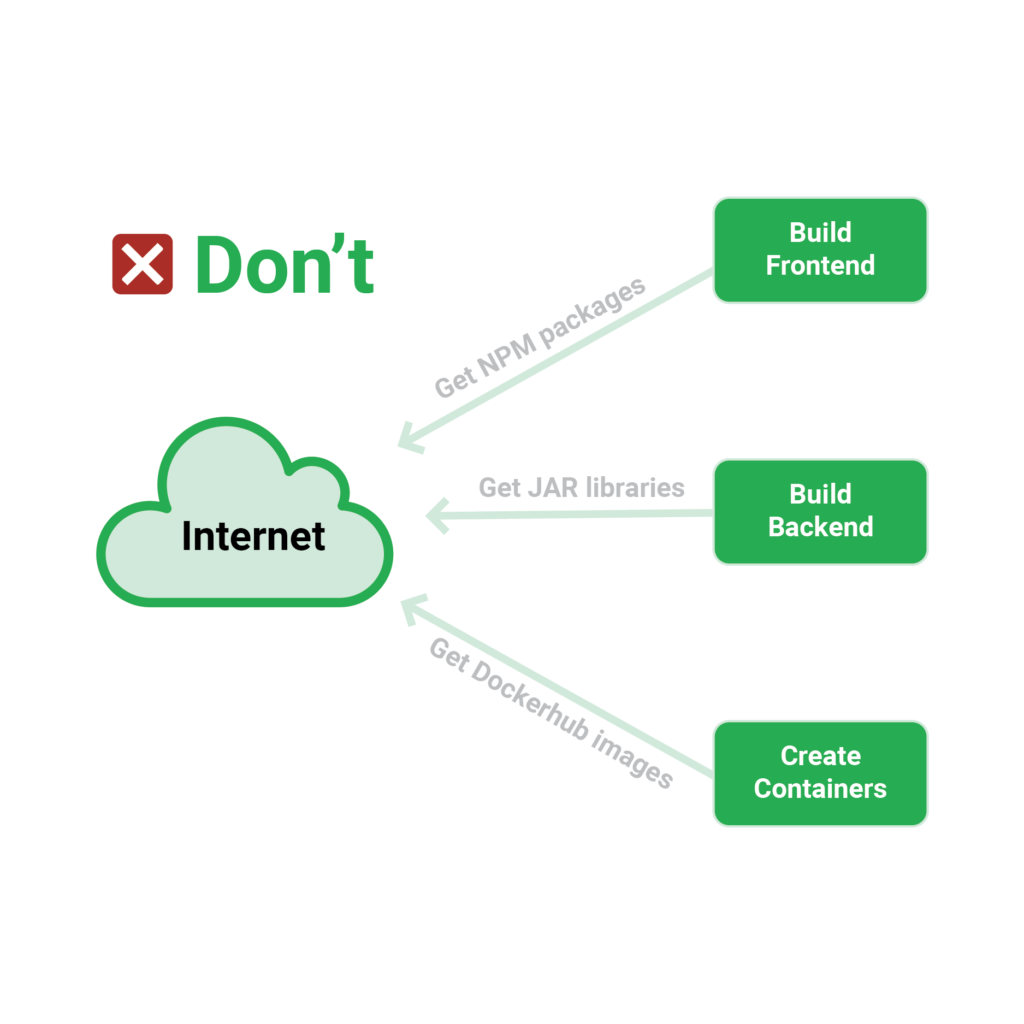
Imagine the same thing happening in a real event if that particular external resource is also down if your build complains about a missing requirement.
5. Tests are automated, fast, and auto-cleaned
The primary purpose of unit, integration, and functional tests is to boost confidence in each new release. In principle, a large number of tests will ensure that no regressions occur with each new feature that is released.
Tests should be fully automated and handled by the CI/CD infrastructure to achieve this goal. Not only should tests be run before each deployment, but they should also be run when a pull request is created. The test suite must be runnable in a single step in order to reach the level of automation.
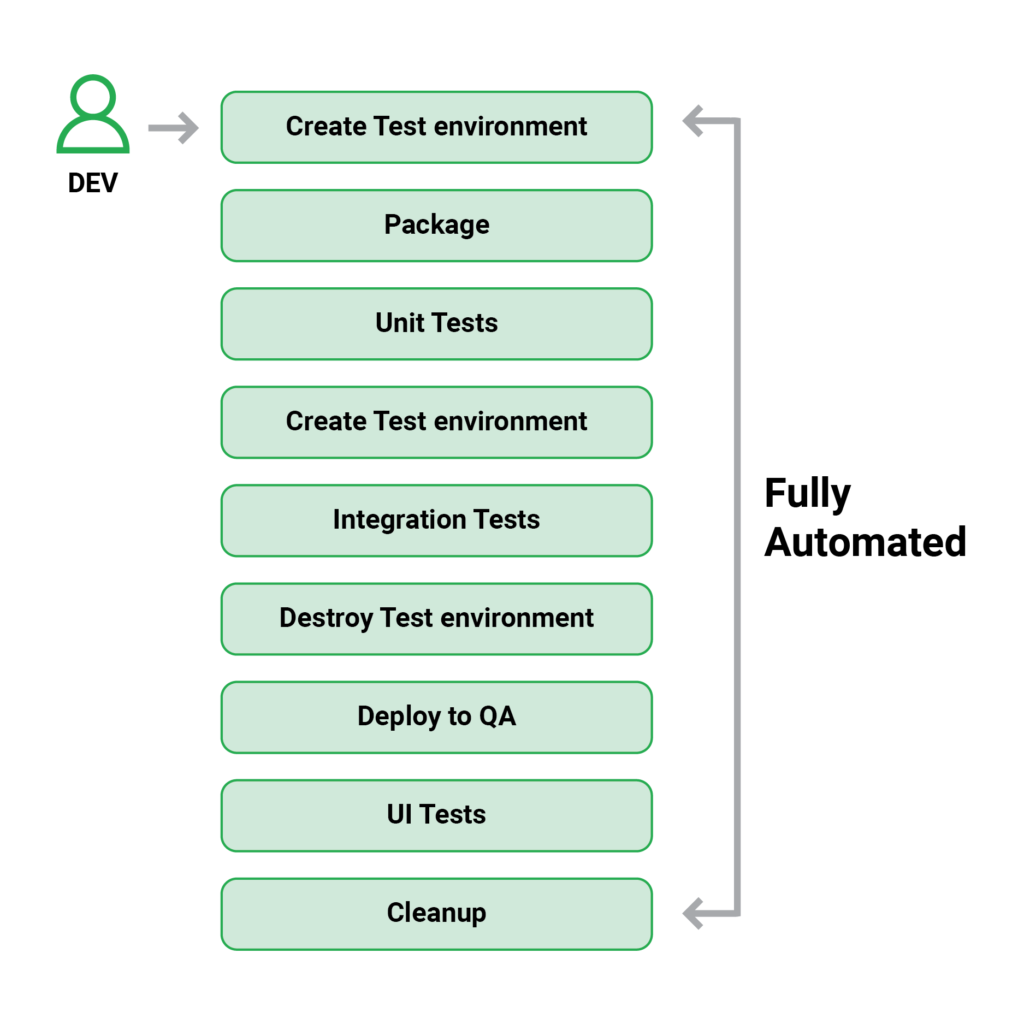
Surprisingly, numerous firms are still doing things the old way, with an army of test engineers responsible for manually executing multiple test suites. As the testing velocity effectively becomes the deployment velocity, all new releases are halted.
Only new tests should be written by test engineers. They should never run tests themselves because this significantly lengthens the feedback cycle for new features. The CI/CD platform always runs tests in various workflows and pipelines automatically.
It’s fine if a small number of tests are manually run as part of a release’s smoke test. However, this should only happen for a few tests. All of the other major test suites should be completely automated.
The rapid execution of tests is a corollary of the previous section. Test suites must be extremely rapid if they are to be integrated into delivery processes. The test time should ideally not exceed the packaging/compilation time, which means that tests should be completed in less than five minutes and no more than fifteen.
Developers may be certain that the feature they just contributed has no regressions and can be securely promoted to the next workflow stage thanks to the speedy test execution. A two-hour running time is catastrophic for developers because they cannot possibly wait that long after committing a feature.
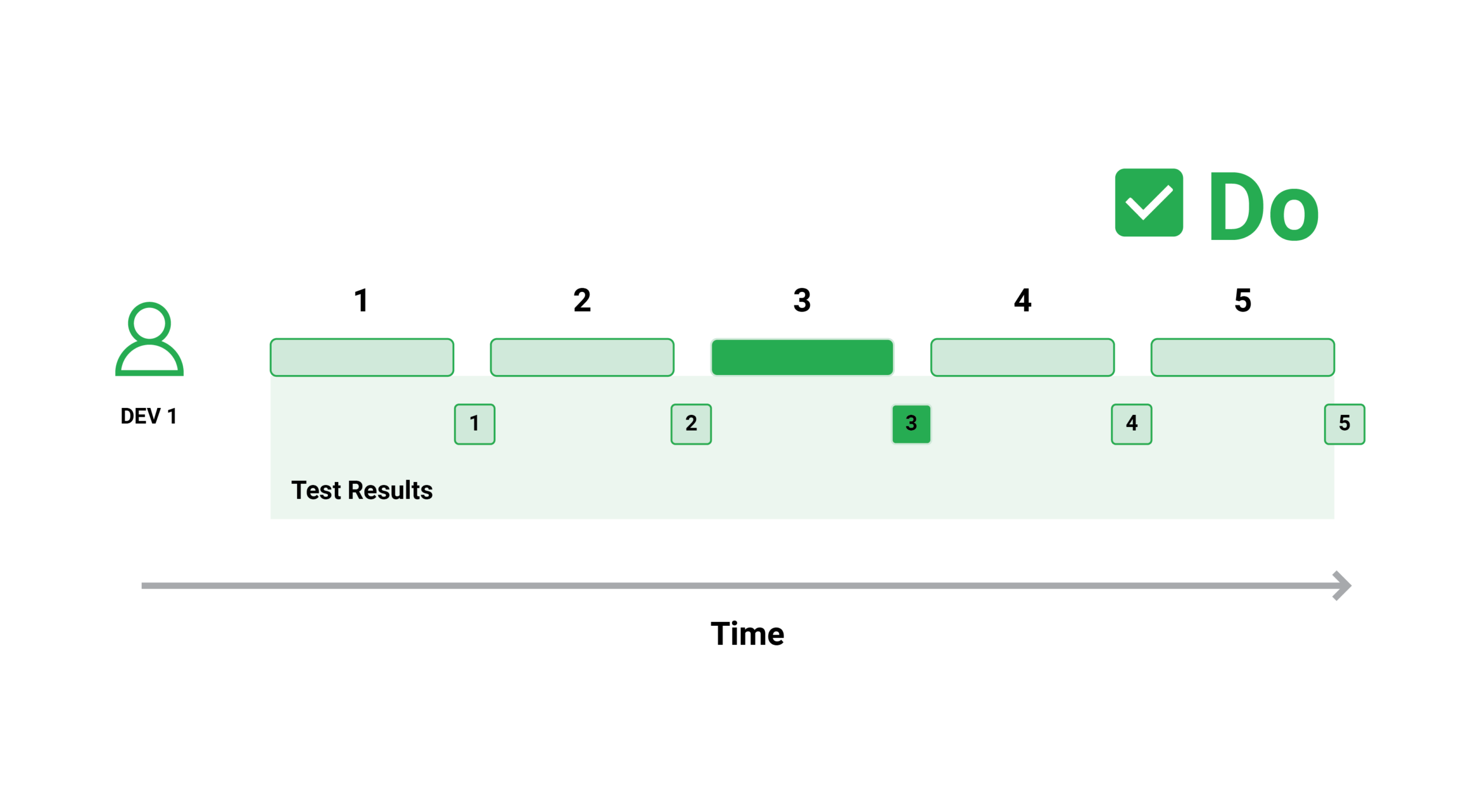
Developers just move on to their next activity and alter their mental context if the testing duration is that long. It’s considerably more difficult to fix errors on a feature that you aren’t actively working on after the test results arrive.
Indeed, most of the time spent waiting for tests is due to inadequate testing processes and a lack of optimizations. A slow test is usually caused by code that “sleeps” or “waits” for an event to occur, causing the test to run longer than it should. All of the sleep statements should be deleted, and the test should be structured around events (i.e., responding to events instead of waiting for things to happen)
Another area where tests spend the majority of their data is in the development of test data. The code for creating test data should be centralized and reused. If a test takes a long time to prepare, it’s possible that it’s testing too many things or that it requires mocking in unrelated services. Test suites should be short (5-10 minutes) and large tests should be refactored and rewritten.
In general, you can divide your unit tests into two more groups (apart from unit/integration or slow and quick) based on their side effects:
- Tests with no negative consequences. They simply read data from external sources, never make any changes, and can be performed as many times as you like (or even in parallel) without raising any issues.
- Tests with unfavorable outcomes. These are the tests that actually write data to your database, commit data to external systems, and execute output operations on your dependencies, among other things.
The first type (read-only testing) is simple to manage because it does not necessitate any particular upkeep. However, the second type (read/write tests) is more critical to maintain since you must ensure that their actions are cleaned away as soon as the tests are completed. There are two ways to go about this:
- Allow all of the tests to run, then clean up all of the actions at the end of the test suite.
- After each test, have it clean up on its own (the recommended approach)

Cleaning up the side effects of each test is a preferable strategy because it allows you to run all of your tests in parallel or at any time you like (i.e., run a single test from your suite and then run it again a second or third time).
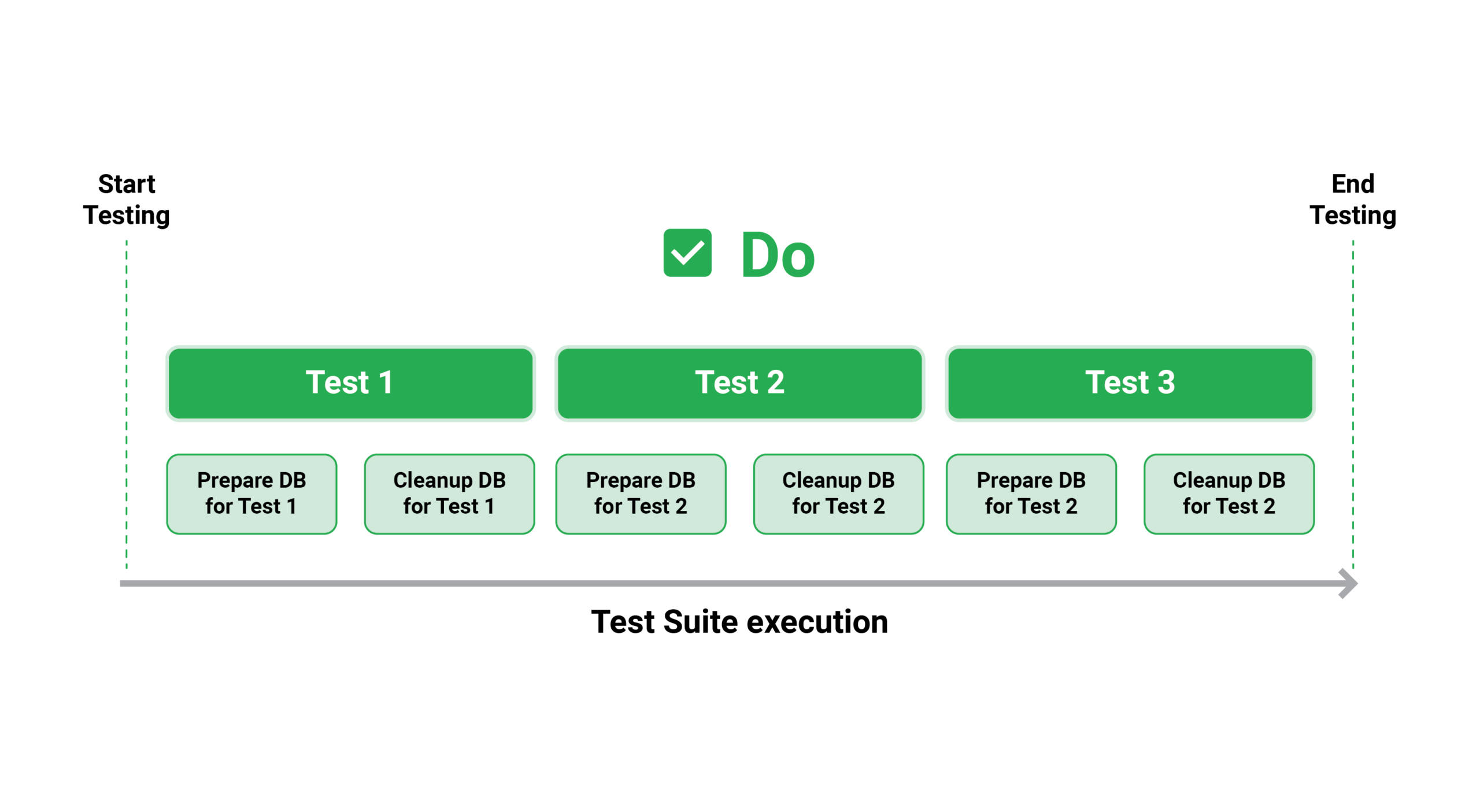
6. Test environments on demand & can run concurrently with Multiple test suites
Testing isn’t something that happens in a CI/CD pipeline in a single step. Testing is an ongoing process that affects all stages of the pipeline.
This means that each well-designed application should include a variety of test types. Some of the more common examples are as follows:
- Unit tests that are extremely rapid to run and look for big regressions.
- Integration tests that are longer and seek for more complicated scenarios (such as transactions or security)
- Load and stress testing
- Contract testing for changes to the APIs of external services that are used
- Smoke tests that can be used in production to ensure that a release is safe.
- User interface (UI) tests are used to evaluate the user’s experience.
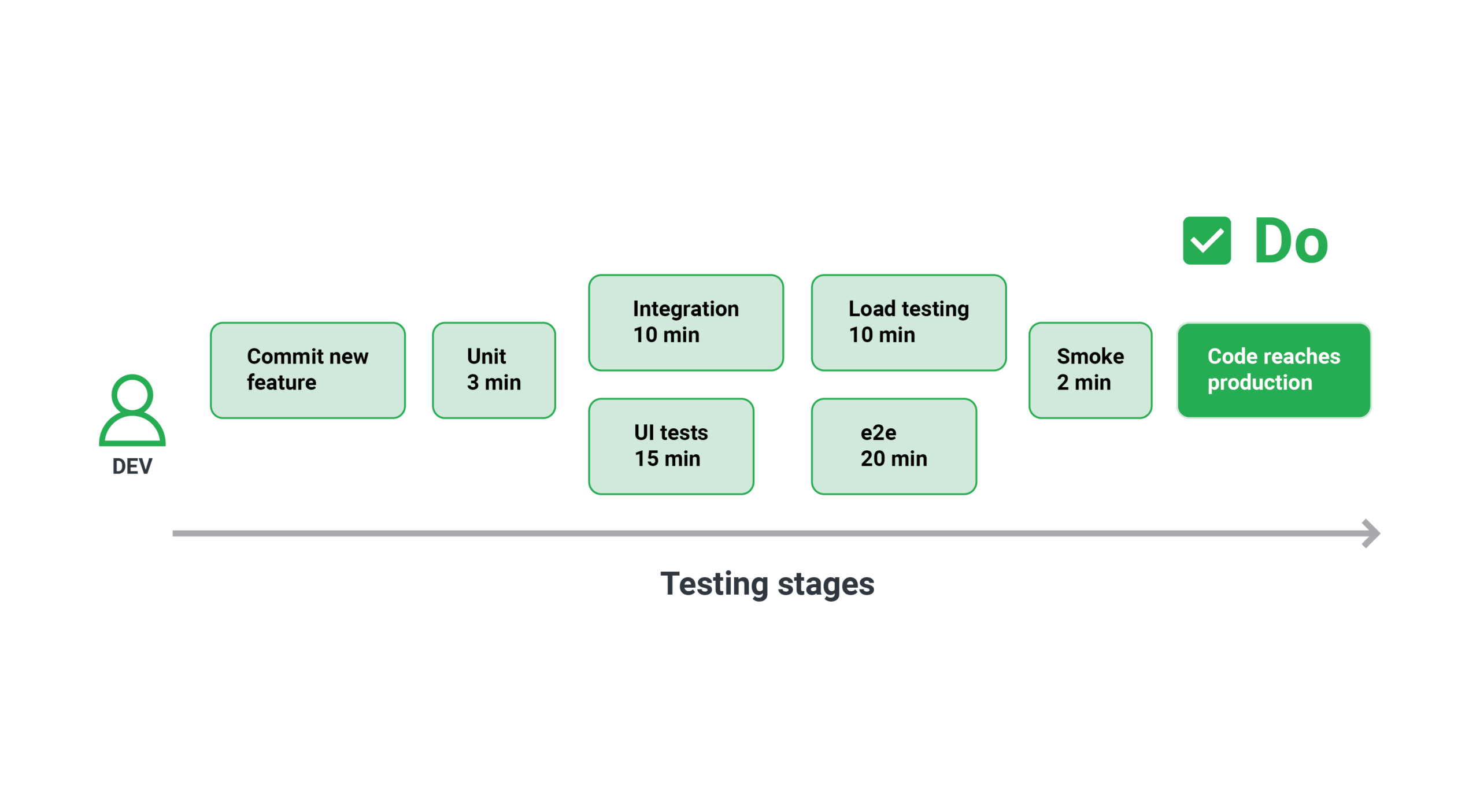
For example, because stress and load tests are only required before a production release, a pipeline for pull requests might not include them. When you submit a pull request, the quick unit tests and maybe the contact testing suite will be run.
The rest of the tests (such as smoke tests in production) will run when the Pull Request is approved to verify the expected behavior.
Some test suites are so sluggish that executing them on demand for each Pull Request is extremely difficult. Stress and load testing is typically done soon before a release (possibly by aggregating many pull requests) or on a regular basis (a.k.a. Nightly builds)
Because each organization has its own processes, the exact workflow isn’t important. What matters is the ability to isolate each testing suite and choose one or more for each phase of the software development process.
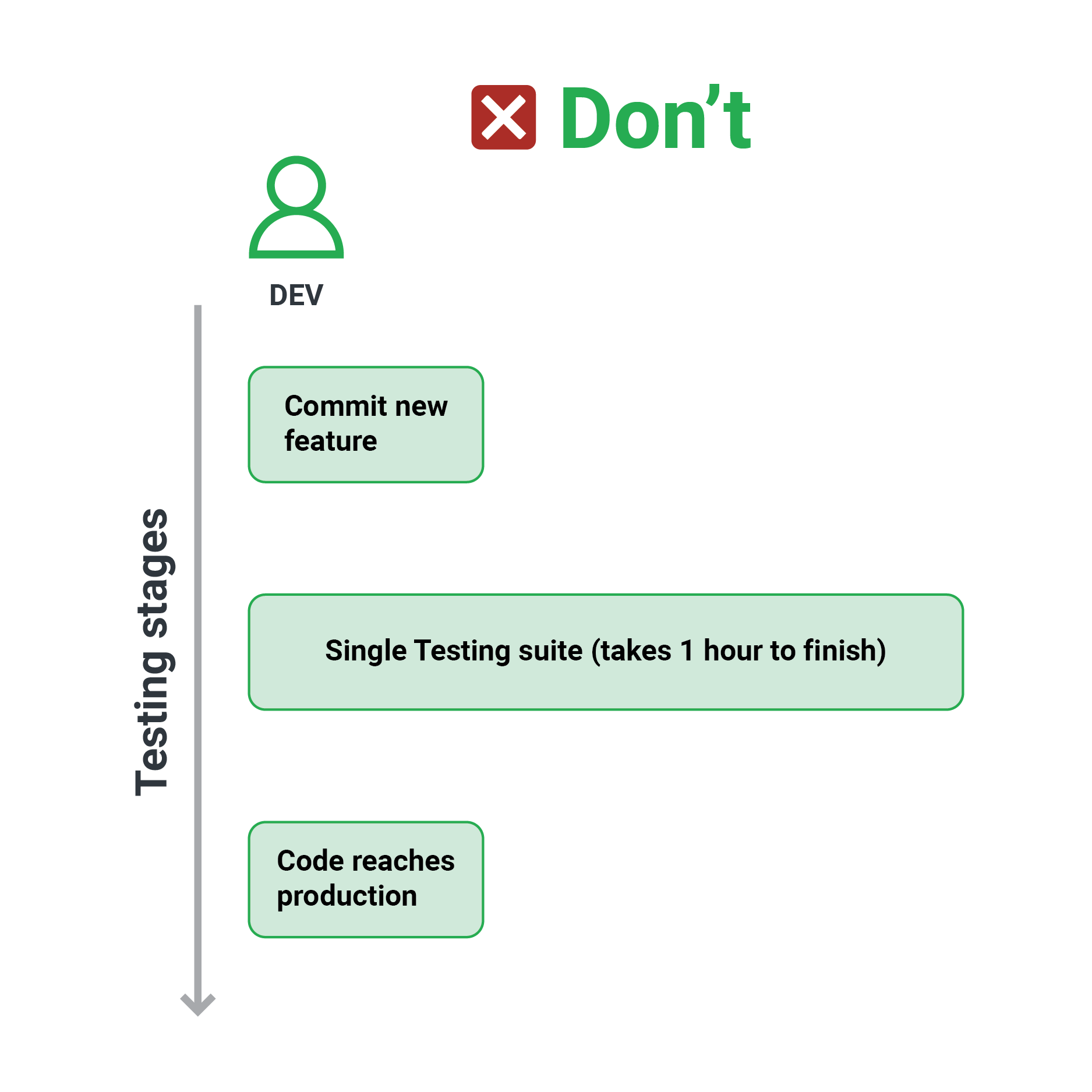
It’s inconvenient to have a single test suite for everything, and it forces engineers to skip tests locally. As a developer, I should be able to run as many test suites as I like against my feature branch, allowing me to be more versatile in how I test my feature.
A staging environment is the usual means of testing an application shortly before it goes into production. The fact that there is only one staging environment is a significant drawback because it forces developers to either test all of their features at the same time or create a queue and “book” the staging environment exclusively for their feature.
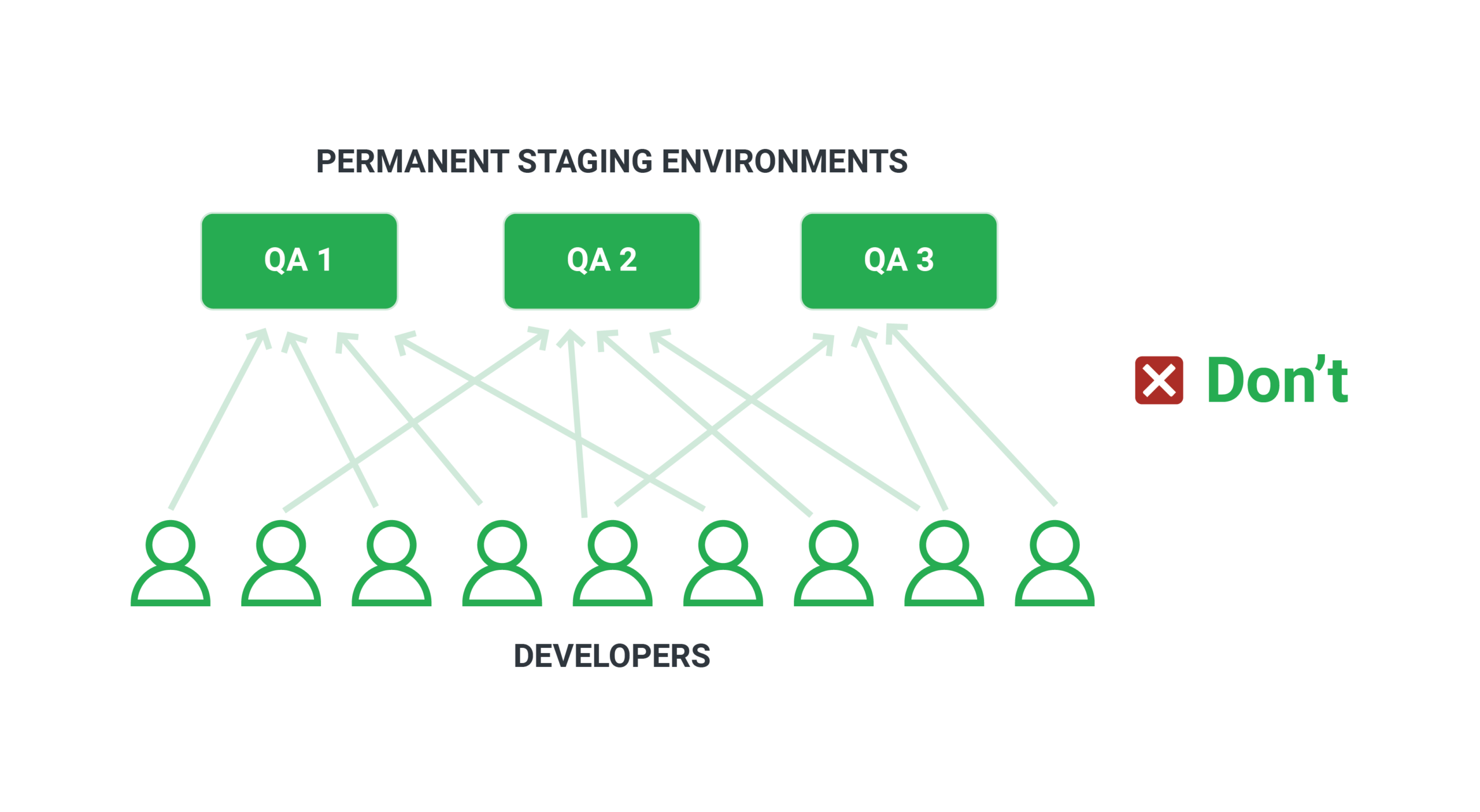
Many firms are forced to construct a fleet of test environments (e.g., QA1, QA2, QA3) in order for numerous developers to test their features simultaneously. This method is still not perfect because of the following reasons:
- A maximum of N developers (the same as the number of environments) can test their feature concurrently.
- Testing environments consume resources on a regular basis (even when they are not used)
- Because environments are static, they must be cleaned and updated on a regular basis. The team in charge of test environments will have to put in more effort as a result of this.
It is now much easier to establish test environments on demand because of cloud-based design. Instead of having a set amount of static environments, you should change your pipeline procedure such that each time a developer creates a Pull Request, a dedicated test environment containing the contents of that Pull Request is also created.
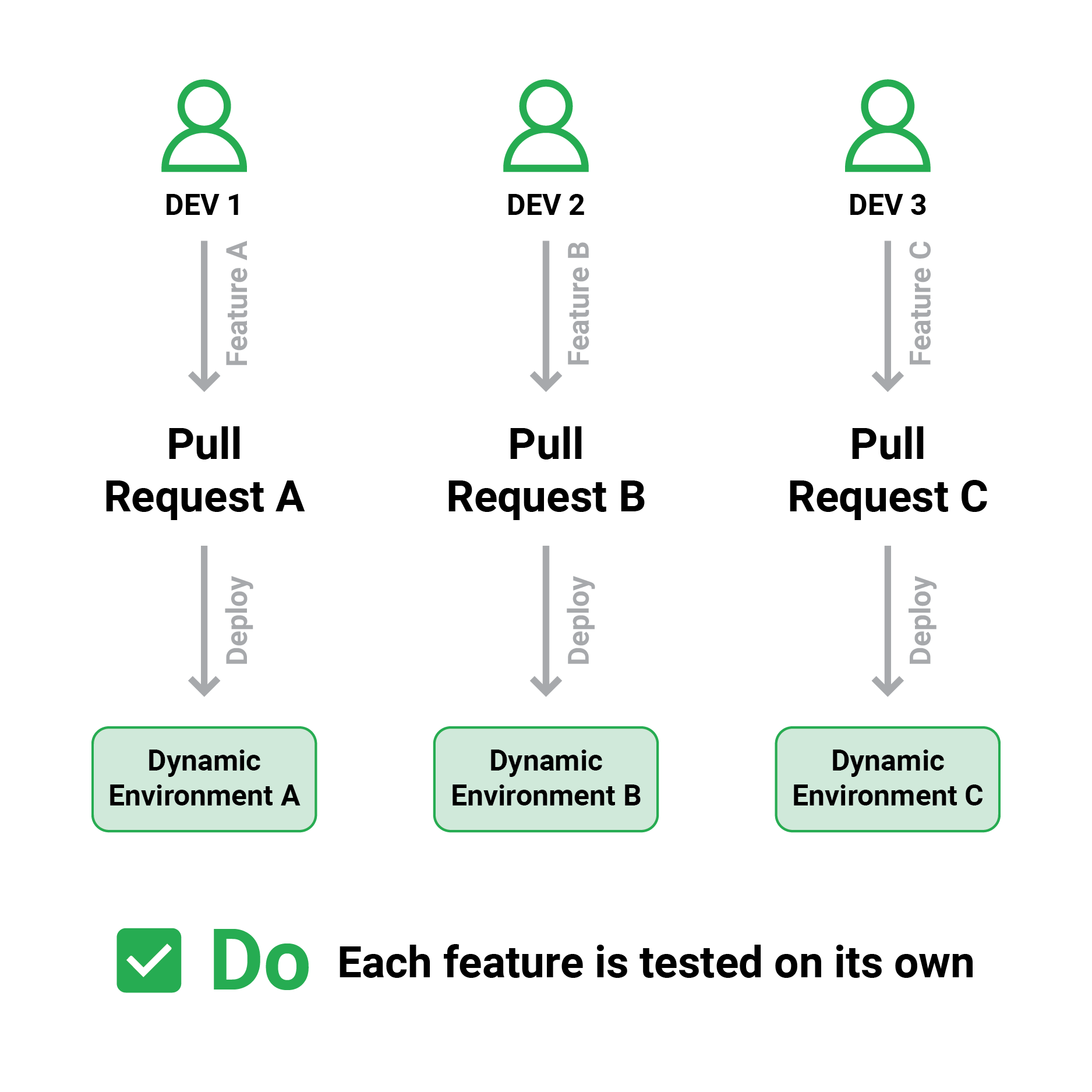
The benefits of dynamic test environments are incalculable:
- Each developer can test independently without interfering with the work of other developers.
- You only pay for test environment resources when you utilize them.
- There is nothing to maintain or clean up because the test environments are discarded at the end.
- Teams with a sporadic development schedule may benefit from dynamic test environments (e.g., having too many features in flight at the end of a sprint)
This is a logical extension of the preceding best practice. If your development process uses dynamic test environments, distinct test suites can run for any number of those settings at any time, even at the same time.
Having a changeable number of test environments will worsen the pre-run and post-run routines that you have for your tests if they have unusual dependencies (e.g., they must be launched in a specified order or they expect specific data before they can operate).

The answer is to adopt best practices 10 and have each test prepare its own state and clean up after itself. By definition, read-only (i.e., without any side effects) tests can execute in parallel.
Tests that need the ability to write or understand information must be self-contained. If a test stores an entity in a database and then reads it back, you shouldn’t use a hardcoded primary key because the second test suite will fail due to database constraints if two test suites using this test run at the same time.
While most developers believe that test parallelism is solely used to speed up tests, it is actually used to ensure that tests are proper and have no uncontrollable side effects.
7. Security scanning is part of the process
The traditional waterfall model of software development is still used by many firms. And, in the majority of cases, the security analysis comes last. After the software is created, it is subjected to a security scan (or even a penetration test) on the source code. The insights are publicized, and coders scramble to address all of the problems.
It’s a lost cause to include security scanning at the conclusion of a release. Some important architectural decisions have an impact on how vulnerabilities are identified, and knowing about them in advance is crucial for all project stakeholders, not just developers.
The process of ensuring security is never-ending. Vulnerabilities in an application should be checked as it is being developed. As a result, security scanning should be included in the pre-merge procedure (i.e as one of the checks of a Pull Request). It’s considerably more difficult to fix security concerns in a finished software package than it is in development.
Scan depth should also be considered when doing security scans. At the very least, double-check:
- Your application source code
- The container, or underlying runtime, on which the application runs.
- The computing node and the Operating System that will host the application
Many businesses concentrate just on two (or perhaps one) of these areas, forgetting that security functions in the same way as a chain (the weakest link is responsible for the overall security)
It’s advisable to enforce security on the Pull Request level if you want to be proactive with it. Rather than scanning your source code and subsequently exposing its flaws, it is preferable to prevent merges from occurring in the first place if a specific security threshold is not met.
A deep understanding of DevOps and the readiness to shift to a new workflow is essential in ensuring your DevOps are successful. Following the best practices diligently will maximize your chances of avoiding things that can go wrong.
In the second part of this blog, we will talk about why code reviews, database updates, metrics, and logs & rollbacks are essential for CI/CD.