


Blogs
Running Textract on AWS Lambda to Process Old Format MS Word Documents


Document Processing use cases are becoming increasingly common these days, and with serverless being the norm in the industry, it becomes critical to ensure that the processing code runs seamlessly on services like AWS Lambda.
AWS Lambda runs on top of Amazon Linux servers and successful execution of code requires installation of compatible packages. There are situations where this becomes challenging.
We worked on the design of a resume parser recently, where the idea was to extract different fields of interest from resumes to help power our Recruitment app. The resumes were either in word (.docx/doc) or in PDF format. While python-docx was good enough for the processing of .docx files, the challenge was processing .doc files. PDF files were processed through Amazon Textract.
Most word documents are .docx based these days. .doc is considered necessary only if the file is to be used by pre-2007 versions of Word. However, around 10-15 % received for processing were .doc based only.
Textract is one of the packages commonly used for processing of .doc files. However, dependencies need to be installed for it to run successfully on serverless platforms. In this blog, we discuss how we can successfully process .doc files on AWS Lambda using the Textract package.
The blog is organized as follows :
- Introduction to Textract
- Running Textract on AWS Lambda
- Different ways of Installing Dependencies
- Dockerfile for Installing Textract Dependencies
- Generating Docker Image and Integrating with AWS Lambda
- How to Handle Errors while Creating Images and Extracting Text
- Conclusion
Introduction to Textract
Textract is a python package which can be used to extract data from a wide variety of file types.
It differs from other packages because it provides a single interface for the same, whereas there many other packages are suited to specific extensions only.
The Textract package can be used to extract content from a document as follows :
import textract
text = textract.process("path/to/file.extension")
Running Textract on AWS Lambda
When it comes to executing files on Lambda based on uploads in an S3 bucket, the following code can be used.
This will require installation of appropriate packages for textract.
from __future__ import print_function
import json
import urllib
import sys
import textract
import boto3
s3 = boto3.client('s3')
def handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'],encoding='utf-8')
try:
s3.download_file(Bucket=bucket, Key=str(key),Filename='/tmp/'+str(key))
text = textract.process('/tmp/'+str(key))
text = text.decode("utf-8")
return text
except Exception as e:
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
Installing dependencies for Textract
Since this involves installation of dependencies, there are two ways of going about the same :
1. Deploy .zip file archive
The deployment package for a .zip file archive can be created using a built-in .zip file archive utility or any other .zip file utility from the command line.
This is allowed upto 50 MB (for zipped, direct upload) and 250 MB (unzipped).
2. Deploy container image
Lambda supports container images upto 10 GB in size.
The dependencies required by Textract go beyond the 250 MB limit, hence the second option has been chosen for integration with AWS Lambda.
Dockerfile for Installing Textract Dependencies
The dockerfile can be created using two kinds of base images.
1. Using AWS base image for Lambda
This runs on top of Amazon Linux and creates problems if packages are not readily installed. For example, installation of antiword which is a prerequisite for processing of doc files using textract is quite challenging on Amazon Linux.
2. Using an alternative base image
In this case, another image is chosen as the base image and installation is done on top of that. This connects to Lambda using a runtime interface client which is installed separately.
For example, antiword installation works successfully on base image python:buster which is Ubuntu based.
The entire docker file is shown below.
# Define function directory
ARG FUNCTION_DIR="/function"
FROM python:buster as build-image
# Install aws-lambda-cpp build dependencies
RUN apt-get update && \
apt-get install -y \
python3-pip \
apt-utils \
g++ \
make \
cmake \
unzip \
libcurl4-openssl-dev \
python-dev \
libxml2-dev \
libxslt1-dev \
unrtf \
poppler-utils \
tesseract-ocr \
flac \
ffmpeg \
lame \
libmad0 \
libsox-fmt-mp3 \
sox \
libjpeg-dev \
swig \
zlib1g-dev
RUN apt-get install -y apt-utils
RUN apt-get install -y antiword
RUN pip install --upgrade pip && \
pip install boto3 && \
pip install textract
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Create function directory
RUN mkdir -p ${FUNCTION_DIR}
# Copy function code
COPY app/* ${FUNCTION_DIR}
# Install the runtime interface client
RUN pip install \
--target ${FUNCTION_DIR} \
awslambdaric \
boto3 \
textract
# Multi-stage build: grab a fresh copy of the base image
FROM python:buster
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Set working directory to function root directory
WORKDIR ${FUNCTION_DIR}
# Copy in the build image dependencies
COPY --from=build-image ${FUNCTION_DIR} ${FUNCTION_DIR}
RUN apt-get update
RUN apt-get install -y apt-utils
RUN apt-get install -y antiword
ENTRYPOINT [ "/usr/local/bin/python", "-m", "awslambdaric" ]
CMD [ "app.handler" ]
Generating Docker Image and Integrating with AWS Lambda
To create an image from an AWS base image for Lambda. You need to follow the below steps:
- The below image shows the structure of the project folder.
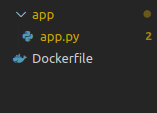 [/vc_column_text][vc_column_text]i) First, we have to create one project folder in the local machine.
[/vc_column_text][vc_column_text]i) First, we have to create one project folder in the local machine.
ii) In the project folder, create a subdirectory named ‘app’.
iii) In the subfolder, create an app.py file.
iv) Create Dockerfile and the first letter should be capital.
1) App.py: In app.py the code format is as shown below
In app.py which consists of the lambda_handler function, we have to write the code for extracting text from Doc by using the textract package. Apart from extracting, it also consists of triggering the Lambda with S3 Bucket.
This is the same code as presented under the section ‘Running Textract on AWS Lambda’
a) The command to build Docker image with docker build:
Enter a name for the image after -t.
Here, doc-process is the image name
docker build -t doc-process
b) To Authenticate the Docker CLI to your Amazon ECR registry.
aws ecr get-login-password –region us-east-1 | docker login –username AWS –password-stdin 123456789012.dkr.ecr.us-east-1.amazonaws.com
c) To Tag and deploy the image to ECR paste the commands as shown below:
docker tag doc-process: latest 123456789012.dkr.ecr.us-east-1.amazonaws.com/doc-process:latest
docker push 123456789012.dkr.ecr.us-east-1.amazonaws.com/doc-process:latest
You get the above commands when you create the repository manually or with a command.
By using command:
aws ecr create-repository –repository-name doc-process –image-scanning-configuration scanOnPush=true –image-tag-mutability MUTABLE
Here, we are creating a repository with the image name doc-process
To do it manually – Go to AWS ECR https://ap-south-1.console.aws.amazon.com/ecr/home?region=ap-south-1 and click on create a repository to create a new repository as shown below image


Next, from the AWS Lambda, deploy the latest image. For that, we have to follow the below steps:
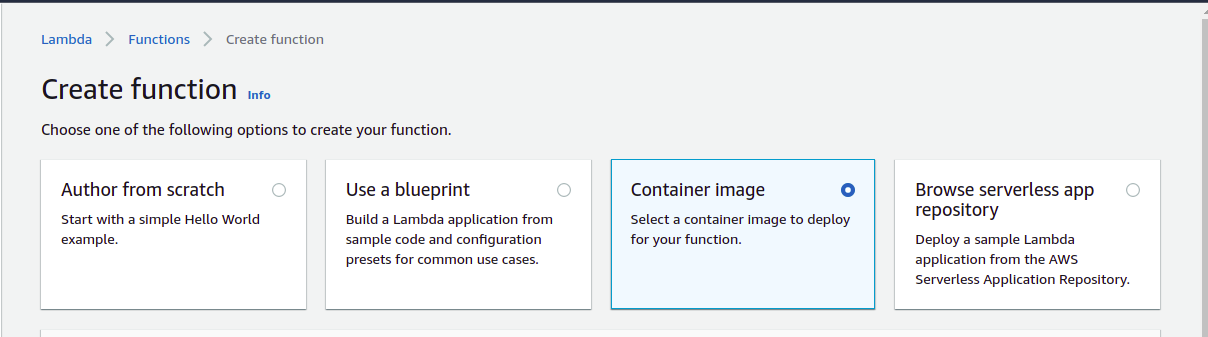
1) Click on ‘create function’ to create a new Lambda function.

2) Click on Container Image.
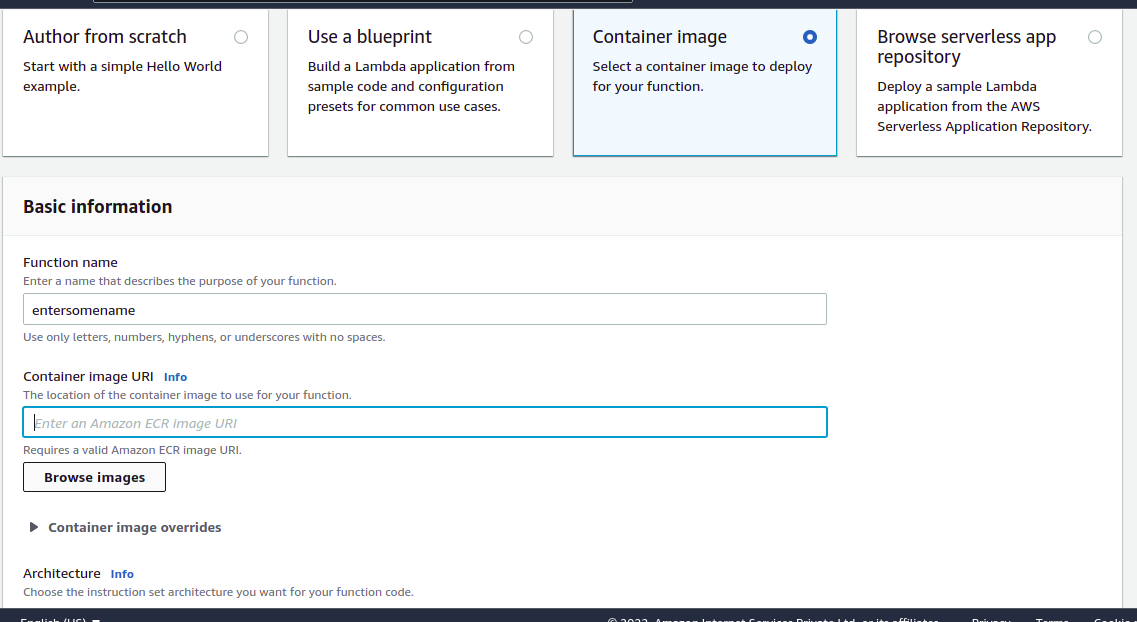
3) Enter the name in the ‘Function name’ cell.
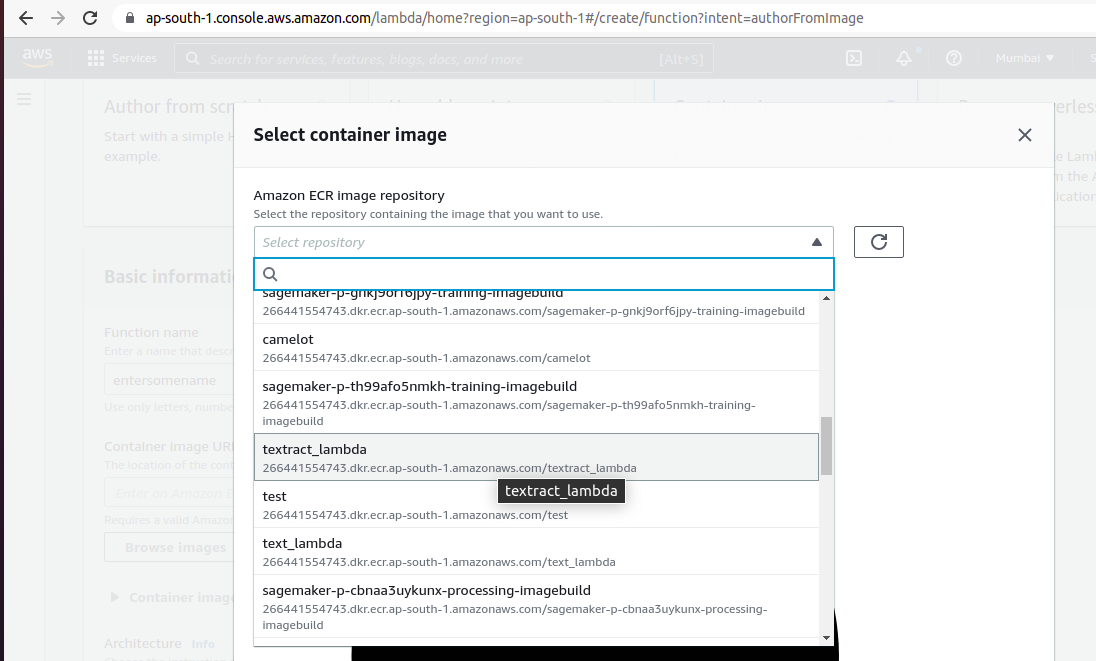
4) Click on Browse images and select the container image that you created.
5) Select the latest image and click on ‘Select image’.
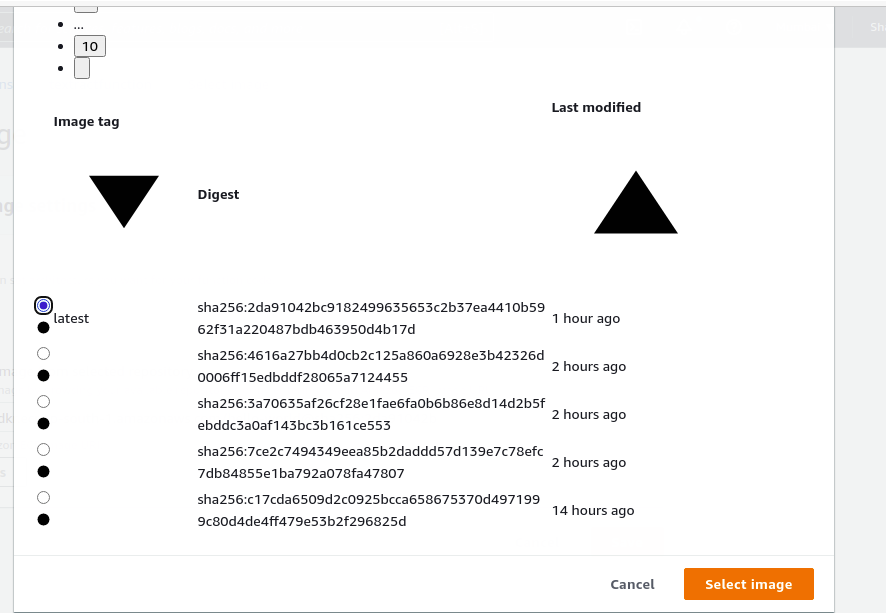 6) Click on the ’Save’ button.
6) Click on the ’Save’ button.
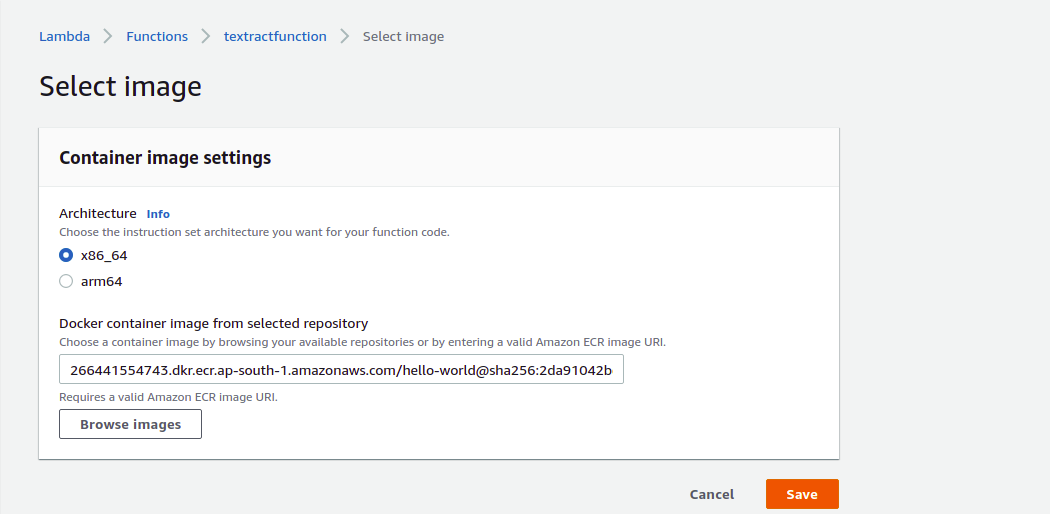
7) Click on ‘Create function’.
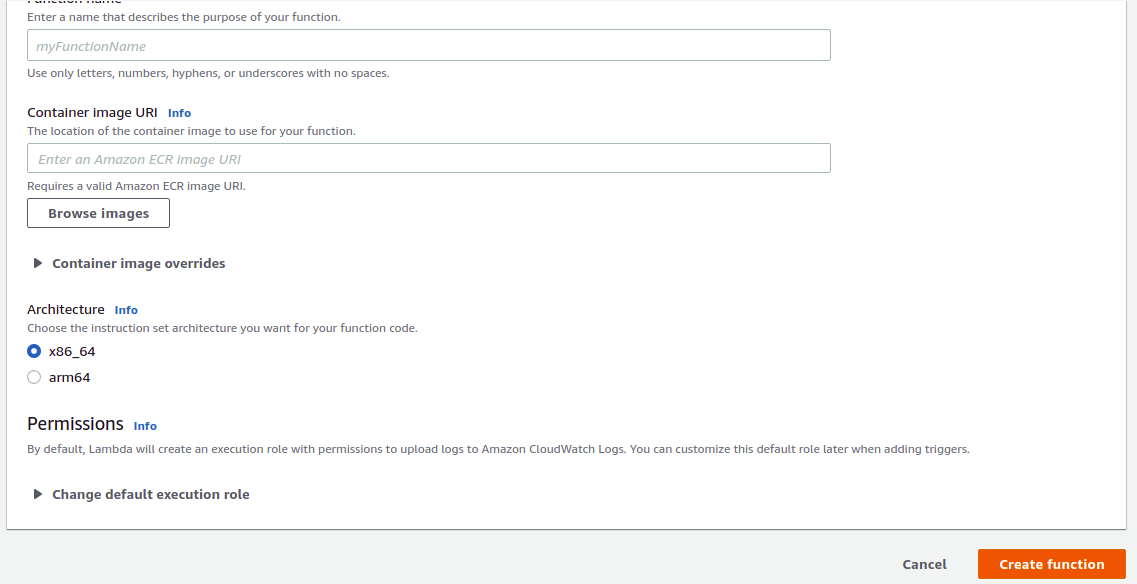
8) Click on ‘Add trigger’.
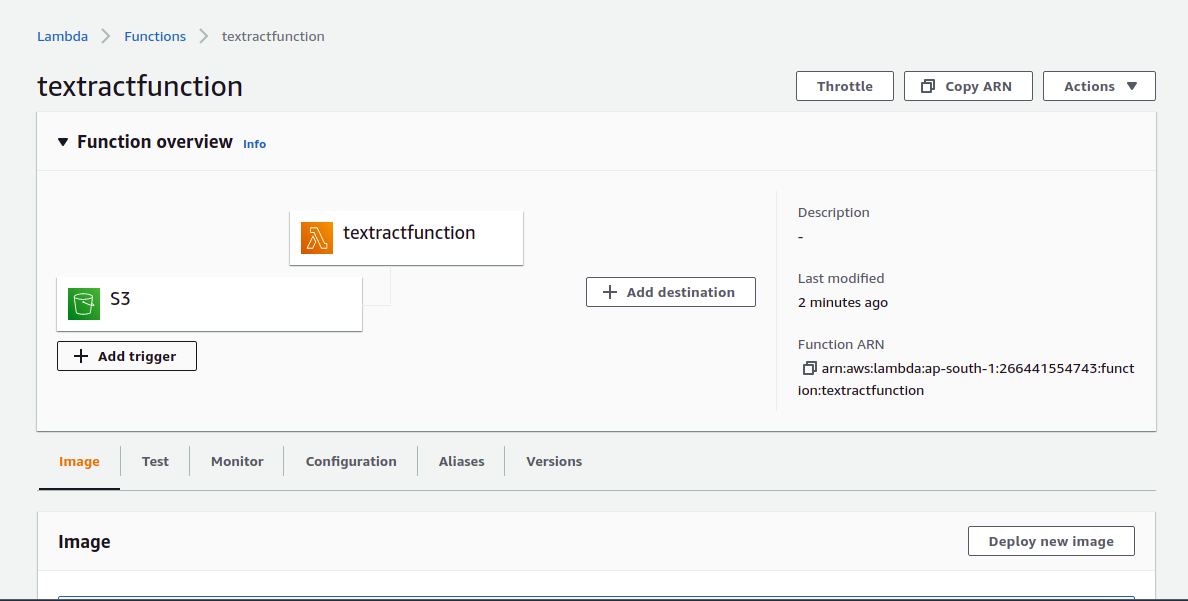
9) From Trigger configuration, select S3.
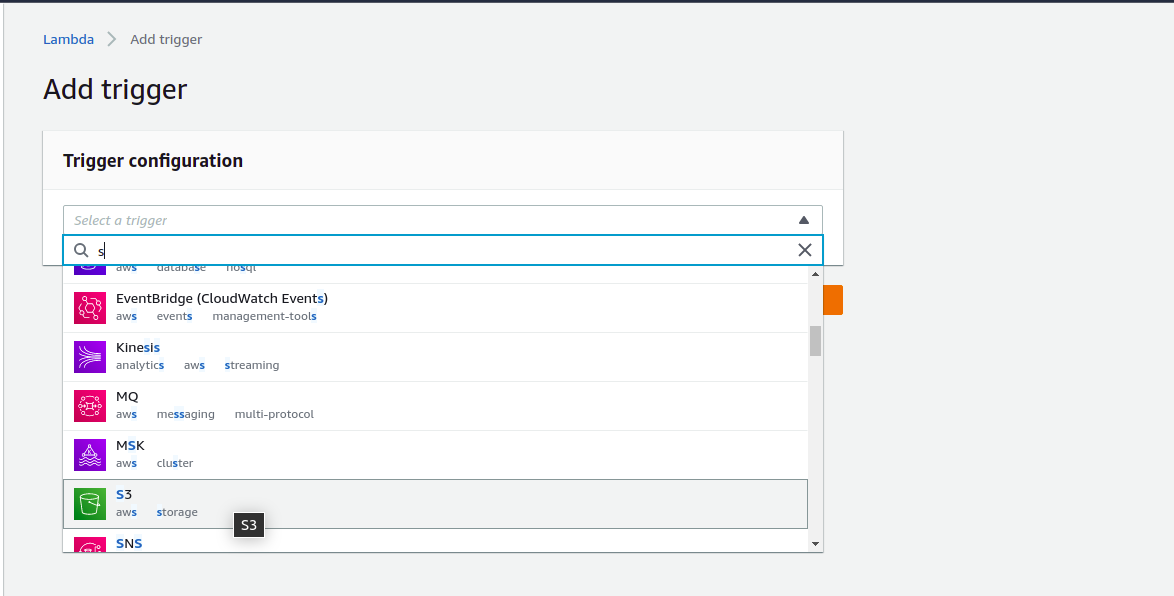
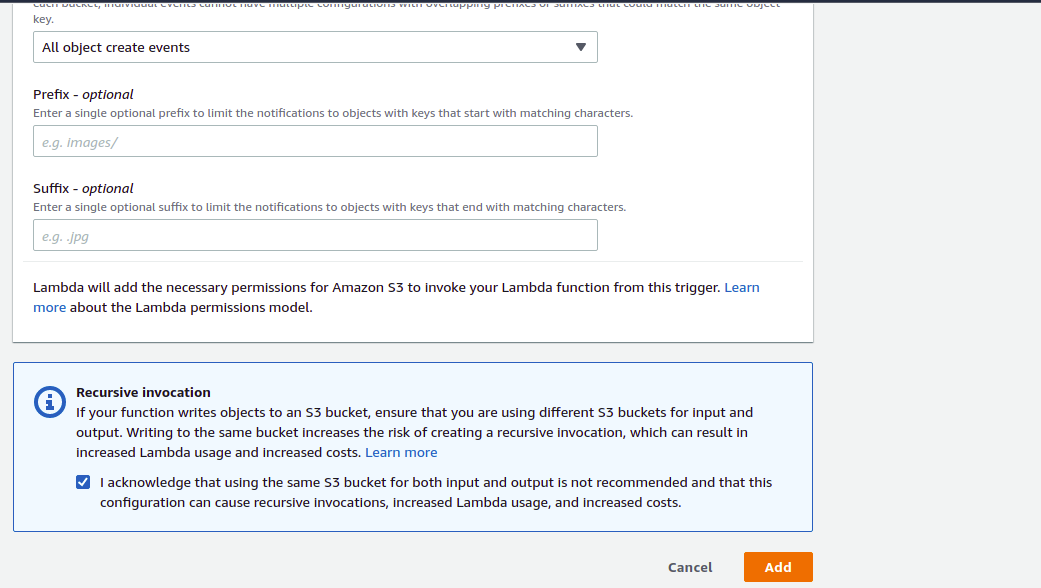
10) Give permission to – All object create events and click on the checkbox and then on the ‘Add’ button.
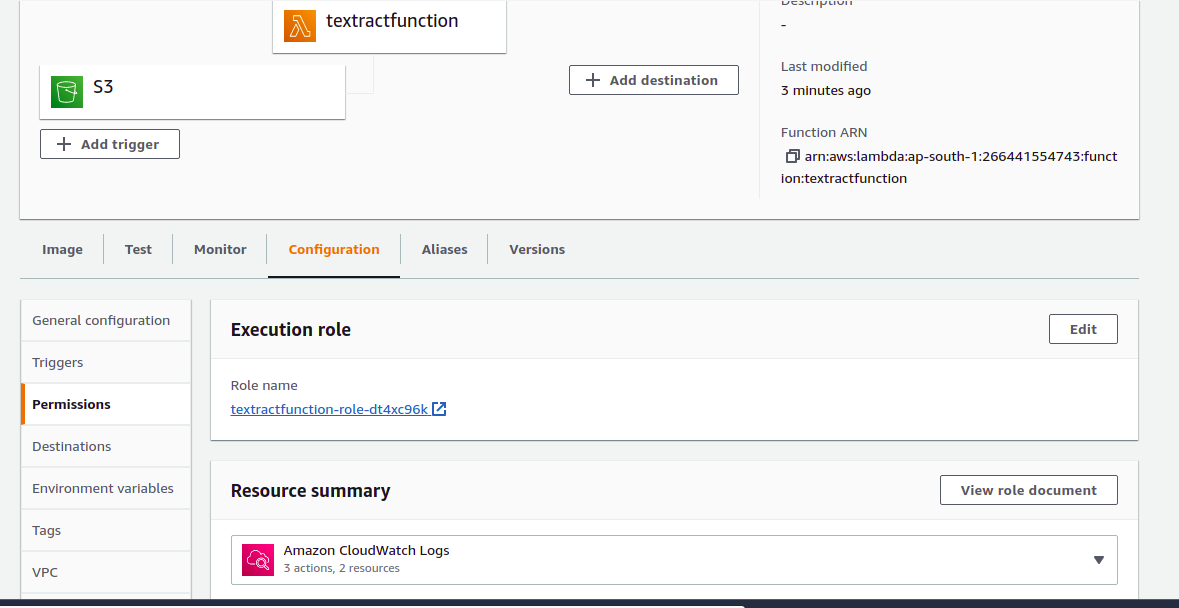
11) Give permission to the role.
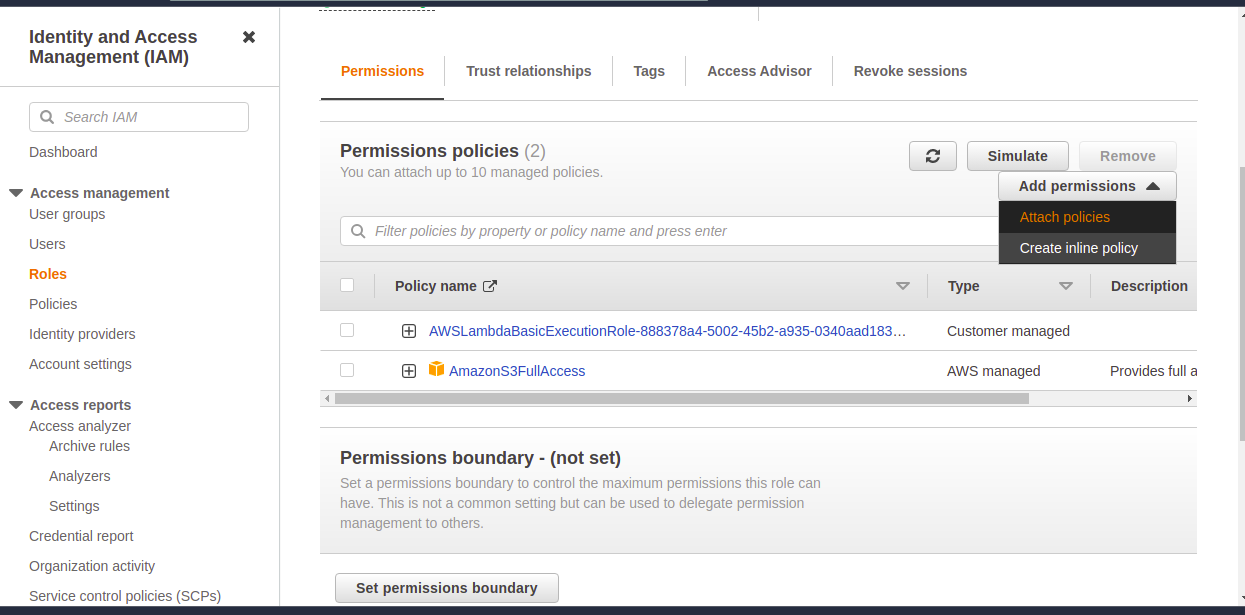
12) Add Amazon S3 FullAccess by clicking on ‘Attach policies’. You will get access.
13) Click on test button for testing.
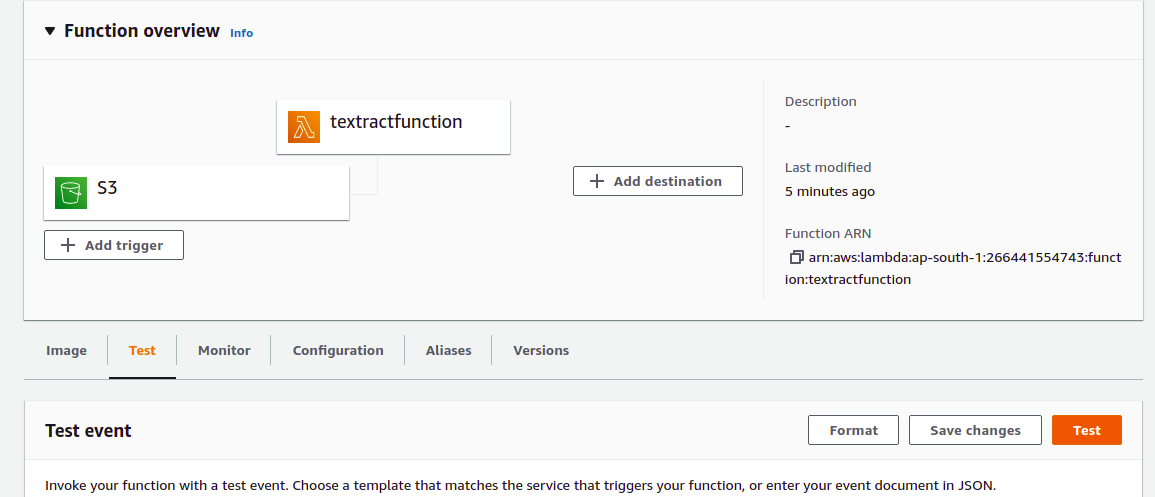
14) You will get the output as shown below.
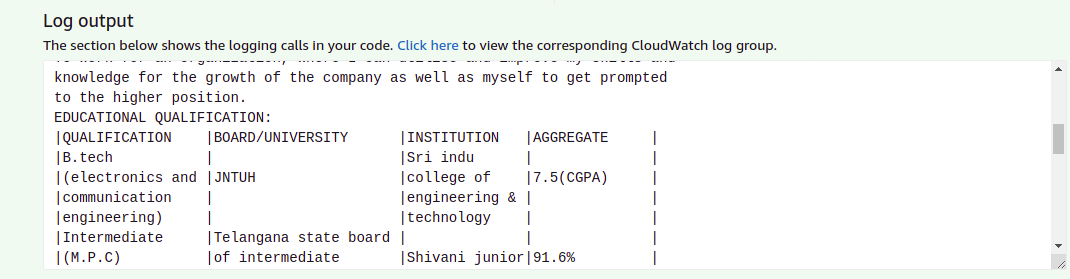
How to Handle Errors while Creating Images and Extracting Text
1) Got permission denied while trying to connect to the Docker daemon socket at
unix:///var/run/docker.sock: Get “http://%2Fvar%2Frun%2Fdocker.sock/v1.24/images/json”: dial unix /var/run/docker.sock: connect: permission denied
Ans: sudo chmod 666 /var/run/docker.sock
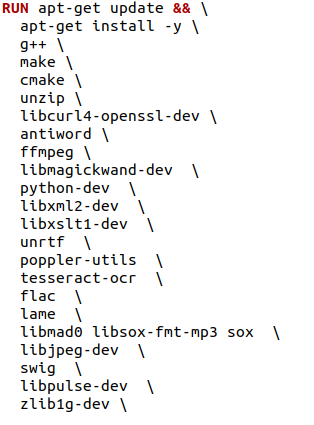
2) Unable to locate package ARG & Unable to Locate package Function_DIR

Ans: This error Occurs when we give backslash (\) at the end of the last package RUN (Last line of RUN)
ex:
3) When image is pushed to ECR
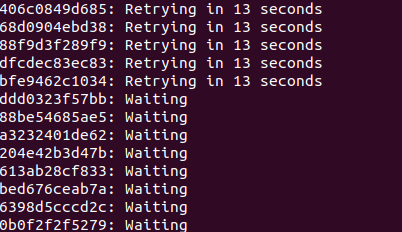
when does it occur ?
Ans: Network issue or login to ECR is not done.
4) When the folder is in the lock mode, change to unlock mode using this command
Ans: sudo chmod 777 -R /path-to-folder-or-file
5) no basic auth credentials
Ans: aws ecr get-login-password –region us-east-1 | docker login –username AWS –password-stdin 123456789012.dkr.ecr.us-east-1.amazonaws.com
(This is the first command by clicking viewPushCommand after creating your repository in ECR)
6) Unable to import app.no module named <filename>or<modulename>
ex: unable to import app.no module named boto3
Ans: RUN pip install \
–target ${FUNCTION_DIR} \
awslambdaric
Conclusion
In this blog, we discussed how to extract data from .doc files using textract. Since the package dependencies were greater than 250 MB, the solution had to be integrated with AWS Lambda using a docker image. This image was created on top of the Ubuntu based Python buster image, and integration with the Lambda interface was done using the runtime interface client.
The process was discussed end-to-end. Suggestions to resolve some commonly encountered errors were also provided.
References
1)https://docs.aws.amazon.com/lambda/latest/dg/python-image.html
