Blogs
Redefining Efficiency: Navigating Intelligent Process Automation through Autogen RAG
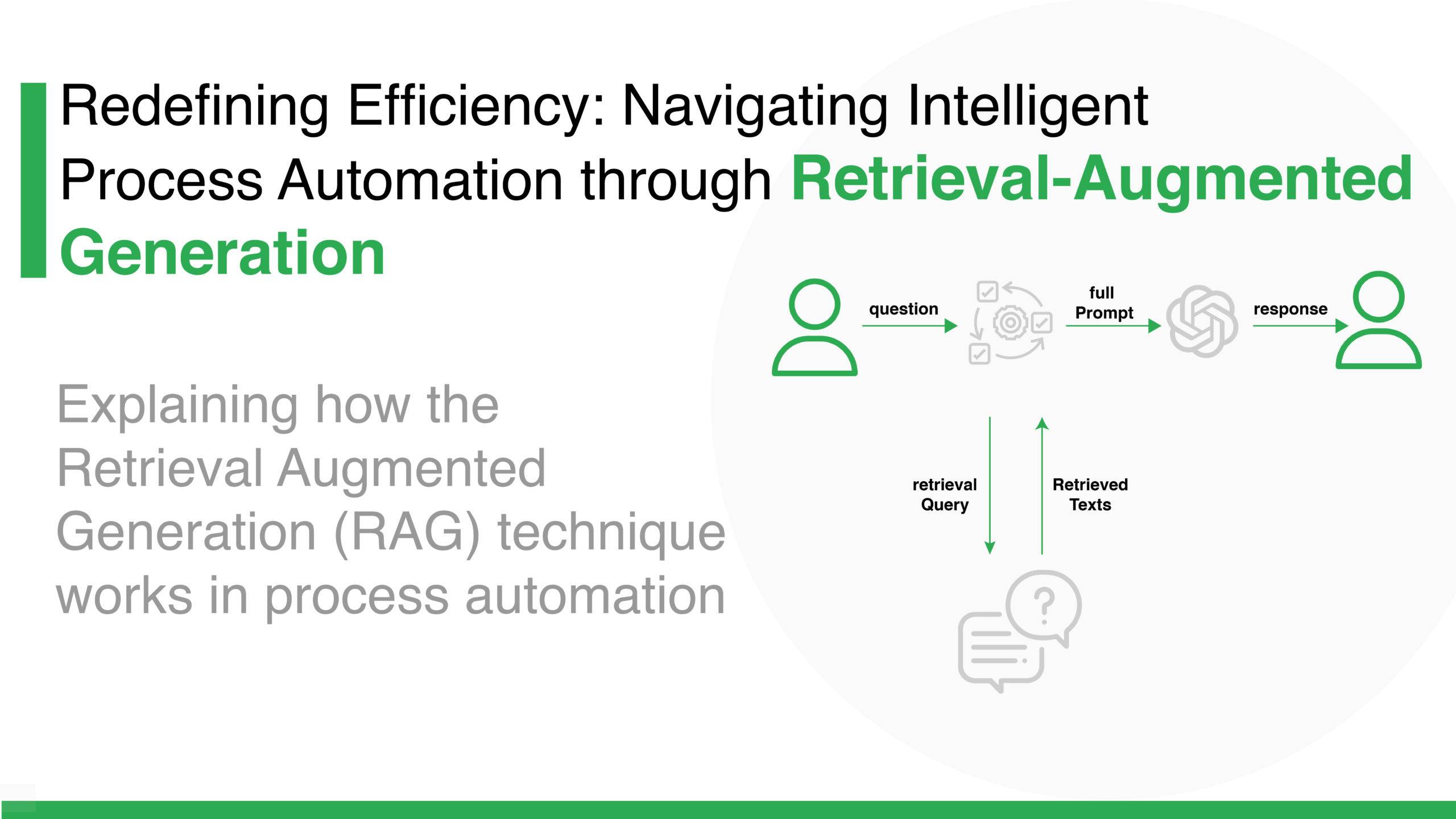
Most automation systems today still run on brittle logic. If this happens, do that. If a form looks like this, route it there. That model worked when business processes were slow, structured, and predictable. But that world is gone.
Modern enterprises operate on messy, fast-moving, unstructured information spread across documents, databases, emails, regulations, and live systems. The gap between how businesses actually work and how automation systems think keeps getting wider. That is where Autogen RAG changes everything.
At its core, Autogen RAG brings together large language models and Retrieval-Augmented Generation so AI can reason over real, external knowledge instead of guessing based on training data alone. The result is a system that does not just generate text but makes informed, data-grounded decisions in real time.
What this really means is simple but profound. Automation stops being scripted and starts becoming intelligent.
| Why Autogen RAG is different from traditional AI
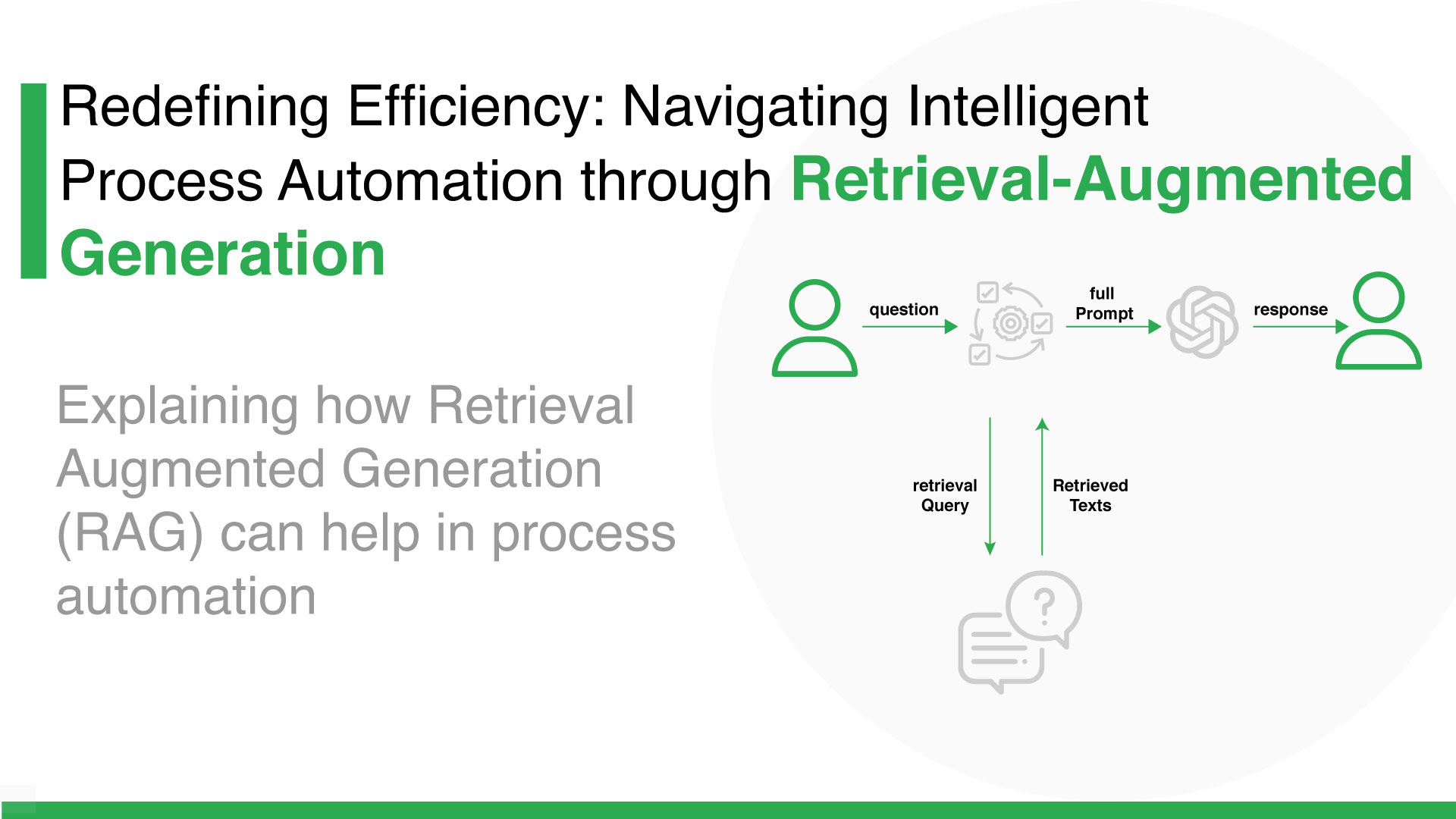
Traditional AI systems are trained once and then frozen. Whatever they learned during training is what they know. If something changes, new regulations, new market data, new policies, they are blind until they are retrained.
Retrieval-Augmented Generation breaks that limitation.
Instead of forcing a model to memorize everything, RAG lets it fetch the right information at the moment it is needed. Autogen RAG takes this one step further by embedding that retrieval and reasoning inside agent-driven workflows, allowing AI systems to act, verify, and adapt in real time.
This is what makes RAG enterprise-ready. It gives organizations a way to build AI that can:
- Read their own data
- Understand context
- Make decisions based on facts
- And explain why those decisions were made
| How Autogen RAG actually works
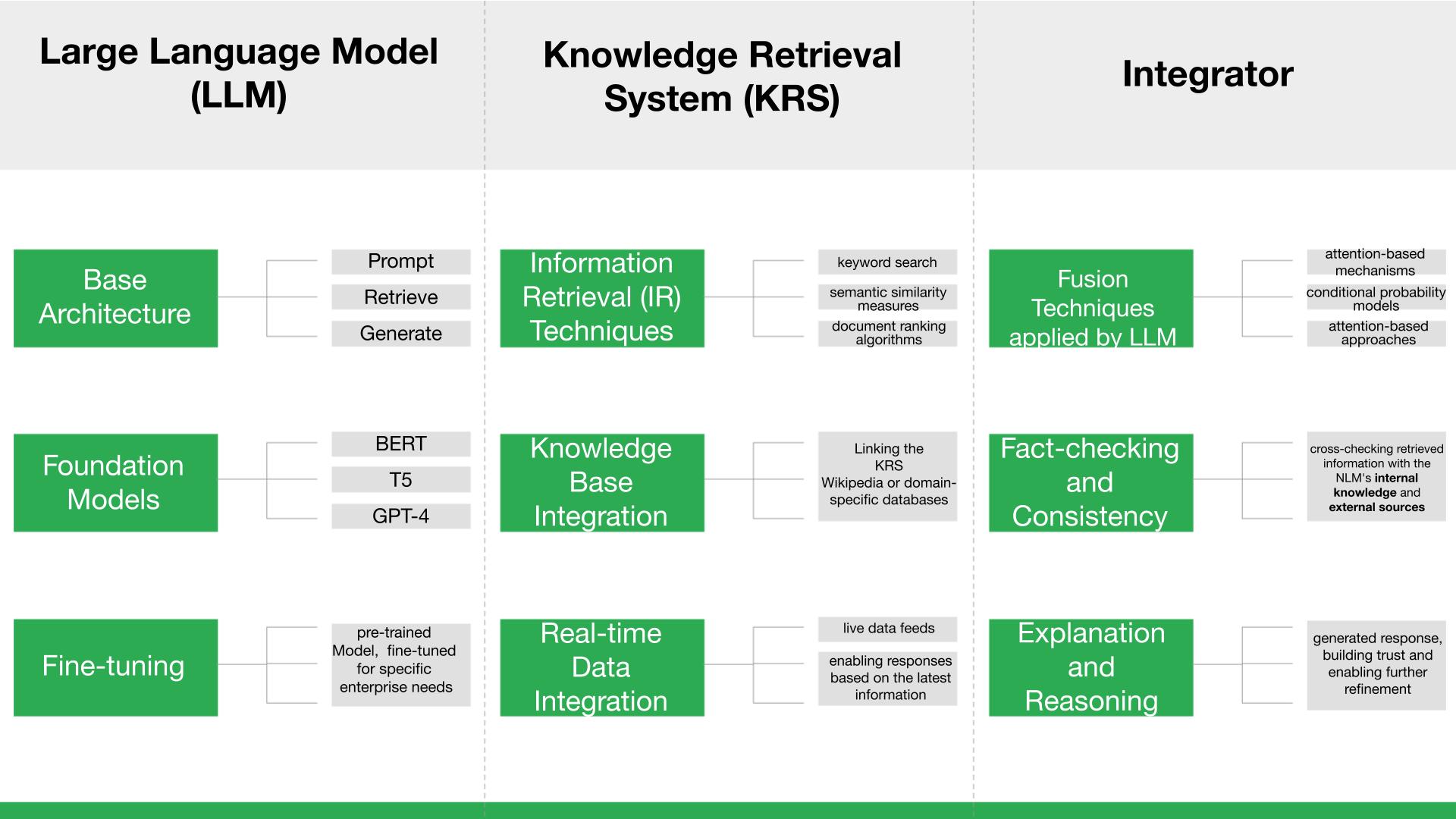
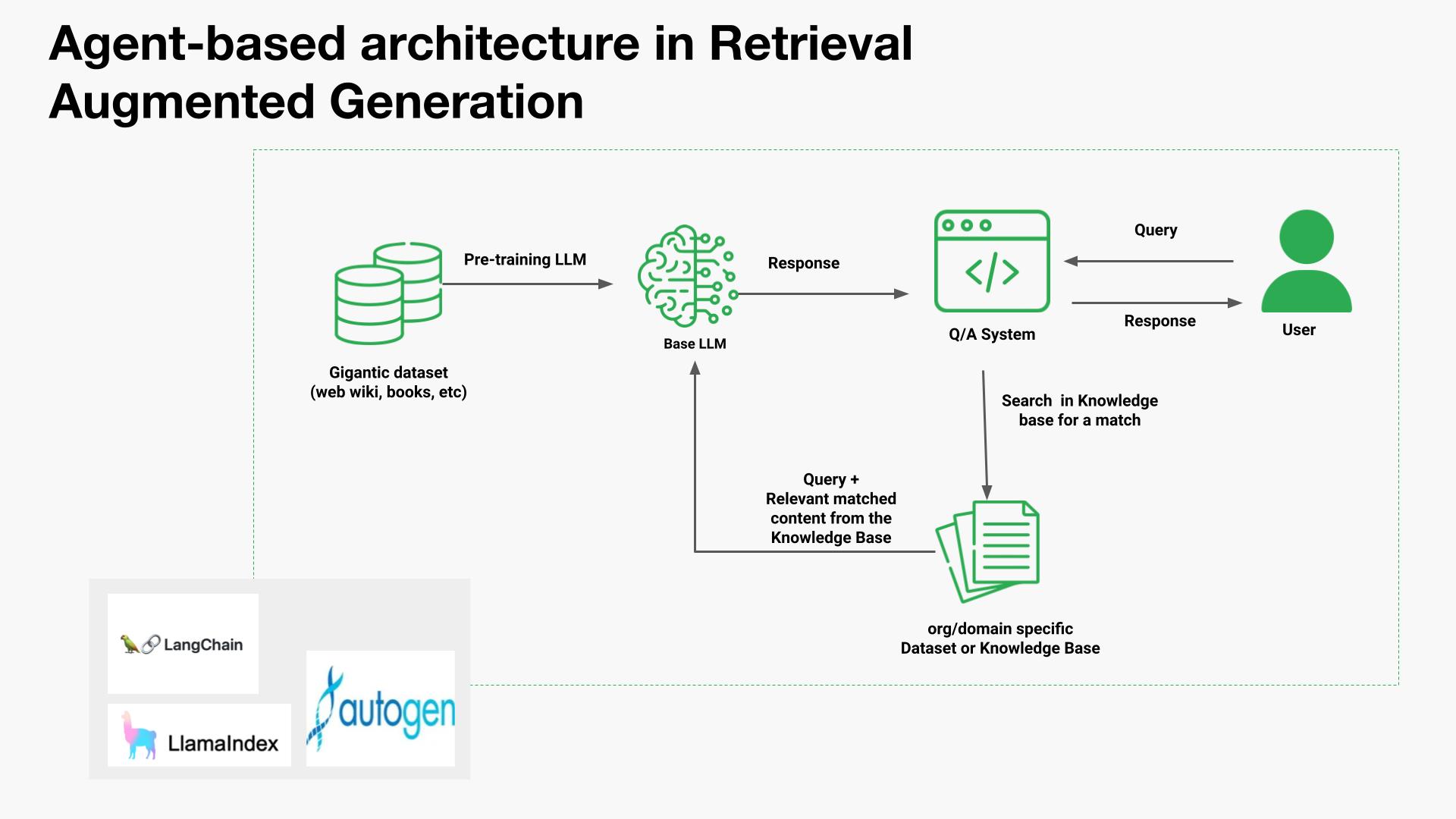
To understand the power of Autogen RAG, you need to look inside the engine. It is built on three tightly coupled layers.
1. The Large Language Model
The LLM is the reasoning brain. It takes a user request, interprets it, and decides what information is needed to answer it.
Because it uses transformer architectures, the model can focus on the most relevant parts of both the question and the retrieved documents. This allows it to generate responses that are not only fluent but contextually precise.
Different models such as BERT, T5, or OpenAI’s GPT-4 can be used depending on the task. In regulated or technical industries, models can also be fine-tuned on domain-specific data so the system speaks the language of finance, healthcare, or law.
But the model alone is not enough. That is where Retrieval-Augmented Generation comes in.
2. The Knowledge Retrieval System
This layer decides what information the model is allowed to see.
Instead of relying on static training data, Autogen RAG pulls content from:
- Enterprise document repositories
- Databases
- Knowledge graphs
- Wikis
- Real-time data feeds
Modern retrieval systems use a mix of keyword search, semantic similarity, and ranking algorithms to find the most relevant passages. This ensures that the LLM is not flooded with noise but receives the exact context it needs to answer correctly.
When live data is added, financial markets, inventory systems, compliance rules, the AI can reason over what is happening right now, not last year.
3. The Integrator
This is where intelligence is enforced.
The integrator combines the LLM’s reasoning with the retrieved content, checks for consistency, and ensures factual alignment. It can compare multiple sources, validate claims, and even provide explanations for why an answer was produced.
In enterprise-grade Autogen RAG, this layer often includes a post-processing step that evaluates confidence and triggers re-generation if the output looks weak or inconsistent.
That feedback loop is what turns RAG from a demo into a production system.
| Measuring whether Autogen RAG is actually working
One of the biggest mistakes companies make is assuming that if an answer sounds good, it must be correct.
That is not how Retrieval-Augmented Generation should be evaluated.
Frameworks like RAGAS and LangSmith allow teams to score every part of the pipeline using metrics such as:
- Context relevancy
- Context recall
- Faithfulness
- Answer correctness
These metrics show whether the model used the right data, ignored irrelevant content, and grounded its output in facts. In regulated industries, this is not optional. It is the only way to trust the system.
| What Autogen RAG enables in the real world
![]()
When you combine Autogen RAG with agent-based orchestration, you get AI systems that behave like domain specialists.
In insurance, these agents can pull policy documents, historical claims, and customer profiles to personalize coverage and accelerate claim decisions.
In finance, they can scan market data, detect anomalies, and generate investment insights based on live signals rather than stale reports.
In healthcare, they can compare patient histories with clinical research to support diagnosis and treatment planning.
In supply chains, they can monitor weather, traffic, and demand patterns to optimize routing and inventory.
In legal and compliance, they can retrieve case law, regulations, and internal policies to speed up reviews and reduce risk.
What ties all of this together is Retrieval-Augmented Generation. The AI is no longer inventing answers. It is citing them.
| Where agents fit into Autogen RAG
Agents are what turn RAG into action.
Platforms like LangChain, LlamaIndex, and OpenAI Assistants allow LLMs to call tools, query databases, and interact with documents. In Autogen RAG, agents are assigned roles and equipped with specific toolkits.
One powerful pattern is the multi-document agent architecture. Each document gets its own agent with:
- A vector index for semantic search
- A summary index for fast understanding
A master agent then routes queries to the right document agents and merges their outputs into a single response. This allows the system to compare sources, resolve conflicts, and synthesize insights across large document collections.
That is how enterprise search becomes enterprise intelligence.
| The risks that must be managed
No system is without risk.
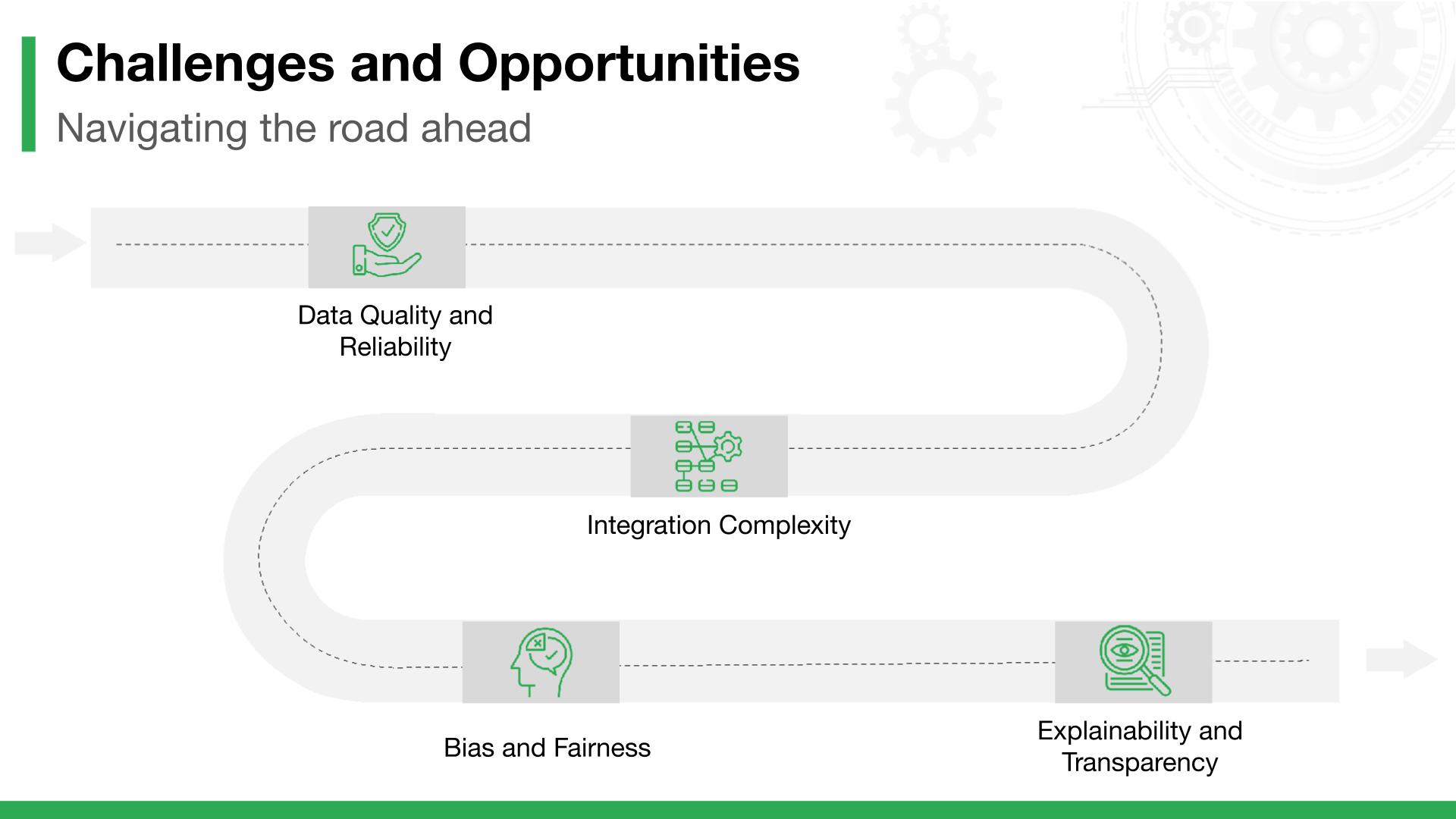
If bad data enters a Retrieval-Augmented Generation pipeline, bad decisions will come out. If biased data is used, bias will be amplified. If reasoning is opaque, trust will be lost.
That is why serious Autogen RAG deployments include:
- Verified data sources
- Continuous monitoring
- Bias detection
- Explainable outputs
These are not nice-to-have features. They are what make AI usable in high-stakes environments.
| The future is collaborative, not automated
The future is collaborative, not automated
The most important thing to understand about Autogen RAG is that it is not about replacing people. It is about removing the friction between humans and the knowledge they need to make decisions.
Humans define goals, apply judgment, and stay accountable.
AI handles retrieval, synthesis, and scale.
Together, they form a system that is faster, clearer, and more consistent than either could be alone.
That is the real promise of the Retrieval-Augmented Generation.
Not artificial intelligence.
But a new kind of collaborative intelligence that finally lets organisations move at the speed of their data.