


Blogs
Spark not a replacement but a complement to Hadoop
Introduction
Most people in Big Data are constantly surrounded by one doubt, whether Spark has surpassed Apache Hadoop and replaced it?
We would say Spark is more of a complement rather than a competitor of Hadoop. Let’s catch a brief look at what they can do best together.
Overview
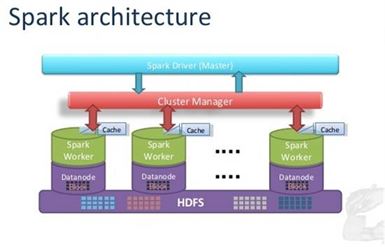
Framework View
Apache Hadoop and Spark are both Big Data frameworks, but they don’t really serve the same purpose.
Hadoop provides a distributed (HDFS) storage which is a fundamental need for today’s Big Data project as it allows parallel processing of massive distributed data across the multinodes with a cluster of commodity servers, rather than involving expensive custom machine to store all data in one place.
Spark, on the other hand, is an in-memory data processing tool that operates on the distributed data collection. Spark doesn’t have its own system for their files organization in the distributed manner, so it needs to be integrated with Hadoop HDFS or another cloud based data platform. For the very same reason many Big Data projects involve installing Spark on top of Hadoop, where Spark’s advanced analytics applications can make use of data stored using the Hadoop Distributed File System.
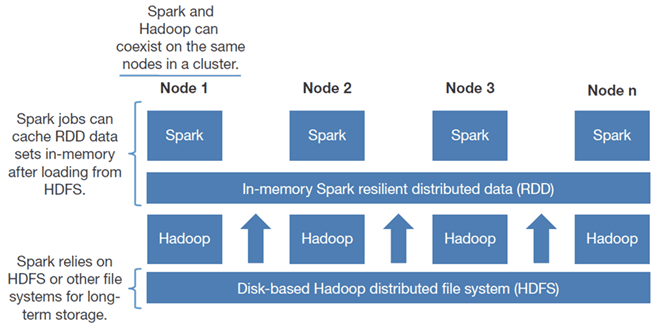
Speed and Performance Overview
Spark can be treated as an alternative to Hadoop MapReduce rather than a replacement to Hadoop. Spark handles most of its operations ‘in memory’ – copying them from the distributed physical storage into far faster logical RAM memory. Executing batch processing jobs in about 10 to 100 times faster than the Hadoop MapReduce framework just by merely cutting down on the number of reads and writes to the disc.
MapReduce does not leverage the memory of the Hadoop cluster to the maximum. In Spark, the concept of RDDs (Resilient Distributed Datasets) lets you save data on memory and preserve it to the disc if and only if it is required and as well it does not have any kind of synchronization barriers that could possibly slow down the process. Thus, the general execution engine of Spark is much faster than Hadoop MadReduce with the use of memory.
Reliability Factor
Hadoop uses replication to achieve fault tolerance whereas Spark uses a different data storage model: resilient distributed datasets (RDD), which cleverly guarantees fault tolerance that in its turn minimizes network I/O.
From the Spark academic paper: “RDDs achieve fault tolerance through a notion of lineage: if a partition of an RDD is lost, the RDD has enough information to rebuild just the partition.” This removes the need for replication to achieve fault tolerance.
Processing View
With Spark-Hadoop HDFS, it is possible to perform streaming, Batch Processing and Machine Learning all in the same cluster. With Spark, it is possible to control different kind of workloads. So, if there is an interaction between various workloads in the same process, it is easier to manage and secure such workloads, which is a limitation with MapReduce.
MapReduce’s processing style can be just fine if your data operations and reporting requirements are mostly static and you can afford to wait for batch-mode processing. But if you need to do analytics on streaming data, like from sensors on a factory floor, or have applications that require multiple operations, you probably want to go with Spark operations. Most machine-learning algorithms, for example, require multiple operations. Common applications for Spark include real-time marketing campaigns, online product recommendations, cyber security analytics, and machine log monitoring & fraud detection.
Conclusion
Hadoop & Spark – A perfect Big Data Framework
Spark, Hadoop – each bear a distinct feature and excel in various contexts like discussed above. However, it’ll turn out to be a real productive batch / interactive big data environment where you can process your data in minutes.
Few scenarios where both can add value to each other:
- Organization can take advantage of many of the Hadoop capabilities such as HDFS storage, cluster administration and data security by providing data management for spark processes and analysis pipeline workloads. Resource management of Spark can be accomplished via the Hadoop YARN resource manager, which handles scheduling tasks across available nodes in the cluster.
- Using Spark and Hadoop together helps users leverage the power of Machine Learning through MLib library. Machine Learning algorithms can be executed faster in-memory of Spark which resides on top of Hadoop HDFS cluster.
- Spark uses RDDs for faster data access which adds value to a Hadoop cluster by reducing time lags and enhancing performance. Whenever the system fails, RDDs can be computed using prior information.
- Spark’s agility, speed and comparable ease of use (in terms of development), very well complement Hadoop MapReduce’s low cost of operations on commodity hardware.
It is hence easy to conclude that Hadoop and Spark together makes an excellent Big Data infrastructure for quicker data processing and analytics maintenance, considering the demand or requirement of the use case





