


Blogs
Introduction to Hadoop
Introduction
In olden days elephants were used to carry heavy loads. But loads that need to be transported were getting heavier at tremendous pace. Our older generation was so vice that they did not look for bigger elephants to transport bigger load, instead they harnessed multiple elephants together and distributed load uni-formally and started transporting heavier loads.

With same analogy, the size of the data that needs to processed, understood and analyzed is increasing in tremendous pace day by day. Even high end servers are not in a position to handle this data in an effective way. Server configuration is not able to scale up with the pace of data size.

This is where Hadoop comes into the picture. Hadoop can be compared with a group of highly disciplined, well trained group of elephants which will work under single master. Hadoop is built for processing huge data by an uniform and planned distribution of work among multiple slaves.
Hadoop is a distributed, scalable and portable storage/computing system which supports large data processing and better fault tolerance.
Evolution( Year and Event)
- 2002 – Doug cutting & Mike Cafarella stated working on distributed data management system with project name ‘Nutch’
- 2004 – Mapreduce was added to Nutch
- 2006 – Hadoop spins out of Nutch
- 2008 – Hive was launched to give SQL support for hadoop
-
2009 – Hadoop was refactored to decouple Mapreduce and Hadoop Distributed File System
-
2010 – Hive, Pig, Avro and Hbase sub projects are added
-
2011 – Zookeeper added
Architecture:
Hadoop is master a slave architecture where master decides on who should what and slave will do the real the work and report to master.
Architecture Diagram:
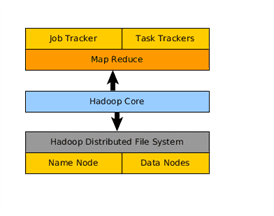 Hadoop typical cluster :
Hadoop typical cluster :
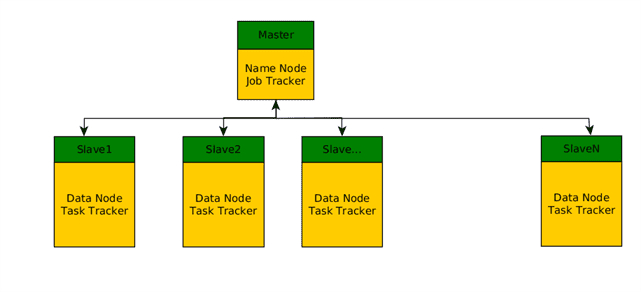 Applicable Domains :
Applicable Domains :
Hadoop can be used in all the functional domains where large data needs to be stored, processed and computed. Here we will cover the list of domains where hadoop is being used. Broadly we cover high level use cases in each domain
Social Networking:
Use of hadoop in various popular social networking sites
- For optimized data storage
- workflow solutions
Telecom:
- Customer usage patterns
- CDR(Call detail record) optimal storage and processing
Financial Services:
- Analyze existing data and provide accurate feedback about user in order to reduce risk
- Analyze the trends of trade
Healthcare:
- To store and maintain health records
- To analyze gene sequence
Media:
- TRP ratings
- Images archival and restore
Core components:
Hadoop Common
It is the base project of Hadoop and it takes care of communication among multiple other modules. It is one of the core components
Hadoop Distributed File System (HDFS)
-
- HDFS is a distributed, scalable and portable file system
- It has two main components i.e. Namenode and data node
- Namenode typically acts as a master and decides what data needs to be stored and where it should be stored
- Datanode is slave which has real data stored
- In case one of the data node is down, name node will pass instructions to for other node to store failures node data. This way it takes care of replication.
- It does not support concurrent write operations
- It is written in java
Hadoop MapReduce
-
- Map/Reduce is distributed, scalable computing framework
- It has two components i.e. Job tracker and task tracker
- Job tracker acts like master and send commands to slaves for specific task
- Task tracker will take care of real execution of task and report back to job tracker
- Map/Reduce programs will be written in java language
- Every program you write should have seperate map and reduce methods
Summary:
Hadoop is highly scalable and distributed storage/computing framework. It is being used in different domains and it is positioned well to play bigger in big data computing.
Hope you enjoyed reading this article.





