


Blogs
Decoding data using AWS Glue DataBrew

Building predictive models is a minor portion of a data scientist’s everyday work, as is well recognised in the data science community. In general 80 percent of the effort is spent analysing the data, cleaning it, and performing feature engineering.
Since data is a collection from multiple different sources, the task seems quite tedious and challenging when it comes to handling it. Even experts are finding it difficult to interpret and act on the ever-increasing quantities of real-time data.

Whatever tools an organization may use for analytics, it is important to have quality and reliable data to obtain the right and meaningful insights. Several factors contribute to the quality of data like accuracy, validity completeness, relevant timelines, consistency, etc. In this blog, we shall see:
- About AWS Glue
- AWS Glue DataBrew-its benefits and ease of use
- The capabilities of AWS Glue DataBrew
About AWS Glue

AWS Glue is a serverless data integration service that makes discovering, planning, and integrating data for analytics, machine learning, and application development simple. It is a completely managed ETL service that allows categorizing, cleaning, enriching, and efficiently moving data between different data stores and data streams easily, quickly, and cost-effectively. This event-driven, serverless computing platform is used to load data into your data warehouse or data lake from a variety of static and streaming data sources for routine reporting and analysis.
It entails a variety of activities, including data discovery and extraction from a variety of sources. It carries the process of data enrichment, cleansing, normalization, processing, and data loading from the organization’s databases, data warehouses, and data lakes. These activities are often performed by various groups of users, each of whom uses a different product. To make data integration simpler, AWS Glue offers both visual and code-based interfaces.
The AWS Glue Data Catalog helps users quickly locate and view data. With a few clicks in AWS Glue Studio, data engineers and ETL developers can visually build, run, and track ETL workflows. AWS Glue DataBrew allows data analysts and scientists to visually enrich, clean, and normalize data without writing code.
AWS Glue DataBrew
AWS Glue DataBrew is a data preparation tool, a graphical user interface that runs on top of AWS Glue. AWS Glue has been used by data engineers to build, run, and track extract, transform, and load (ETL) jobs for more than a decade. Data analysts and data scientists have been clamoring for a simpler way to clean and transform this data, and DataBrew addresses this requirement by enabling data exploration and testing directly using AWS data lakes, data warehouses, and databases without having to write code.
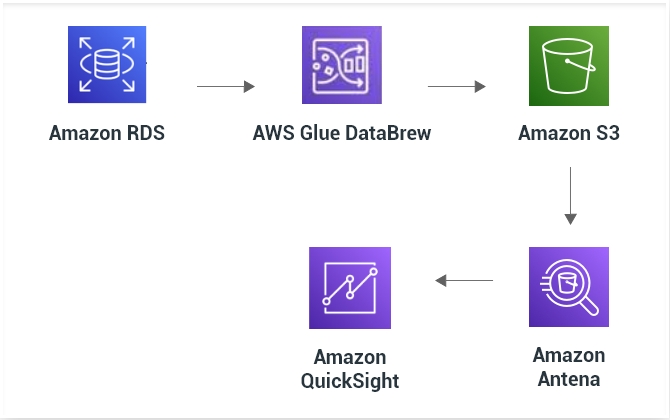
Orchestrating an AWS Glue DataBrew job
AWS Glue DataBrew is a user interface designed on top of AWS Glue, a data preparation and ETL service from Amazon Web Services. DataBrew uses clean data visualizations and seamless integration with other AWS services, such as S3 and Redshift, to make data discovery and planning easier for non-coders.
Customers can use AWS Glue DataBrew’s over 250 pre-built transformations to automate data preparation tasks (such as filtering anomalies, standardizing formats, and correcting invalid values) that would otherwise take days or weeks to write by hand. Data extraction, cleaning, normalization, loading, and the orchestration of ETL workflows at scale are all required and are time-consuming jobs. Data engineers and ETL developers who know SQL or programming languages like Python or Scala can use AWS Glue to extract, orchestrate, and load data at scale.
Making ETL easier with AWS Glue Studio
AWS Glue Studio is a visual interface to support writers, run, and monitor ETL jobs without having to write any code. ETL developers frequently prefer the visual interfaces popular in modern ETL tools over writing SQL, Python, or Scala, and we have AWS Glue Studio to help author, run, and monitor ETL jobs without having to write any code.
Data analysts and data scientists who work in the lines of business and understand the meaning of the data must clean and normalize the underlying data. Data analysts and data scientists work on small batches of data in Excel or Jupyter Notebooks, which can’t handle massive data sets. Sometimes rely on limited data engineers and ETL developers to write custom code to clean and normalize the data.
Slice and dice
Highly qualified data engineers and ETL developers spend days or weeks writing custom workflows to pull data from various sources, then pivot, transpose, and slice the data several times until iterating with data analysts or data scientists to find and correct data quality issues. After making these transformations, data engineers and ETL developers must schedule the custom workflows to run on a daily basis so that new incoming data can be cleaned and normalized automatically.
Every time a data analyst or data scientist needs to edit or add a transformation, the data engineers and ETL developers need to extract, load, clean, normalize, and orchestrate the data preparation jobs over again. The data engineers and ETL developers extract, load, clean, normalize, and orchestrate to prepare data for any time a data analyst or data scientist needs to modify or add a transformation. 80% of their time is spent cleaning and normalizing data instead of evaluating and extracting value from it because being an iterative process can take several weeks to months to complete. AWS Glue DataBrew helps with all these tasks without writing any code using an interactive, point-and-click visual interface.
The 250 plus built-in functions allow customers to play around with data without writing code. Filtering anomalies, normalizing data to regular date and time values, creating aggregates for analyses, and correcting invalid, misclassified, or duplicate data are all measures recommended by AWS Glue DataBrew.
This new visual data preparation tool additionally offers transformations that use advanced machine learning methods like Natural Language Processing to make complex tasks easier. It eases translating words to a common base or root word (e.g., converting “regularly” and “regularized” to “regular”) (NLP).
These cleaning and normalization steps can then be stored as a workflow (called a recipe) which are applied to future incoming data. For any required improvements to the workflow, data analysts and data scientists simply update the recipe’s cleaning and normalization measures. The recipe is then applied to new data as it arrives.
AWS Glue DataBrew publishes the prepared data to Amazon S3, making it simple for consumers to use in analytics and machine learning right away. Customers never have to configure, provision, or handle any computing resources with AWS Glue DataBrew since it is serverless and fully controlled. For data preparation, we use a DataBrew job; for data refresh, we use a series of Athena queries; and for business reporting, we use Amazon QuickSight.
The capabilities of AWS Glue DataBrew
Profile
Connect data from your data lake, data warehouses, and databases to evaluate its quality by profiling it to understand data trends and detect anomalies.
Clean and Normalize
With an immersive, point-and-click visual interface, choose from over 250 built-in transformations to visualize, clean, and normalize your data.
Map Data Lineage
To read the various data sources and transformation steps, visually map the lineage of the data that has been through.
Automate
Automate data cleaning and normalization tasks. Do this by applying saving transformations to new data as it comes into your source system.
To know more read here: How AWS Glue DataBrew Works
To sum up…

Duplicate values, inaccurate encoding, and other flaws in the data ingested into the data lake make it impossible to use in its raw form. A solution like DataBrew enables data analysts to visually analyze massive data sets, clean and enrich data, and perform advanced transformations. AWS Glue DataBrew will help our analysts and data scientists to perform advanced data engineering tasks, enabling them to freely explore their data and shortening the time it takes to derive new insights. Nevertheless, this technology advancement leads analysts to provide meaningful insights to businesses for growth and enhancements.




