


Blogs
An Executive’s Approach to Machine Learning – Part 1

Machine learning has been closely observed and implemented by the executive community across the globe. As the computing power of machines increases every minute, organizations can automate tons of applications. As a result, there is an increased expectation for machines to solve problems that were being exclusively solved by humans in the past. This leads to huge demand and a real ‘Hype Cycle’ for machine learning. ‘Hype Cycle’ is not a new word in machine learning, but it is picking up really fast and going to rule the roost in the years to come. Every aspect of our lives will be impacted by this and we will witness serious restructuring on the way we work, engage and harness the computing power of machines now and the years to come.
This blog will primarily focus on how we wrap our minds around machine learning and what kind of problems we as executives should aim to solve using machine learning. We will also look at how machine learning can be used to bring prosperity in every aspect of our lives.
Defining Machine Learning
Machine Learning was originated with the basic question of ‘Can machines think’ by Alan Turning. Later Arthur Samuel slightly modified this question “Can machines do what we (as thinking entities) can do?” to make it more relevant. This question is the origin of machine learning and later evolved to the magnificent possibilities that we experience in the computing world today.
Data Science and Artificial Intelligence are two more popular buzzwords that we hear along with machine learning. Many wonder about the correlation between machine learning, data science, and machine learning. Are these items subsets for one another? Are they independent with some connectivity? Let us try and simplify these seemingly complex technologies into intelligible data.
Data “Science”
Modern technology has made it possible to create and store a humongous amount of data. According to the research, 90% of the data available in the world was created in just the last two years. Just think about this interesting fact…Facebook users upload approximately 10 million photos every hour. The wealth of data being created and stored can drive immense benefits for an organization and industries, but only if this can be interpreted. This is where data science comes into the picture. Anything to qualify to be a science needs to have a specific set of attributes to be called “Science” or “Scientific” way of doing certain things. Here are some of the most relevant attributes in Data Science.
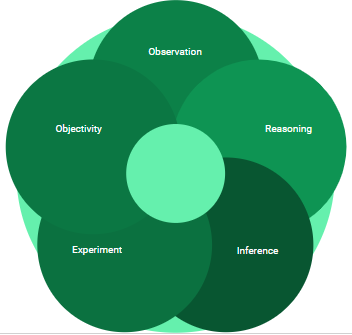
One of the first attributes is observation, for example, the falling apple. Sir Isaac Newton observed the falling apple and then reasoned, inferred, experimented, objectively accepted the facts and established the law of gravity over a period of few years. The attributes remain the same today as well.
Machine Learning
If you type in “Machine Learning” in google or any other search engine, you will end up opening a pandora box of academic research, forums, blogs and much more content which may further confuse you. There’s also a lot of hearsay stuff about machine learning written by ones that do not understand the symbiotic existence of machine learning, artificial intelligence, and data science. As an executive, you are definitely looking for a succinct overview of machine learning and how it will help your business propel further.
In simple words, as the name gives it away, machine learning is a science wherein the machines (computers) learn. The purpose is to implement the elements of data science into the machine’s learning ability and replicate the actions and learnings of a human in a machine. In machine learning, the data is fed to computers over a period of time with real-world scenarios and observations. Over time, the machine’s learning ability is improved in an autonomous fashion.
Regardless of the function of the learning style of machine learning, the three common aspects of machine learning are:
Evaluation II Optimization II Representation
Artificial Intelligence
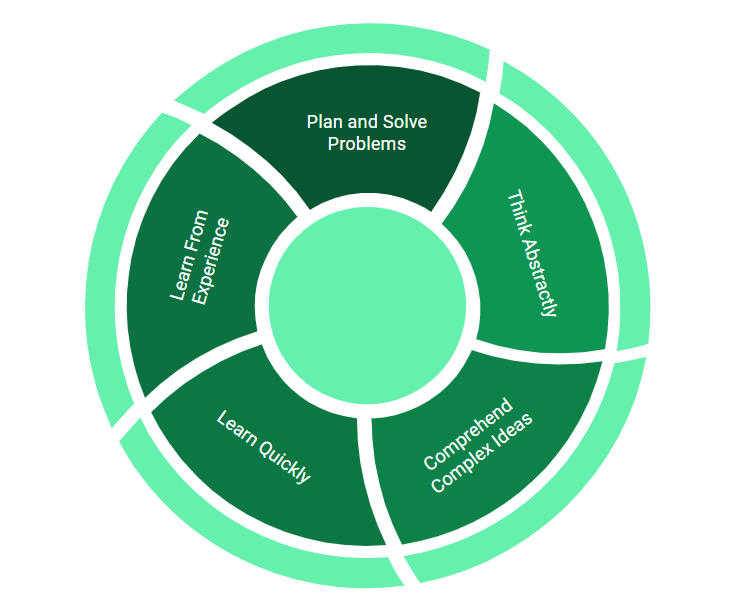
Intelligence is defined with 5 attributes –
- Plan and solve problems: As the name very well defines, this means to plan about a situation and solve the problem at the right time.
- Think abstractly: This means to think about something that is not physically or really present in front of you. You may have a question as to why the earth is in the current shape right now? Why is there gravity on the earth? We are not able to see gravity but we have a question around it. This is to think abstractly. So even though something is not physically present, we still are able to think about it and try to understand it.
- Comprehend complex ideas: So if there are complex ideas that come to your mind, you will be able to explain it in a certain language.
- Learn quickly: As the name defines, it means to learn quickly and based on past experience.
- Learn from experience: If you can derive some learning and apply some learning in the next task then that’s another ability.
So if you combine all these 5 abilities that are called intelligence. Applying that intelligence or bringing that intelligent concepts in the machine is called “Artificial Intelligence.”
Crisp Definition: Data Science, Machine Learning, Artificial Intelligence
- Data Science: We have data storage with data lying there but extracting knowledge from data is called “Data Science.”
- Machine Learning: Machine learning is the ability to learn from experience and increase the success rate of the prediction. This means, as you start learning more and more, you should be more successful in carrying out certain tasks.
- Artificial Intelligence: This is a field of study with a goal to mimic human cognition. When you say human cognition, it covers all the 5 attributes that we considered above. Bringing all those 5 factors into the machines is called artificial intelligence. So this gives a simple definition for these buzzwords.
How are AI, ML, and Data Science related?
Data science covers observation, reasoning, and inference. Machine learning comprises data science. So machine learning comprises learning quickly and learning from experience in the machines. Artificial intelligence takes care of other important attributes.
So this is the link between data science, machine learning and artificial intelligence.

As of now, with all the computation power in place and with advanced technologies. We are at a stage where machine learning is already there with the engineering perspective, so we can engineer solutions based on the machine learning concepts.
Artificial intelligence is still not completely ready for engineering solutions yet. There is still a lot of work that is going on in the labs, but we are not completely there yet. There is a lot of work going on in terms of mapping our human brain in artificial areas. Once those experiments become successful, artificial concepts can come to the engineering level where it can solve a lot of day to day problems.
Machine Learning: Humans Vs Machines
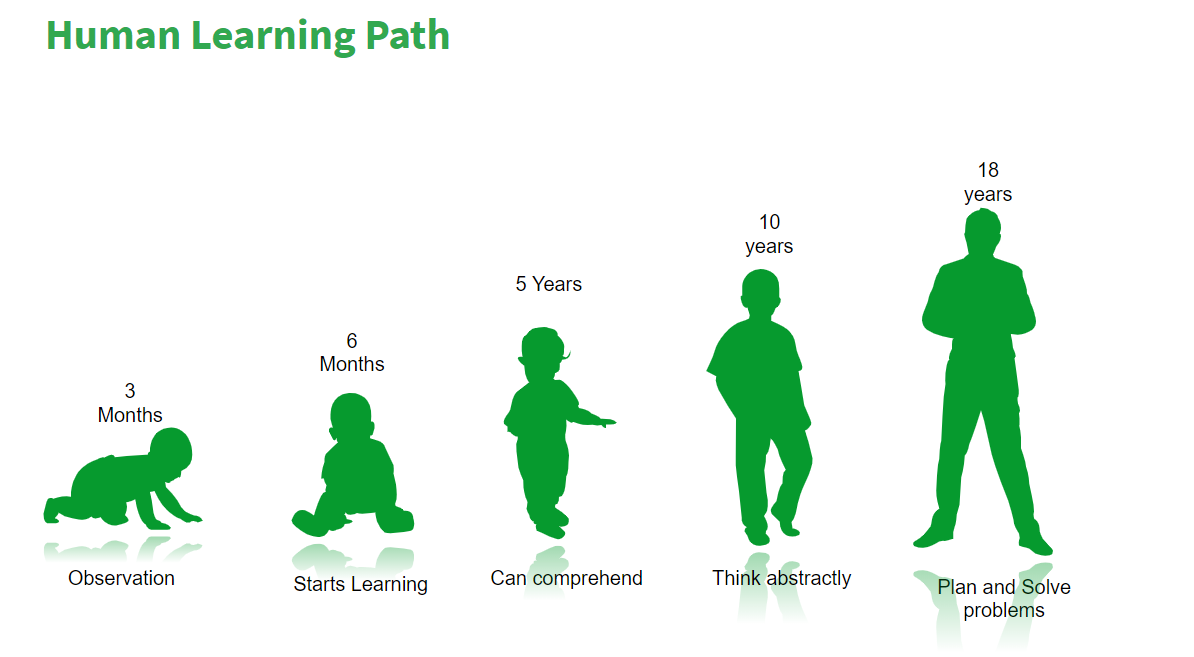
When a human starts his life, the observation starts from the time he/she is 3 months old. From the age of 6 months, the baby starts learning and trying to do something new. By the time the child grows to be 5 years old, he can comprehend. With age, they can think abstractly, plan and solve the problems as well. Once a human becomes an adult he can be a priest, scientist, artist, or whatever he/she chooses to become. There are different paths that humans can choose because of their learning ability. But none of the other animals have this facility because finally the learning ability is very less compared to humans. Now let’s bring that analogy into our traditional application development.
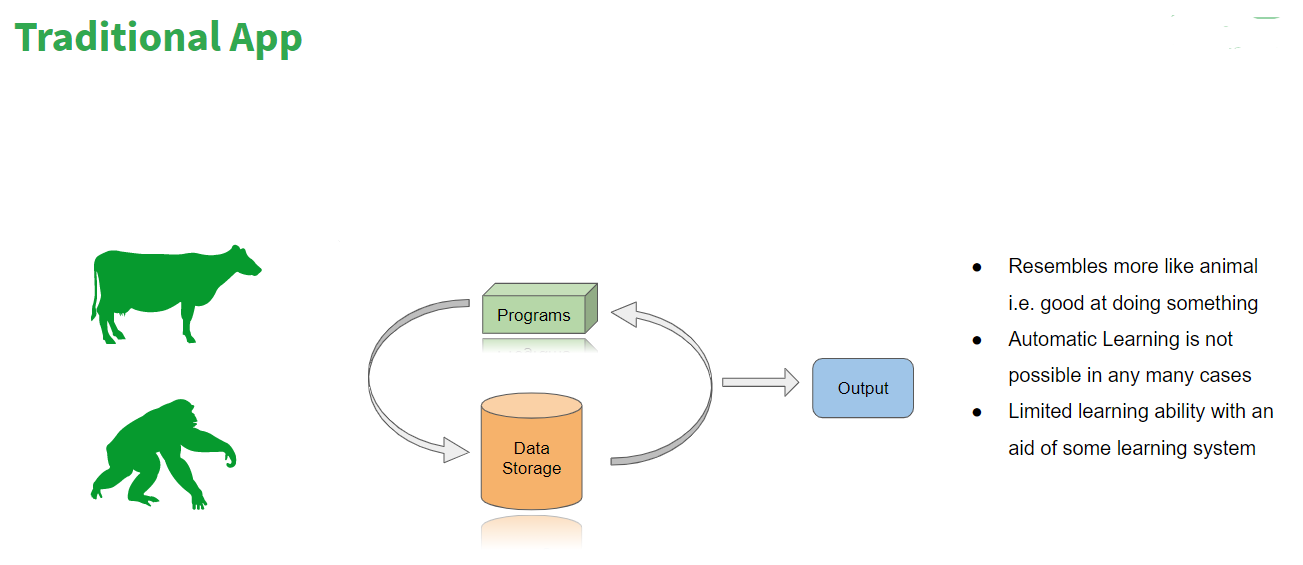
Most of the traditional applications that we develop have certain programs, it stores data and it gives certain output and it very well resembles an animal who may be good at doing a specific task. We can not automate learning or we cannot make them learn something different than their capabilities. With the limited aid, some learning systems can be plugged…they can start learning but cannot be a real learning system where decisions are taken by the learning system itself. So that’s the analogy of a traditional app. As we see in the picture above, there is data storage and program, and it gives an output. Let’s see what’s in the ML-based app.
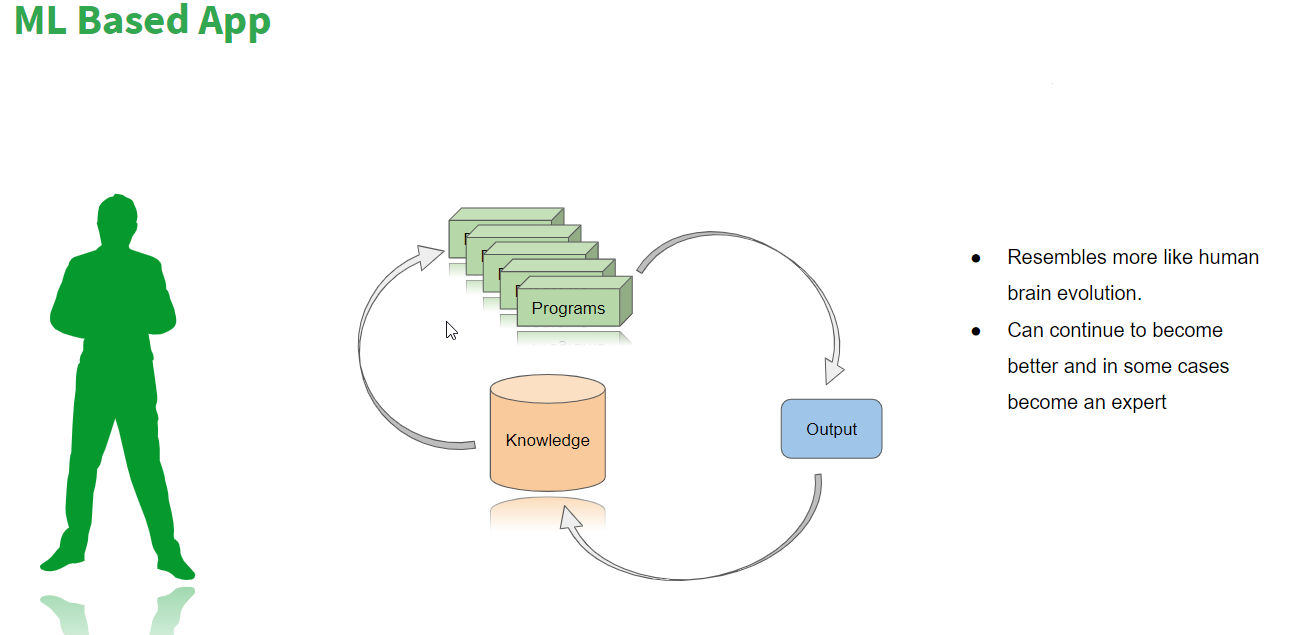
The ML-based app is to some extent like a human where rather than data it is knowledge, as the data is converted into knowledge. The program gets refined every time with new experiences and outputs are as given above. This resembles more like our human brain evolution and in some areas, it can become expert as well. There are some machines that became as smart compared to humans. Some computers can play a language game called GO. GO is a game that is even more complex compared to chess. If chess has N number of combinations GO has N x N3. If humans take ‘X’ number of days to learn and master that game, the machines are able to outperform humans quickly. So that’s where they can become experts in some areas in the ML-based apps compared to the humans as well.
A Brief Anatomy of Machine Learning
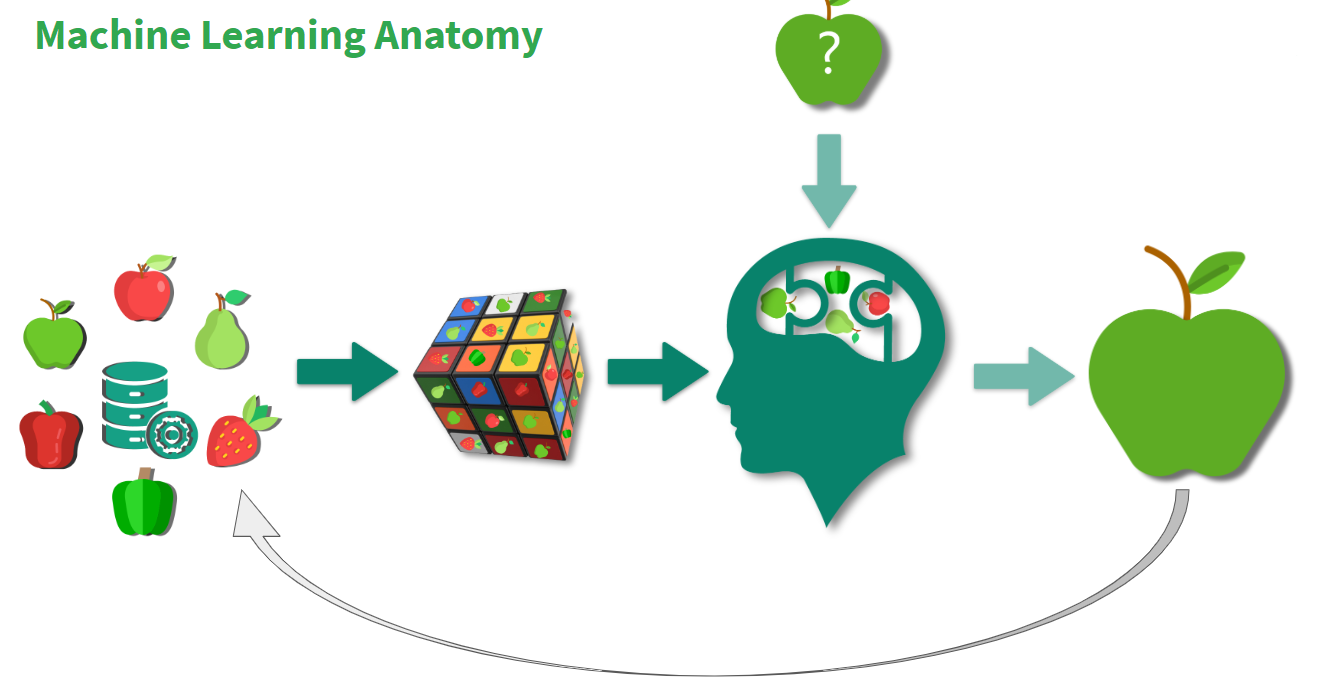
Machine learning comprises of 3 important entities:
Data set – Algorithm – Model that stores experience
Model that stores experience. In the future when sent a query or asked a question, the model evaluates the past historical data and then it makes a decision or gives a recommendation. Any present-day input is a past historic data for the future.
Example Of Machine Learning: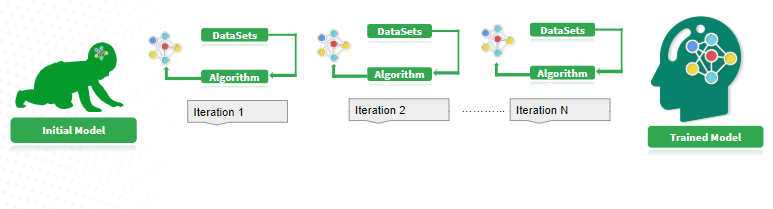
Initial model is when you start the basic storage of experiences, that we can consider that as an infant. When he/she is a kid the model will not understand a lot of stuff and the model is not very smart. But as we feed more and more experience, it becomes a trained model and then we can map it to the adult brain. So any machine learning system has a model, algorithm, data set. The more data set, the more experience that we try to give to the model, the better it becomes.
As an Executive, Can We Teach Science to Machines?
In this section, let us consider different learning types and different models. Primarily we have three different categories of learning – Supervised learning, Unsupervised Learning, and Reinforcement Learning. Let us cover details in the supervised in the below example:
2 x 2 = 4 (right answer)
2 + 2 = 4 (right answer)
2 x 2 = 6 (wrong answer)
Supervised Learning
In the supervised learning environment, it means that we are giving input. And we are giving output and telling what is right and wrong. So when we give specific input and dataset, it is called supervised learning. So in this, the dataset has clear demarcation, and there is an explicit correct or incorrect answer. So there is a progressive movement towards better decision making. As you start feeding more and more datasets then our learning model and training model will become strong and prediction will become more accurate. So how do we map this supervised learning into the human? Supervised learning is like any concept learning.
Unsupervised Learning
Unsupervised learning is slightly different because the dataset does not tell what is right and what is wrong. So the training data has only input definition but no output definition as there is nothing like a right or wrong answer. An important aspect is to identify different common structures from the data. So identifying items that have common similar characteristics and group them. Any segregation method we do can be compared to the human parallel of unsupervised learning.
Reinforcement Learning
Primarily the Reinforcement learning starts with simple supervised learning where we provide the input data but the difference here is that the training dataset will be randomly generated with all the different possible variations so that the training model will become strong and in this case when we’re generating the training data randomly, every training data set giving a positive and right answer will be rewarded, and anything which is giving a negative answer will be penalized. So that way the system will be trained automatically to be precise towards better prediction. The question may come as to why I need to randomly generate the training datasets. The reason is that, let’s say that if we are expecting our training model or app to be better than human and start giving training dataset that is encountered by humans so far then the algorithm or training model will not be more strong than the dataset that is provided. So in reinforcement learning, a lot of permutations and combinations are generated so that the system will become smart and all the time the intention is going towards becoming better at prediction. So the positive answer is rewarded and the negative answer is penalized.
Human Parallel to reinforcement Learning
Human parallel is continuing to be good in a particular sport with continuous practice. It is not that we play only when there is a match. I will continue to practice and get better at it. At the time of training, we may fail multiple times but every time we fail we get lessons and better. Finally, we become better at the sport. So that is called reinforcement learning.
The above gives a detailed outlook for an executive about what exactly is machine learning and different aspects that make it work. This was just part one for the topic and for greater insights about different machine learning models and the machine learning reality now and a look into the future possibilities, stay tuned for our next blog: An Executive’s Approach To Machine Learning – Part 2.





You have explained the concept really well. Was looking for this information from a while & luckily I stumbled upon your post. Looking forward for more of such informative updates from you