Blogs
Deciphering the synergy of Multi-Modal Intelligence: Pioneering use cases and innovations in the enterprise domain
Multi-modal Language Models (MLLMs), also recognized as Vision Language Models (VLMs), are at the forefront of innovation, enabling machines to interpret and generate content by integrating both textual and visual inputs. This fusion of modalities offers a more nuanced understanding of data, capturing richer context and semantic meaning far beyond the capabilities of traditional models that process text or images in isolation.
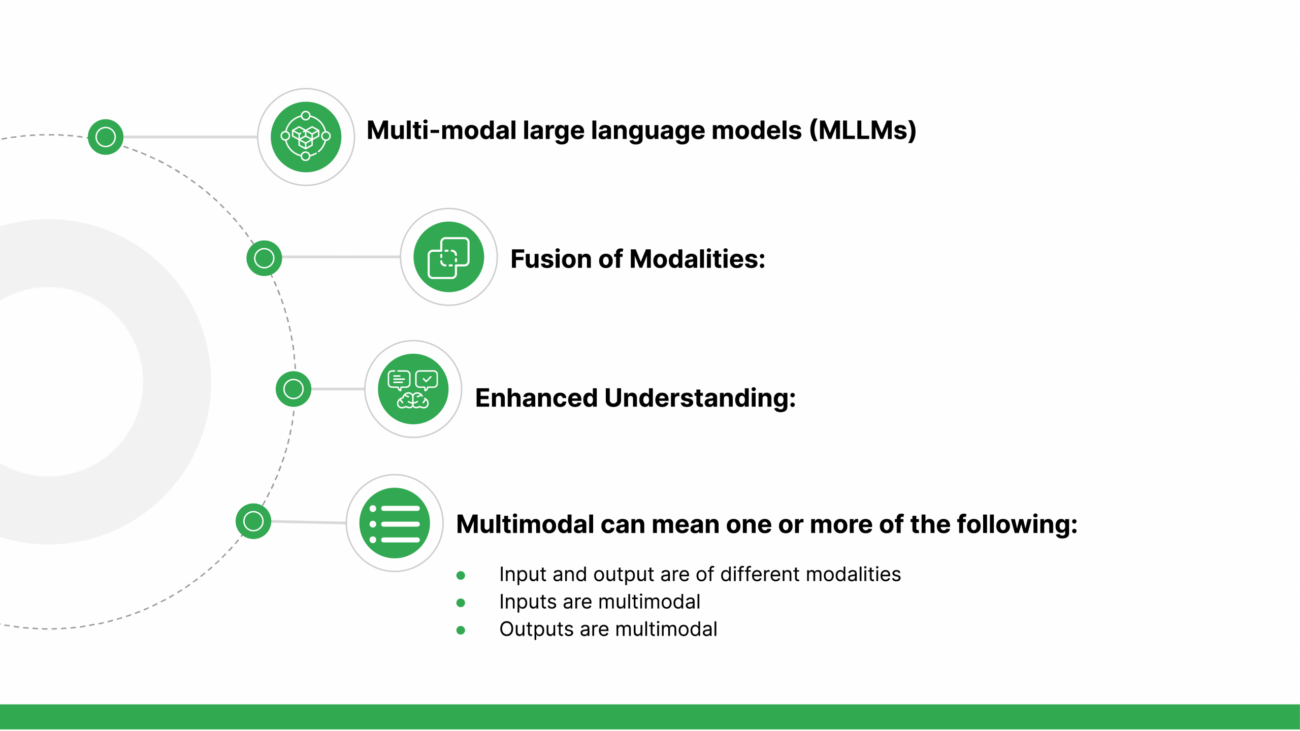
Multi-modal LLMs can be broadly categorized based on their functionality:
- They might process inputs of different modalities, like transforming textual descriptions into corresponding images or vice versa.
- In some cases, the inputs themselves are multi-modal, such as systems that analyze both textual instructions and visual data to generate a response.
- Additionally, the outputs can be multi-modal, where the model might generate a textual description alongside a relevant image.
This versatility opens a plethora of possibilities, from enhancing content accessibility to creating more immersive user experiences across various digital platforms.
|Deep dive into Multi-Modal LLMs: Real-world applications and use cases
The architecture of VLMs typically involves:
- Encoders for each modality, generate embeddings or numerical representations of the input data.
- A projection layer aligns these embeddings into a unified multimodal space, facilitating the integration of diverse data types.
- A language model then generates text responses, conditioned not just on textual inputs but on the synthesized multimodal context.
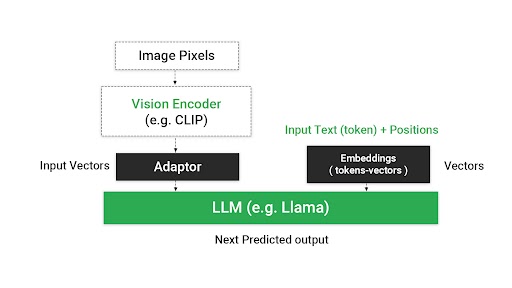
|Popular VLMs and their components
Some noteworthy VLMs include Flamingo, BLIP, and LLaVA, each comprising distinct components for processing visual and textual data. For instance, LLaVA uses CLIP as its vision encoder and Vicuna variants for language processing, illustrating the modular approach to building these complex models.

|Task categories and use cases
VLMs excel in a variety of tasks categorized into generation, classification, and retrieval. Generation tasks might involve image captioning or video summarization, while classification could encompass sentiment analysis in multimedia content. Retrieval tasks leverage the model’s understanding of one modality to fetch relevant information from another, such as in visual question-answering systems.
Real-world applications are vast, ranging from automated content creation for social media to advanced diagnostic systems in healthcare, where the model interprets medical imagery alongside clinical notes to provide comprehensive insights.
|Strategies for implementing Multi-Modal LLMs
Implementing these models in enterprise settings involves several key strategies:
- Data Integration and Preprocessing: Ensuring data from various sources is compatible and well-structured is foundational.
- Model Selection: Choosing the right model involves balancing computational efficiency with the ability to process complex multimodal data.
- Integration with Existing Systems: Seamless integration into existing tech ecosystems is crucial for practical deployment, requiring careful planning and execution.
|Showcase of some examples
To illustrate the transformative potential of multi-modal LLMs, consider an enterprise leveraging these models for market analysis. By analyzing a mix of financial reports, news articles, and stock market charts, a multi-modal LLM can provide a holistic view of market trends and predictions, offering a competitive edge.
Another example is a smart discovery app in e-commerce, where users can upload an image of a product to find similar items or variants, enhancing user experience and driving sales.
|Challenges in implementing Multi-Modal LLMs
The integration of multi-modal language models into enterprise systems is not without its hurdles. Key challenges include:
- Data Privacy and Security: With MLLMs processing sensitive visual and textual data, ensuring robust data protection mechanisms is paramount. Adhering to compliance standards while maintaining data integrity poses a significant challenge.
- Scalability and Performance: The computational demands of MLLMs, given their complex architecture and the large volumes of multi-modal data, require scalable solutions that do not compromise performance.
- Model Interpretability and Bias: Ensuring that the outputs of MLLMs are interpretable and free from biases inherent in the training data is crucial for ethical and responsible AI applications.
Addressing these challenges requires a concerted effort in research, development, and ethical considerations, ensuring that MLLMs are not only effective but also aligned with broader societal values.
|Innovative use cases of Multi-Modal LLMs
The versatility of MLLMs has paved the way for their application across diverse sectors. Some groundbreaking use cases include:
- Augmented Reality (AR) and Virtual Reality (VR): In AR and VR environments, MLLMs can enhance user interactions with digital elements by processing both the users’ verbal commands and the visual context, providing a more intuitive and immersive experience.
- Automated Content Moderation: Platforms hosting user-generated content can employ MLLMs to understand the context better and make more informed decisions about the appropriateness of both textual and visual content, thus improving moderation efficiency and accuracy.
- Intelligent Document Processing: Enterprises inundated with documents containing complex diagrams, charts, and text can leverage MLLMs for automated data extraction, analysis, and summarization, significantly reducing manual effort and improving data accuracy.
- Personalized Education Platforms: MLLMs can revolutionize online learning by providing personalized feedback and instruction that consider both the written work and visual projects of students, adapting to their unique learning styles and needs.
| AI Platform | Notable Features |
| Lava 1.6 | Open-source VLM with a vision encoder for image processing and a text encoder for text understanding |
| Clip | Vision model used in Lava 1.6, established and state-of-the-art for image processing |
| Llama | State-of-the-art open-source LLM, fine-tuned versions available for different project sizes |
| Mr. 7B | Proprietary model with varying parameter sizes for different computational requirements |
| GPT-4 Vision | Developed by major companies, undisclosed architecture excels in natural language understanding |
| Claude 3 (Anthropic) | Recent model showing an uptick, good performance in generating code and other tasks |
| OpenAI’s Chat GPT | Known for significant strides in natural language understanding and generation |
| Chat GPT Vision | Focuses on vision tasks and multimodal AI applications |
|Prospective trajectories and synthesis
The trajectory of multi-modal language models suggests an increasingly integral role in the digital ecosystem. As these models become more sophisticated, we can anticipate even more innovative applications, potentially transforming sectors like healthcare, where MLLMs could analyze medical imagery in conjunction with patient histories to provide personalized treatment plans.
Moreover, as the technology matures, addressing ethical considerations and ensuring equitable access will be paramount. The potential of MLLMs to bridge language and accessibility gaps offers a promising horizon for creating more inclusive digital spaces.
Multi-modal language models represent a significant leap forward in AI, offering a glimpse into a future where machines understand the world more like humans do—through a seamless integration of text and visuals. As enterprises continue to unlock the potential of these models, the possibilities for innovation and transformation across industries are boundless.
MLLMs merge text and visuals with modality-specific encoders and unified embeddings, advancing content creation, classification, and retrieval. Addressing scalability, privacy, and bias, they drive transformative applications in healthcare, e-commerce, and education, enhancing semantic understanding. Learn more here: Unlocking Multi-Modal Brilliance: Enterprise Use Cases and Innovations