Blogs
How to not let your applications crumble like a cookie

The lack of a proper database design is one of the myriad obstacles preventing organizations from succeeding in software development projects.
A poor database design can lead to sub-par performance, an inability of the database to accommodate new features, and low-quality data that can be a major hindrance as the project evolves.
Creating a database is easy. Creating an efficient one is difficult. Flaws in your database design are similar to cracks in a building’s foundation – corrective measures taken later can be extremely costly.
The best practices outlined here can help you avoid the pitfalls in database design and help you create one that is robust and efficient.
To skip to the database design best practices, Click here .
Different phases involved in database designing
A lot of phases are involved in database designing that help us conduct it efficiently. The most important steps involve:
1. Collecting the data-related requirements and analyzing them.
2. The next step involves creating the conceptual schema for a database and an ERD (entity-relationship diagram) or UML class diagram is formed.
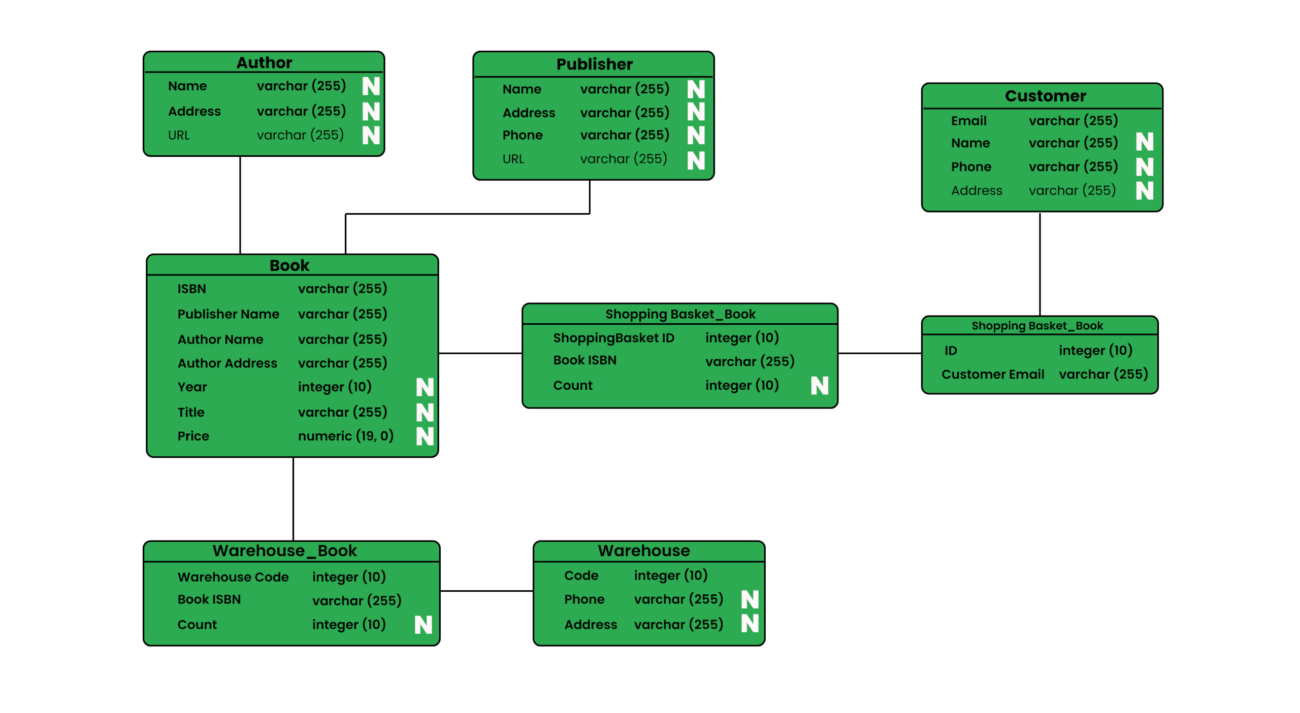 3. The next step is designing the relational schemas. The primary keys and the foreign keys are identified in this step.
3. The next step is designing the relational schemas. The primary keys and the foreign keys are identified in this step.
4. Normalization is the next step where the duplication or data redundancy is removed.
5. The physical design of the database takes place in this step. The DBMS (database management system) identification is done in this step. The data is also stored in the actual database in this step.
5 Most popular tools for database designing
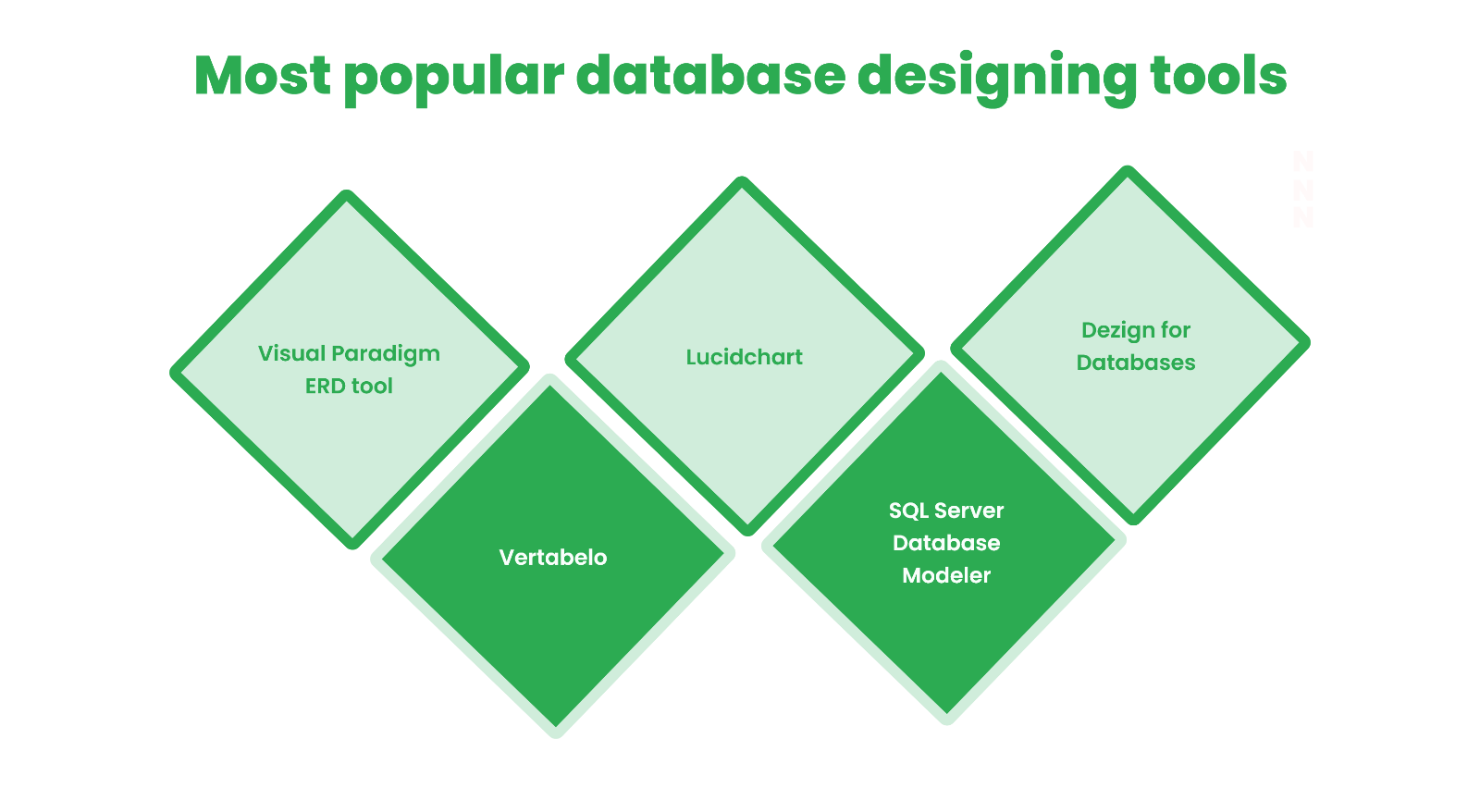
Various database tools come into play during database design. Let’s start with each of them.
Visual Paradigm ERD tool
This tool helps in creating the entity-relationship diagram (ERD). The ERD is essentially the first step in designing the database. This tool offers many features including enterprise architecture, visual modeling, mind mapping, etc. It is ideal for creating UML diagrams. The visual paradigm tool is quite popular in the software field and is adopted by Fortune 1000 companies and the like.
Vertabelo
Vertabelo is a commercial tool that enables the creation of databases online. With the help of its visual modeling feature, the manual effort to create multiple tables is reduced.
Lucidchart
This tool is one of the most common database design tools that can help you create database diagrams online quickly and efficiently. Lucidchard helps in creating a fully-functional database with the help of different features of database modeling. To add to these, the tool offers flexible pricing and is designer-friendly as well.
Also, you can leverage the tool without downloading it with Lucidchart’s cloud-based feature. It enables a collaborative approach while working on real-time projects with the help of its web-based feature.
Lucidchart has also been a recipient of the Start2Cloud Editor’s choice award.
SQL Server Database Modeler
This is another most commonly used database design tool. This can help design the database by importing the existing database with the help of forward-engineering and reverse engineering techniques.
This tool is popular for its friendly UI, creating numerous subjects, and project sharing capabilities. It is easy to use and does not need any additional support from database engines and database modeling tools for designing the database. It is ideal for both small and large businesses.
DeZign for Databases
This tool helps in performing data modeling, model synchronization, model-driven collaboration, and building customizable model reports. It can support over 15 databases, it is robust and easy to use.
Why Does Database Design Matter?
Consider the website of an online clothing store where you wish to order a shirt. Although acquiring a shirt from this website appears to be a straightforward process, it involves a significant amount of data sharing. For example, when you initially visit the website,
- It displays a list of their product categories as well as all of the available products, their prices, sizes, colors, and other pertinent information.
- Then, the data is retrieved by the website from the database where it is stored.
- When you choose an item and proceed to purchase it, the website will ask for your personal information, shipping address, and payment information, as well as confirm your order.
- The additional data generated by this process, such as customer, order, purchase, and payment information, is then added to and updated in the same database.
Database design is important since it is required for developing scalable software systems that can handle heavy workloads. To begin working on database design, you must first choose a database program. There are now hundreds of database software options available for creating applications. The next stage is to design your database to match your needs, and here are the top database design
Best Database Design Practices
1. Take Everyone’s Perspective into Account
It is critical to consider the perspectives of all stakeholders when creating a database. Before you establish a database, get their feedback to find out what they want and how experienced they are with it. This will give you an indication of how technical your database should be and whether or not you’ll need to train customers on its utilization.
2. Select a Database Type That Fits Your Needs
There are multiple kinds of databases, and choosing the proper one is a significant component of database design. There are two approaches to classifying database types. To begin, a database’s query language is used to specify and manipulate the data. For structured data, SQL databases are the most prevalent. NoSQL databases, on the other hand, are superior for machine learning, web analytics, and IoT (Internet of Things) due to scalability, flexibility, and speed.
Data models are another method for categorizing databases. Relational databases, hierarchical databases, network databases, and object-oriented databases are a few database schema types. Researching various types of databases and selecting one that suits your application’s demands is a vital first step. Sometimes you may decide to use a combination of two or more databases if your business data needs are diverse.
Relational databases: This is a type of database model that has a relationship among the data points. These are based on the relational model and are the most straightforward way of representing the tables.
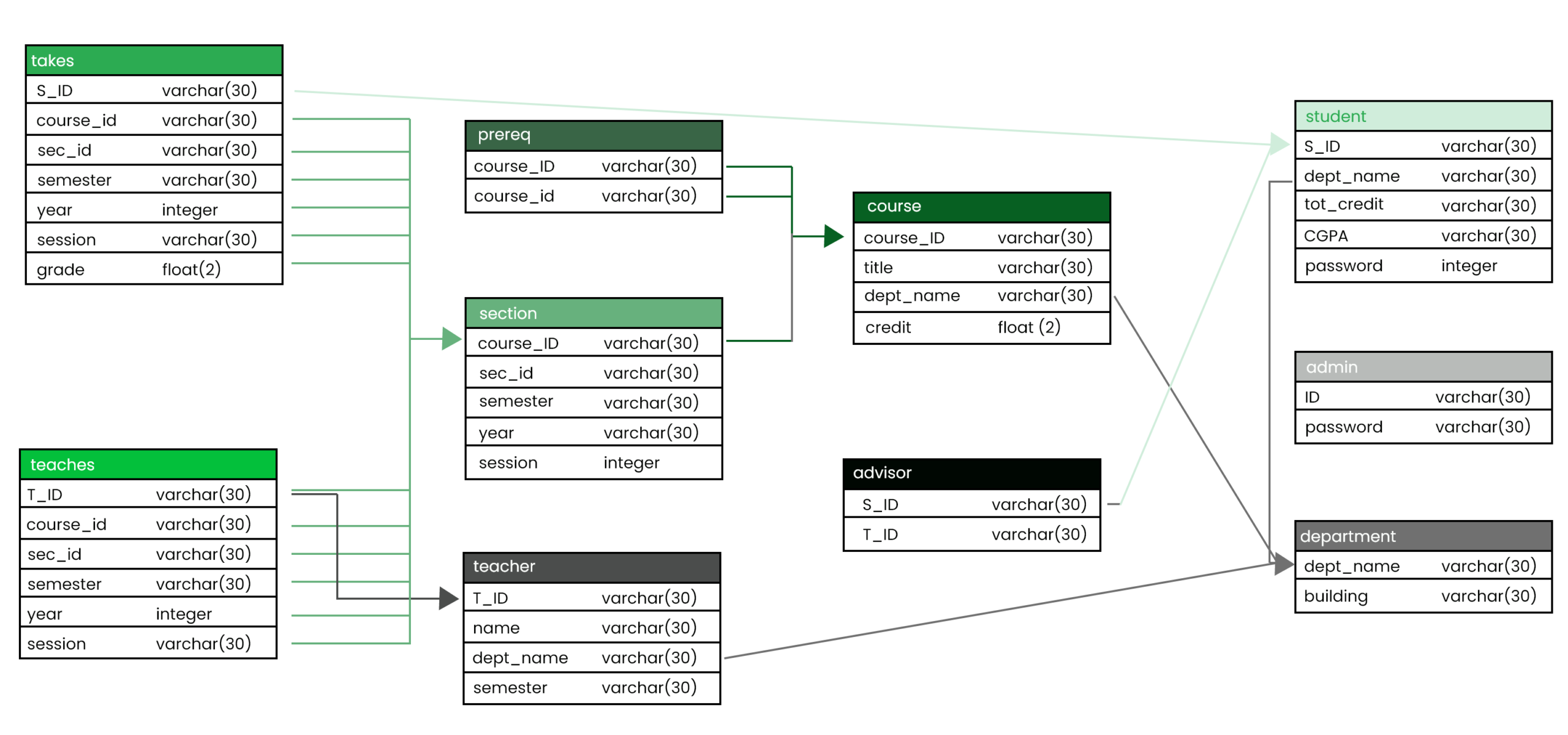
In a relational database, each row is called a record with a unique id called the key. The most important reason behind using an RDBMS is its ability to join the tables. Joining the tables help you understand the relationship between the data.
Hierarchical databases: These database schemas use one-to-many relationships for data elements. It uses a tree structure to represent disparate elements. Hierarchical databases were more popular in the early database-design era.
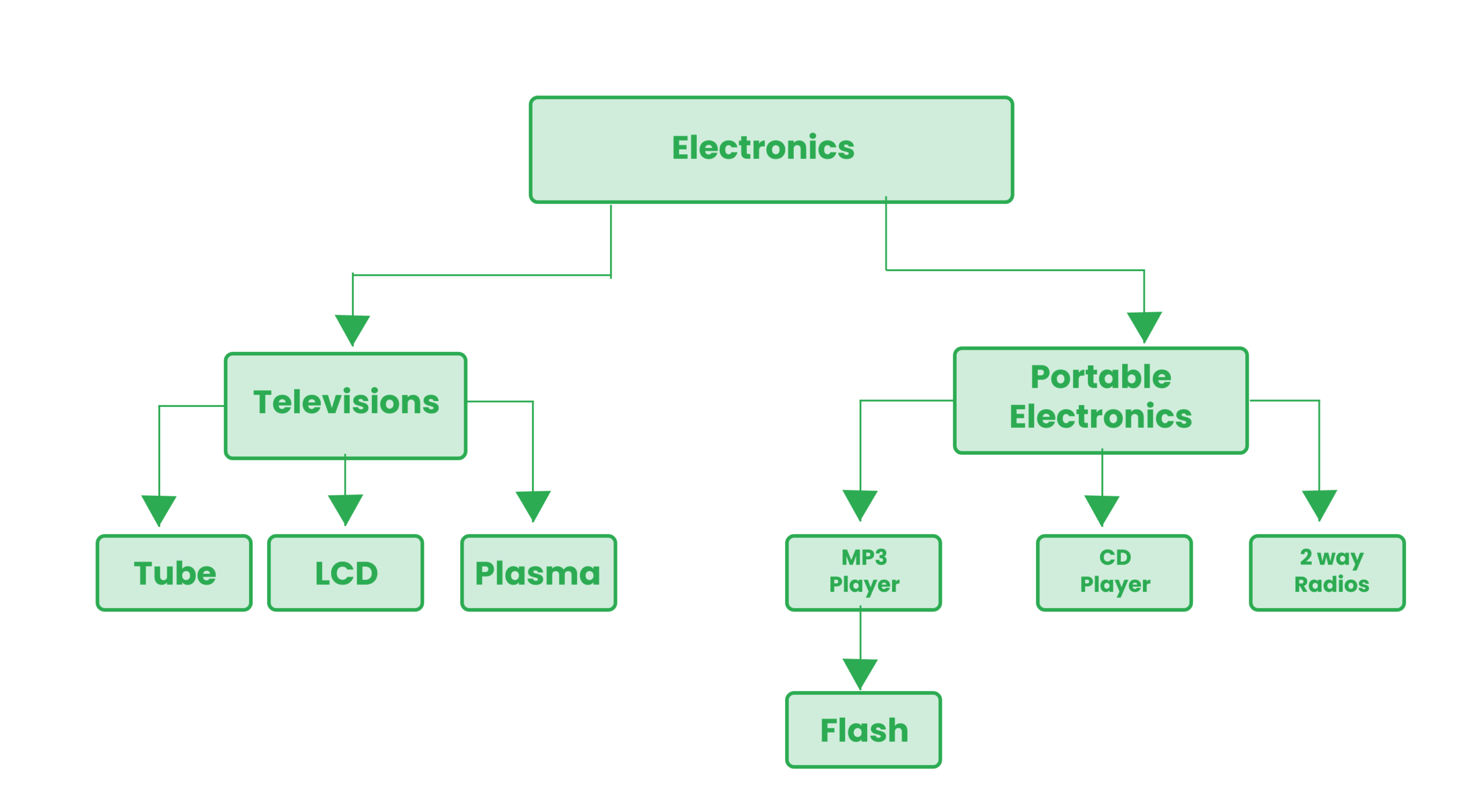 These are used for a certain type of data storage and are not versatile. It is especially used when the reporting structure of employees in an organization, etc.
These are used for a certain type of data storage and are not versatile. It is especially used when the reporting structure of employees in an organization, etc.
Network databases: This is a type of database model where multiple member files can be linked to multiple owner files.
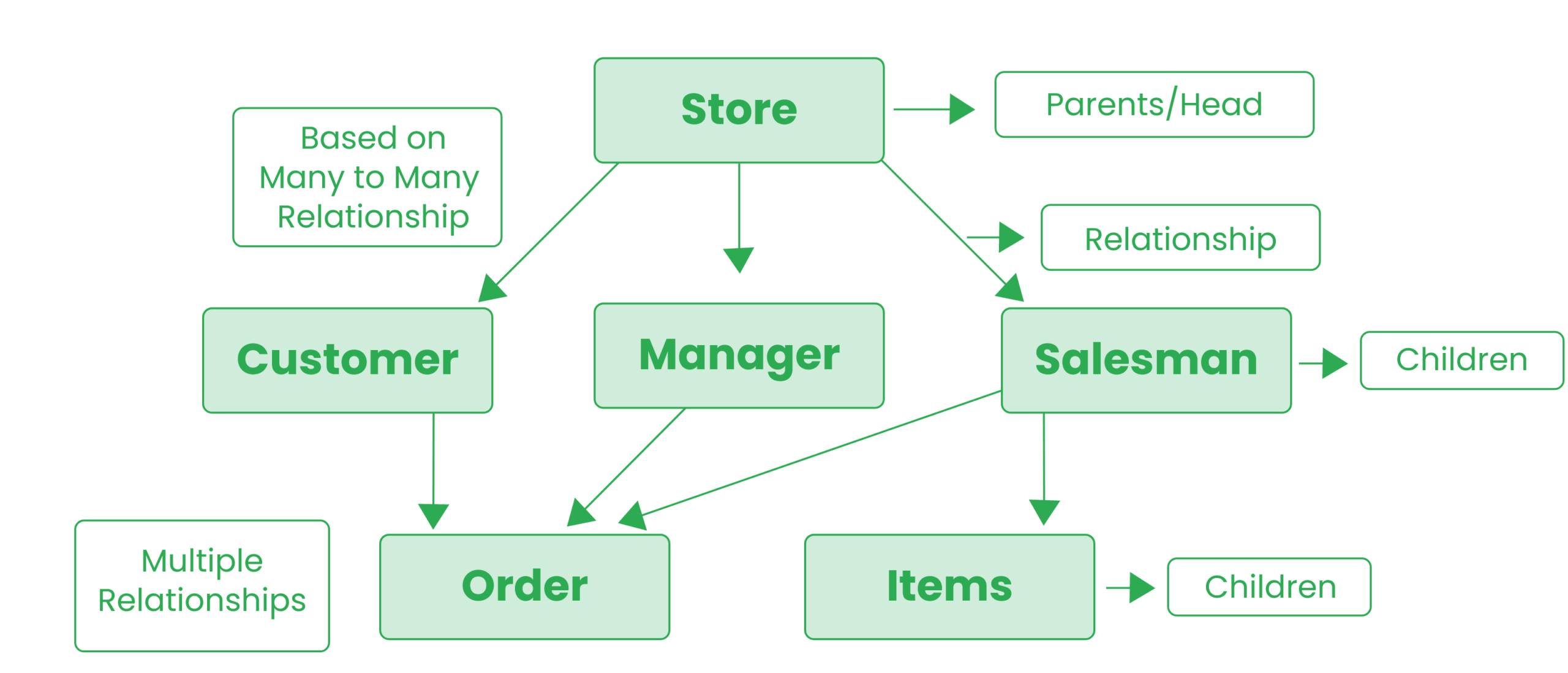
This model is usually represented using an inverse tree where each member’s data is linked to the owner at the bottom of the tree. This database model is a progression from hierarchical databases to resolve some of its drawbacks or add flexibility to the latter.
Object-oriented databases:
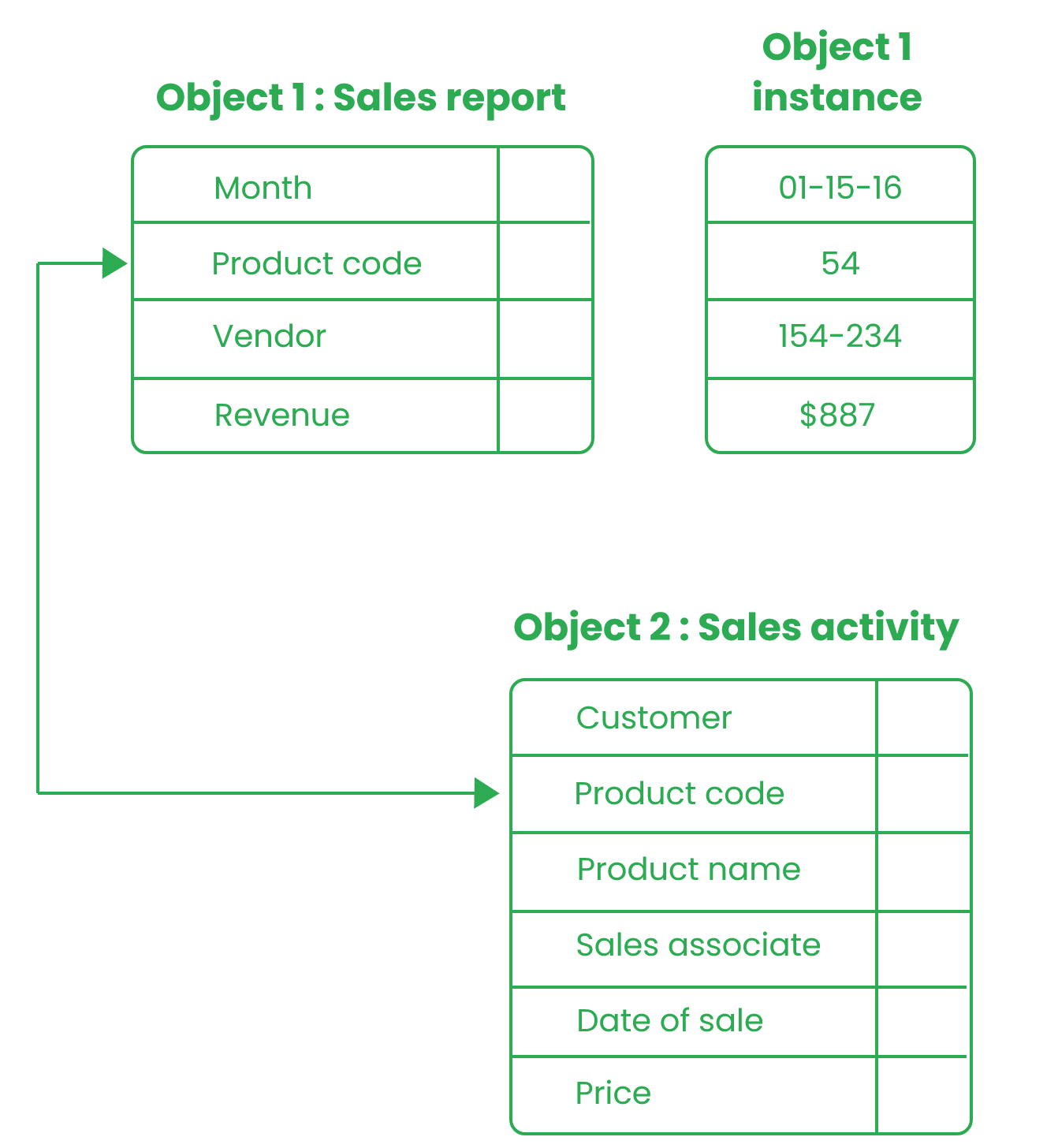
This is a type of database model that can work with complex data objects. Object-oriented databases (OOD) are used with OOP languages like Java, Kotlin, Node JS, C#, and Swift.
3. Define and Label Tables and Columns Consistently
It is critical to have a consistent strategy when defining data items and labeling tables and columns. This will assist you in better comprehending your data. Giving tables and columns a succinct name that defines the data they contain is one of the best practices for naming them. Simply label a column holding your customers’ names as ‘CustomerName’, for comparison purposes.
You should also avoid using plural names (for example, CustomerNames), abbreviations (for example, CN), and spaces in the name (e.g. Customer Name). It will be easier for future users to use the database if you follow these principles consistently.
4. Normalization Is Key
The process of structuring all of the information within a database to avoid data replication and redundancy is known as database normalization. In layman’s terms, normalization entails dividing data into multiple smaller related tables rather than storing it all in a single huge table.
Normalizing data for efficiency is a smart database design strategy. However, don’t over-normalize your data because it will be divided into too many smaller tables, making everything unclear.
5. Documentation of Database Design Is Important
To be honest, documenting isn’t anyone’s favorite task because it appears to be so inconvenient. However, keep in mind that documentation is necessary for excellent database architecture since it keeps track of all the minor details. Instructions, ER diagrams, stored procedures, and all other essential information should be recorded in your database design. The documentation should give programmers and end-users enough information to understand how to utilize it.
6. Privacy Is a Primary Concern
The data that is stored in databases is frequently secret, therefore privacy is a legitimate concern. To ensure maximum security, encrypt your passwords, implement authentication to restrict database access, and store your database on a separate server than your application. This will protect your data from being hacked or having its privacy violated.
7. Think of Long-Term Needs
A good database design is scalable, meaning it can handle a high workload and keep the application functioning even as the number of users grows. When developing a database for a company that expects a change in workload, it’s critical to keep this in mind. For example, if an e-commerce website anticipates a significant increase in visitors during a month when sales are expected to be strong, this should be factored into the database design process so that the database can accommodate the increased traffic and withstand the increased strain.
8. Code and Use Stored Procedures
A typical database design error is not employing stored procedures. Stored procedures are pre-written codes that come in handy while working with data. If you frequently use a SQL query, for example, instead of writing it over and over again, you may put it into a stored procedure to make your job easier. After you’ve created the stored procedure, you can simply run it to complete the SQL query in one step. It can be exhausting to code a large number of stored procedures, but if you take the time to do so and describe them, it will make utilizing a database easier for end-users.
9. Spend Time on Database Modeling and Design
Investing time and effort in database modeling and design is a great tip for creating a solid database. To save time and focus on other more critical parts of software development, developers frequently overlook this phase. However, database design is necessary to assure an application’s operation. If you save time by not thoroughly considering the design, you will end up spending more time in the future on maintenance and redesigning.
10. Test Your Design
Testing is another critical phase in database architecture that is frequently missed or omitted entirely in the rush to deliver applications on time. Before launching the project, you should extensively test your database design to ensure that it meets all of the planned criteria and is functioning.
11. Avoid Using Hints
The most complex and efficient SQL engines have taken countless hours and immeasurable amounts of money to develop some of the top RDBMS manufacturers. Hints prevent the RDBMS from accessing the data in the most efficient way possible. Use query hints as the last resort. The main focus should be on fixing the root cause of the problem to ensure that the query performs well rather than providing hints which increase the code complexity and management.
12. Proper Data Types
The advantages of utilizing the right and suitable data types for database properties are twofold:
- It validates that the proper data is entered into the database. 20010229, for example, cannot be added to a DATE datatype property, but it may be added to an INTEGER datatype.
- It gives you more information about the UPDATE STATISTICS command. When you save ‘Dates’ as an INTEGER instead of a DATE data type, you’ll get the wrong number of possible values for the property. For example, an INTEGER datatype has 100 possible values between 20010101 and 20010201, but a DATE type only has 31.
13. Eliminate Unnecessary Attributes within Queries
Limit the characteristics in the SELECT clause of the query to only those that are required to meet the business need for maximum performance. Limiting the characteristics minimizes the amount of data transmitted from the disc and allows for more meaningful data per memory page, resulting in faster query execution. For any production queries, never utilize the ‘*’ in the SELECT clause.
14. Think about Relationships
When creating new relationships, it’s critical to think about the setting in which they’ll be deployed (i.e. OLTP, Operational Data Store, Data Warehouse, etc.).
The following elements are critical for creating new or changing existing relationships:
- Data normalization levels should be implemented;
- Data Types that are consistent across all relationships;
- Attributes and order of primary and secondary indexes;
- Each attribute’s cardinality
15. Keep Statistics Updated
Statistics give data knowledge and insights to the SQL engine. The OPTIMIZER uses the statistics acquired by the UPDATE STATISTICS procedure to establish the most efficient access path into the data. Data access pathways may vary over time as the data changes. As a result, it’s critical to maintain statistics up to date and recompile applications regularly.
16. Avoid Table or Index Scans
Accessing data that will never be used by a query is one of the most wasteful uses of system resources (disc, CPU, memory, etc.). Unnecessary data scanning is usually caused by one of the following factors:
- In a query, there are no predicates.
- Query with a bad structure
- As a predicate, non-keyed or non-indexed characteristics are used.
- The compound key with a bad structure
- Due to outdated statistics, the QEP is inefficient (Query Execution Plan)
- Incomplete or ill-organized JOINING OF RELATIONSHIPS
- As a function, the predicate is used.
17. Limit Temporary Tables
Most SQL implementations provide a temporary table that allows an interim data set to be utilized repeatedly by a query or stored procedure. There are, however, several reasons to limit or remove the usage of temporary tables: RDBMS engines have advanced to the point where they can now provide this capability automatically at runtime.
The additional I/O operations to READ the initial data, WRITE the data to the temporary table, READ data from the temporary table, and finally remove the temporary table slow down query execution time. The query execution is halted until the temporary table is filled.
18. Limit the Utilization of TOP Function
It’s a widespread misperception that query execution ends when the TOP condition is met. This, unfortunately, is not the case. Before an RDBMS engine can assess the TOP condition, it needs a materialized intermediate result set.
19. In a query that requires sorted data, the ORDER BY clause is required.
There are various reasons for processing data in a given order; nevertheless, the ORDER BY clause should only be used in queries when the data must be processed in a specified order. Another option is to arrange the data using a primary key and/or an index in such a way that the data is returned in the order required to meet the business requirements without using a SORT process.
20. Use ‘Cover’ Indexes Where Possible
The benefit of using more than one index is that you can have fast access to data that isn’t related to the primary key. Most indexes, on the other hand, are structured in such a manner that a secondary READ of the base table is necessary to receive all of the data required for the query. By definition, a cover index will include characteristics that aren’t intended to be used as predicates, but rather to meet the query’s data needs.
21. Making use of database views
Database engine (DBE) views offer a quick and efficient way to look at the data. Most standard practice would be to de-normalize the data without losing its correctness. Indexes should be used to speed up the queries, and aggregate functions help in analyzing the information without the need for programming.
In a nutshell
Database design is critical for a data-centric project and should be considered as such throughout the development process. The aforementioned database design techniques, such as proper planning for long-term needs, selecting the appropriate database type, using consistent names and labels, normalization, documenting, and testing, are essential to creating a solid database.
We all know that business directives change over time and to stay in line with the current business goals, the databases also need fine-tuning to adhere to them. To know how we deliver successful project development and implementation with a strong foundation of good database design, click here.