


Blogs
Scaling AI Agents in Production: Engineering, Ethics, and Enterprise Impact

AI agents are moving quickly from experimentation to real-world deployment. What began as copilots that assist with content drafting or information retrieval is evolving into autonomous systems that triage support tickets, process documents, and coordinate enterprise workflows.
Many teams can now build a functional agent prototype in a short time. However, moving from a prototype to a production-grade system that can scale reliably, control cost, and operate responsibly remains a significant challenge. Teams that get this wrong often see pilots stall, costs spike unpredictably, or early trust erode with users and leadership.
Scaling AI agents is not a single technical problem. It requires disciplined systems engineering, platform maturity, cost governance, organizational alignment, and a clear approach to responsibility and risk. Organizations that underestimate this complexity often struggle with fragile deployments, unpredictable behavior, and pilots that fail to expand beyond limited usage.
This blog examines what scaling AI agents in production actually entails and how mature organizations approach it.
| What Scaling Means for AI Agents
In traditional software systems, scaling is usually measured in terms of throughput and infrastructure utilization. More users result in more requests, which are handled by adding compute resources.
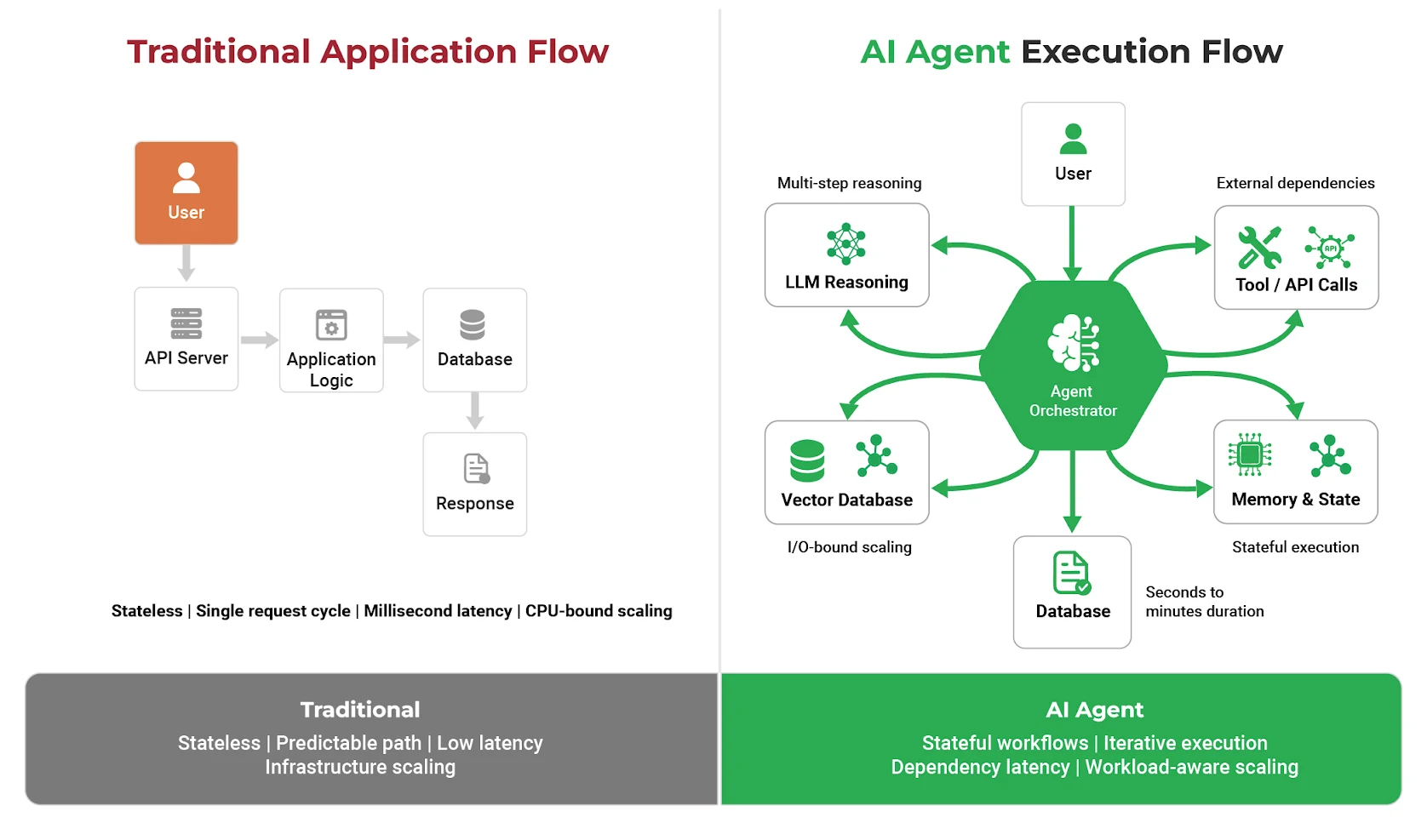
AI agents operate differently.
A single agent request may involve multiple reasoning steps, repeated interactions with large language models, calls to internal systems, vector databases, and external APIs, and execution paths that span minutes rather than milliseconds. These requests are stateful, long-running, and dependent on multiple external services.
As a result, scaling AI agents is not only about handling more users. It is about executing complex workflows reliably and predictably across distributed systems.
At scale, organizations consistently encounter the following challenges:
- Coordinating distributed components without cascading failures
- Maintaining acceptable latency across multi-step execution
- Controlling model and tooling costs as usage grows
- Ensuring safe and compliant behavior as agent autonomy increases
These challenges resemble those found in distributed systems more than in traditional application scaling, which is why platform-level thinking becomes essential.
| AI Agents as Platforms, Not Chatbots
A common early mistake is treating an AI agent as a simple wrapper around a language model. While this approach may work for demonstrations, it does not hold up in production environments.
At enterprise scale, agentic AI success depends far more on the shared platform capabilities beneath the agent than on the sophistication of any single prompt or workflow.
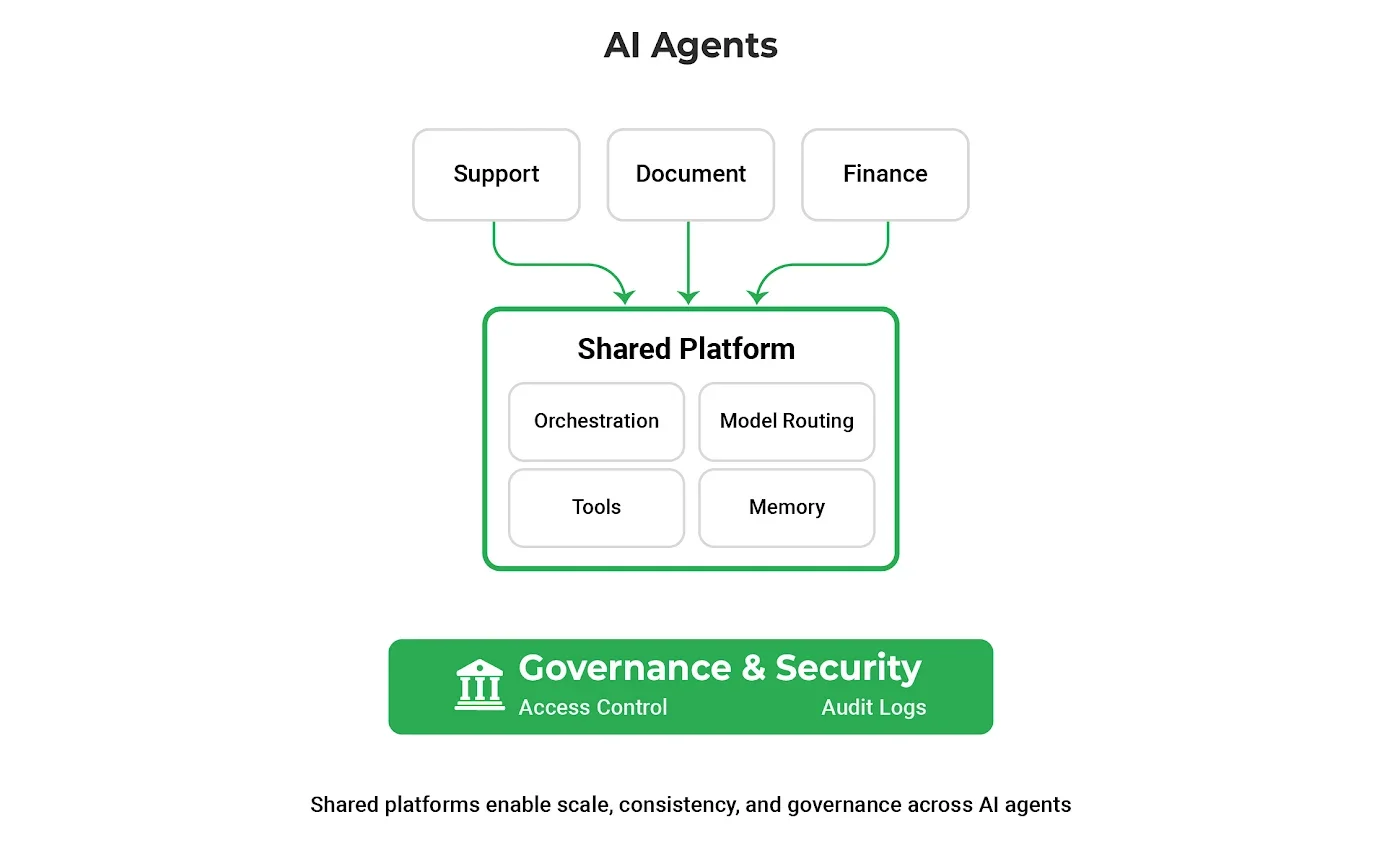
In practice, scalable agent deployments depend on an underlying platform that provides shared capabilities across agents. Rather than solving the same problems repeatedly at the agent level, mature organizations centralize these concerns into a common foundation:
- Orchestration to plan tasks, manage execution flow, and handle retries
- Model routing to balance capability, cost, and sensitivity
- Secure tooling layers for APIs, data sources, and internal services
- Persistent memory and state management across sessions
- Governance controls for permissions, policies, and auditing
This separation allows teams to scale agent usage without sacrificing consistency or control. Platforms such as AlphaTree reflect this platform-first approach, helping teams standardize orchestration and governance while preserving flexibility at the agent layer.
Industry experience shows that long-term success with agentic AI depends less on individual agent intelligence and more on the robustness of the platform that supports it.
| Why Conventional Autoscaling Falls Short
Many organizations initially attempt to scale AI agents using the same infrastructure signals applied to web services, such as CPU utilization.
This approach is often ineffective.
Agent workloads are primarily I/O-bound. They spend significant time waiting on model responses, external services, and data sources. From an infrastructure perspective, systems may appear underutilized while task queues grow and user-facing latency increases.
Teams that scale effectively shift their focus to workload-aware signals, including:
- Task queue depth and backlog growth
- End-to-end task latency
- Saturation of downstream tools and dependencies
Autoscaling based on these indicators provides a more accurate reflection of real system pressure and user experience.
| Reliability Through Orchestration
In production environments, failures are unavoidable. External APIs time out, schemas change, rate limits are exceeded, and model outputs may not always conform to expectations.
Resilient agent systems are designed with these realities in mind. Mature implementations consistently include:
- Explicit timeouts and bounded retries at each step
- Circuit breakers to isolate failing components
- Validation and verification for high-impact actions
- Graceful degradation that returns partial or fallback responses
The objective is not to eliminate failure, but to ensure predictable behavior when failures occur. Reliability builds trust when agents fail safely and transparently.
| Cost as a Design Constraint
AI agents can generate costs rapidly if left unchecked. A single task may trigger multiple model invocations and tool calls, compounding expenses as usage grows.
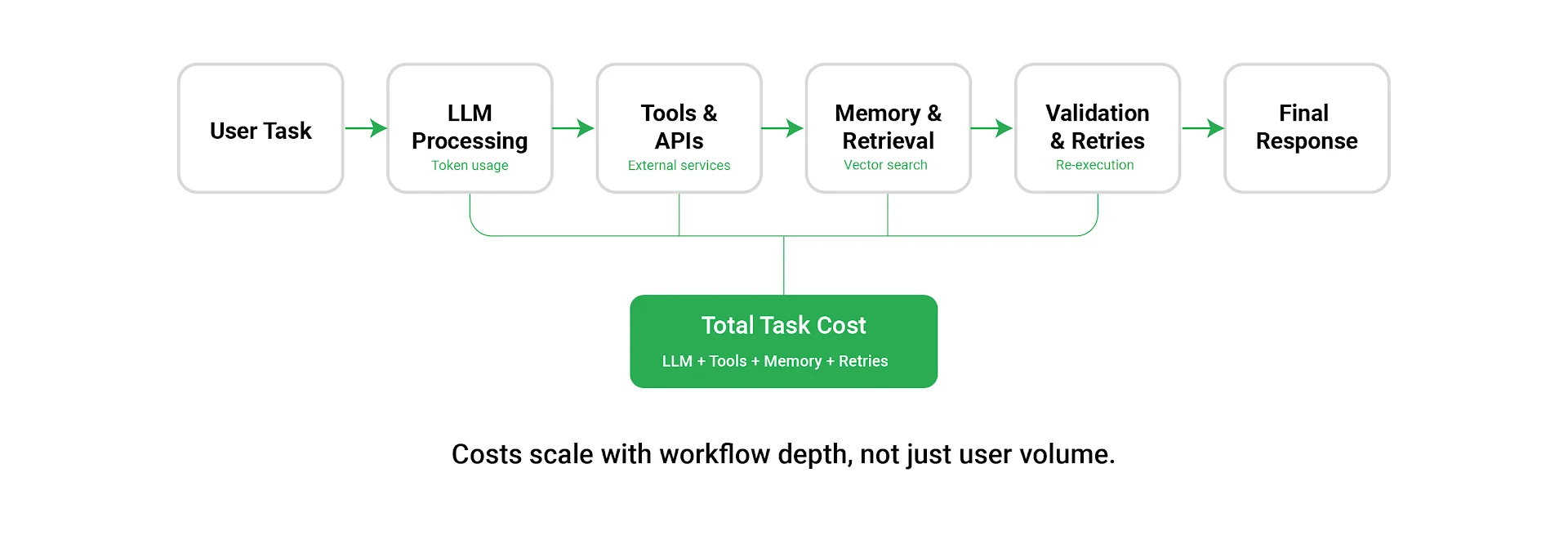
Without visibility into cost per task or cost per outcome, teams lose the ability to predict spend as adoption increases.
Organizations that scale sustainably treat cost as a design-time consideration rather than a post-deployment concern. Common practices include:
- Using lightweight models for routing, extraction, and validation
- Reserving larger models for complex reasoning tasks
- Aggressively summarizing and pruning context
- Monitoring, caching, and limiting tool usage
Predictable cost behavior is essential for long-term adoption and executive confidence. Enterprise agent platforms help enforce these controls consistently across teams, reducing cost variance and operational risk.
| Organizational Readiness and Adoption
Technical success alone does not guarantee adoption.
Many agent initiatives stall due to unclear ownership, lack of alignment with real workflows, or resistance from teams unsure how agents fit into their roles.
Organizations that succeed take a structured, phased approach:
- Tie agent initiatives to measurable business outcomes
- Start with high-volume, repeatable use cases
- Expand incrementally from narrow tasks to broader workflows
- Position agents as assistive systems rather than replacements
Critically, they assign clear ownership. One team is accountable for how the agent behaves in production, who responds when it fails, and how changes are approved as autonomy increases. Without this ownership, even technically sound agents struggle to scale beyond pilots.
| Responsible Scaling and Governance
As agents gain autonomy, governance becomes essential.
Responsible deployments incorporate guardrails that balance automation with accountability:
- Human approval for irreversible or high-impact actions
- Role-based access controls and tool allowlists
- Auditable decision trails and execution logs
- Gradual increases in autonomy based on demonstrated reliability
Trust is built through consistent, predictable behavior and clear accountability.
| Scaling as an Ongoing Discipline
AI agent systems are not static. Models evolve, tools change, business rules shift, and user expectations increase.
Mature teams invest in operational practices such as:
- Regression testing with representative task suites
- Canary and shadow deployments
- Structured feedback beyond simple user ratings
- Fast rollback and recovery mechanisms
Scaling is not a one-time milestone. It is an operational discipline maintained over time.
| A Practical Checklist for Production Readiness
Before expanding agent usage, organizations should assess whether foundational capabilities are in place.
Architecture and Orchestration
- Clear separation between orchestration, models, tools, and memory
- Hard limits on execution steps, retries, and duration
- Safe handling of state and recovery
Scaling and Performance
- Autoscaling driven by backlog and latency metrics
- Asynchronous handling of long-running tasks
- Controlled parallel execution of tool calls
Reliability
- Circuit breakers and bounded retries
- Graceful degradation paths
- Validation for critical actions
Cost Control
- Tiered model selection
- Token and context budgets
- Caching and limits on tool usage
Observability and Operations
- End-to-end tracing across agent steps
- Metrics for latency, success rates, backlog, and cost
- Defined rollback and incident response plans
Safety and Responsibility
- Role-based permissions and allowlists
- Human-in-the-loop for high-risk actions
- Audit logging and compliance alignment
Organizational Readiness
- Clear business KPIs
- Defined ownership and operational responsibility
- Training and structured rollout plans
| Conclusion
Scaling AI agents in production is not about increasing intelligence in isolation. It is about building dependable systems that organizations can trust at scale. That means investing in platform-level orchestration, cost discipline, governance, and clear ownership long before agent usage expands across teams.
When these foundations are in place, AI agents move beyond pilots and proofs of concept. They become reliable components of enterprise workflows, delivering real impact while operating within business, risk, and compliance boundaries.
If AI agents are moving into production, now is the time to assess whether your platform, governance, and operating model are ready to scale responsibly.
Start the conversation: Click Here





