Blogs
Loading data into Redshift using ETL jobs in AWS GLUE

“You can have data without information, but you cannot have information without data.” — Daniel Keys Moran
In continuation of our previous blog of loading data in Redshift, in the current blog of this blog series, we will explore another popular approach of loading data into Redshift using ETL jobs in AWS Glue.
AWS Glue is a serverless data integration service that makes the entire process of data integration very easy by facilitating data preparation, analysis and finally extracting insights from it.
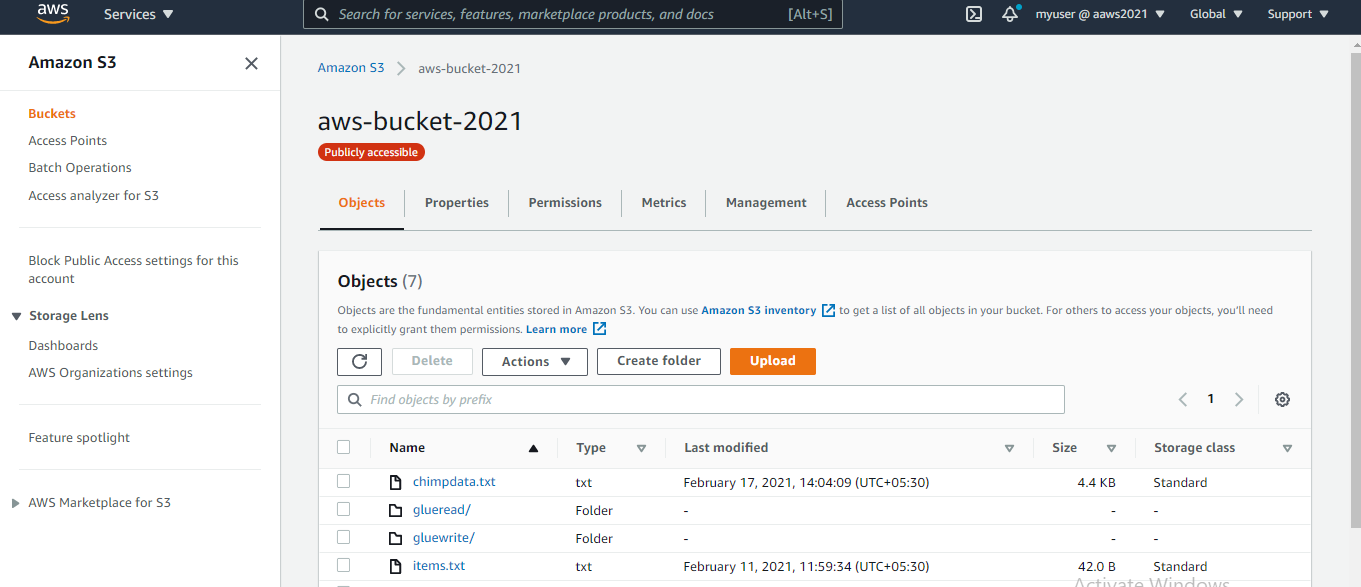
Uploading to S3
We start by manually uploading the CSV file into S3. This comprises the data which is to be finally loaded into Redshift. We are using the same bucket we had created earlier in our first blog.
Upload a CSV file into s3. For this example we have taken a simple file with the following columns:
Year, Institutional_sector_name, Institutional_sector_code, Descriptor, Asset_liability_code, Status, Values
Setting up Redshift
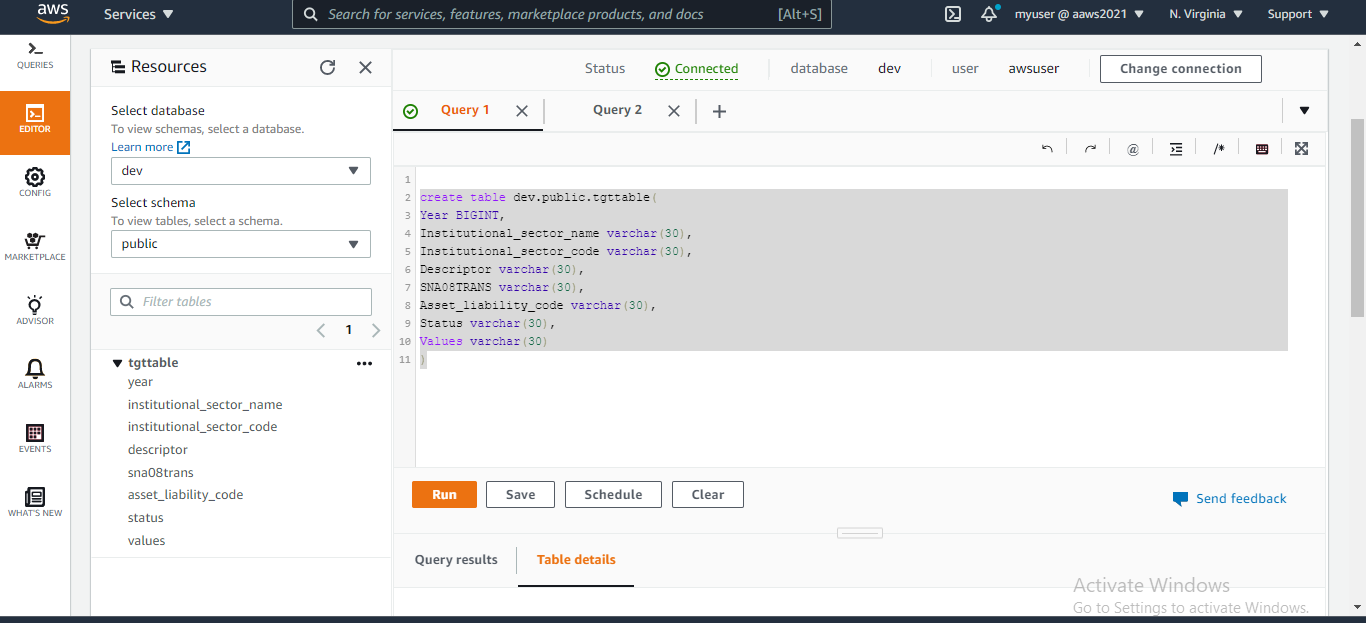
Create a new cluster in Redshift. You should make sure to perform the required settings as mentioned in the first blog to make Redshift accessible. A default database is also created with the cluster.
Next, we will create a table in the public schema with the necessary columns as per the CSV data which we intend to upload.
create table dev.public.tgttable( YEAR BIGINT, Institutional_sector_name varchar(30), Institutional_sector_name varchar(30), Discriptor varchar(30), SNOstrans varchar(30), Asset_liability_code varchar(30),Status varchar(30), Values varchar(30));
Creating IAM roles
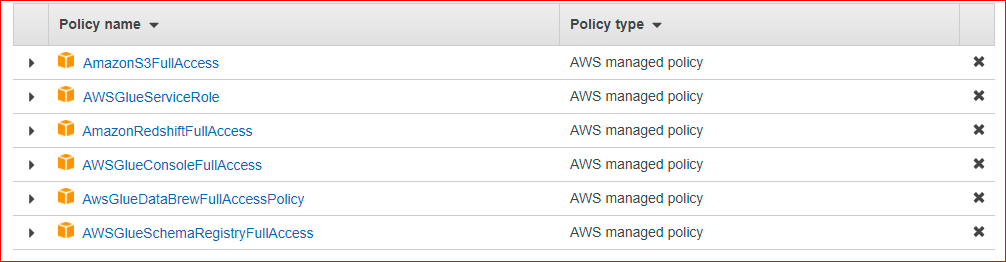
Created a new role AWSGluerole with the following policies in order to provide the access to Redshift from Glue.
Setting up Glue
Step1:
Create a crawler for s3 with the below details.
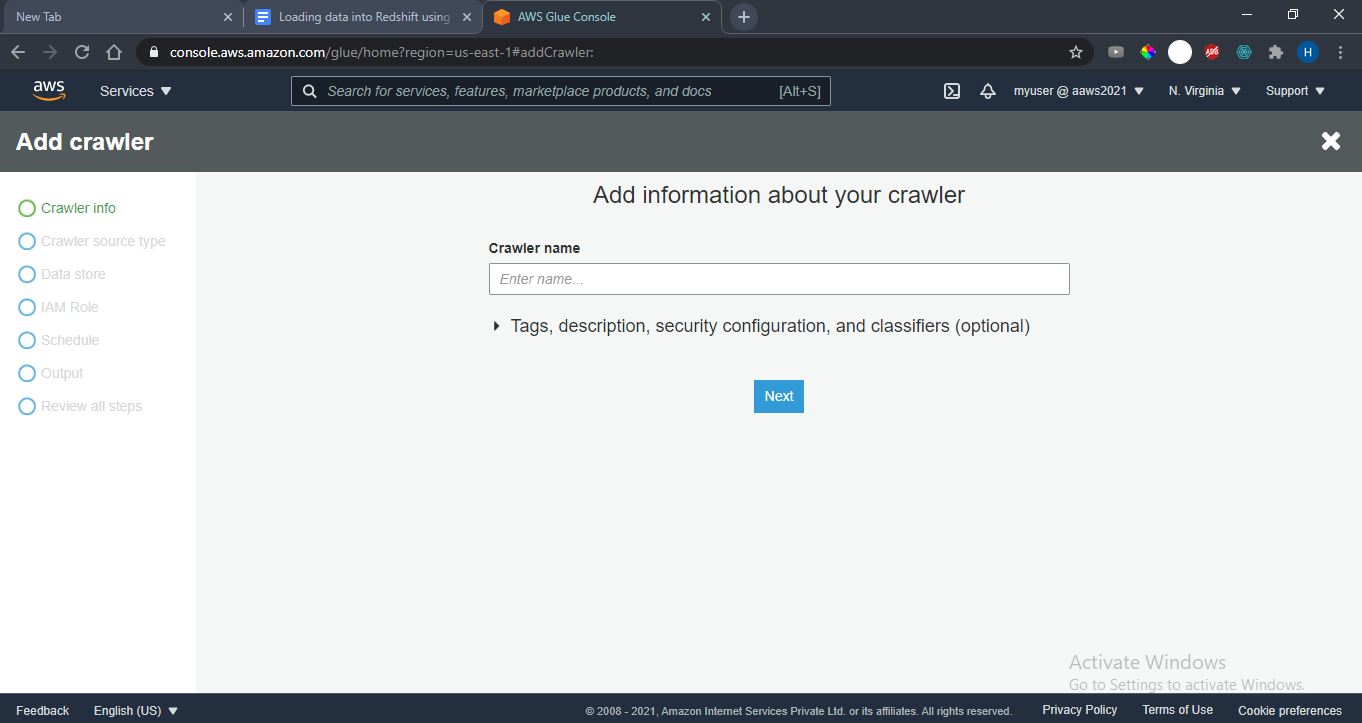
Crawler name: mycrawler
Crawler source type :
Add a data store( provide path to file in the s3 bucket )-
s3://aws-bucket-2021/glueread/csvSample.csv
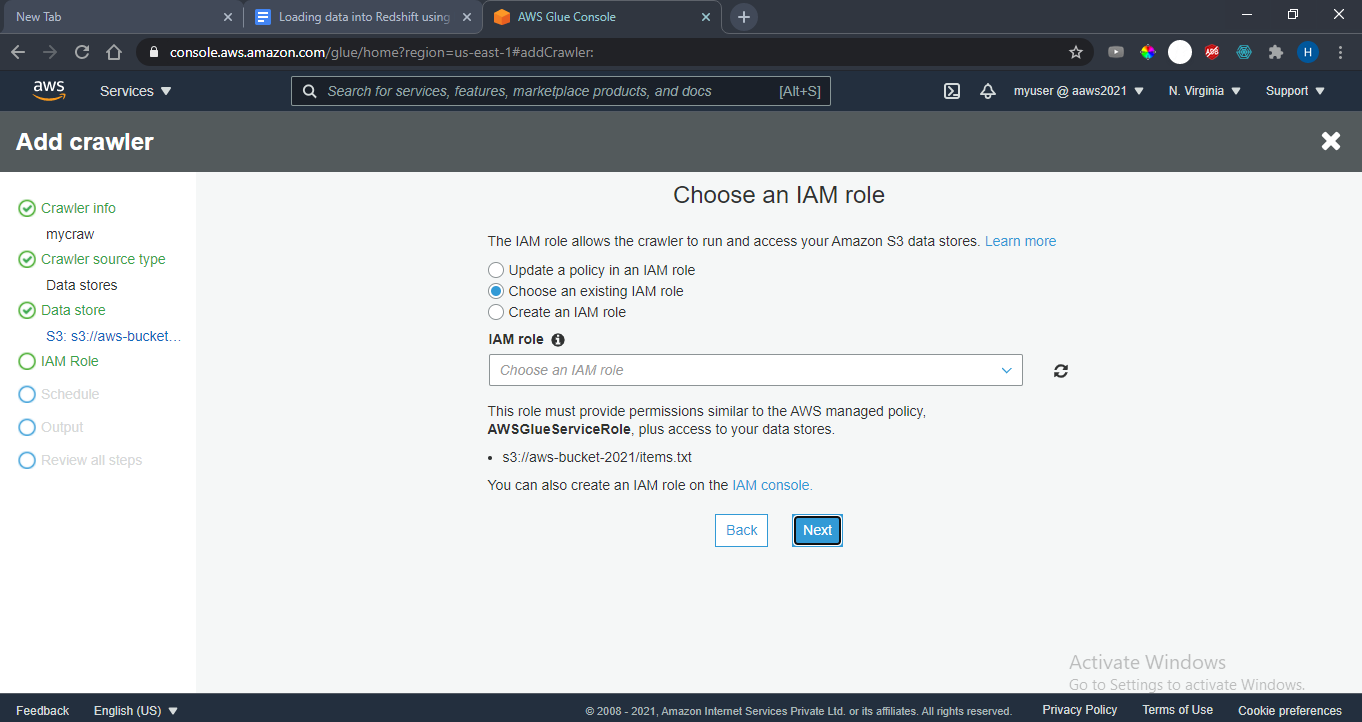
Choose an IAM role(the one you have created in previous step) : AWSGluerole
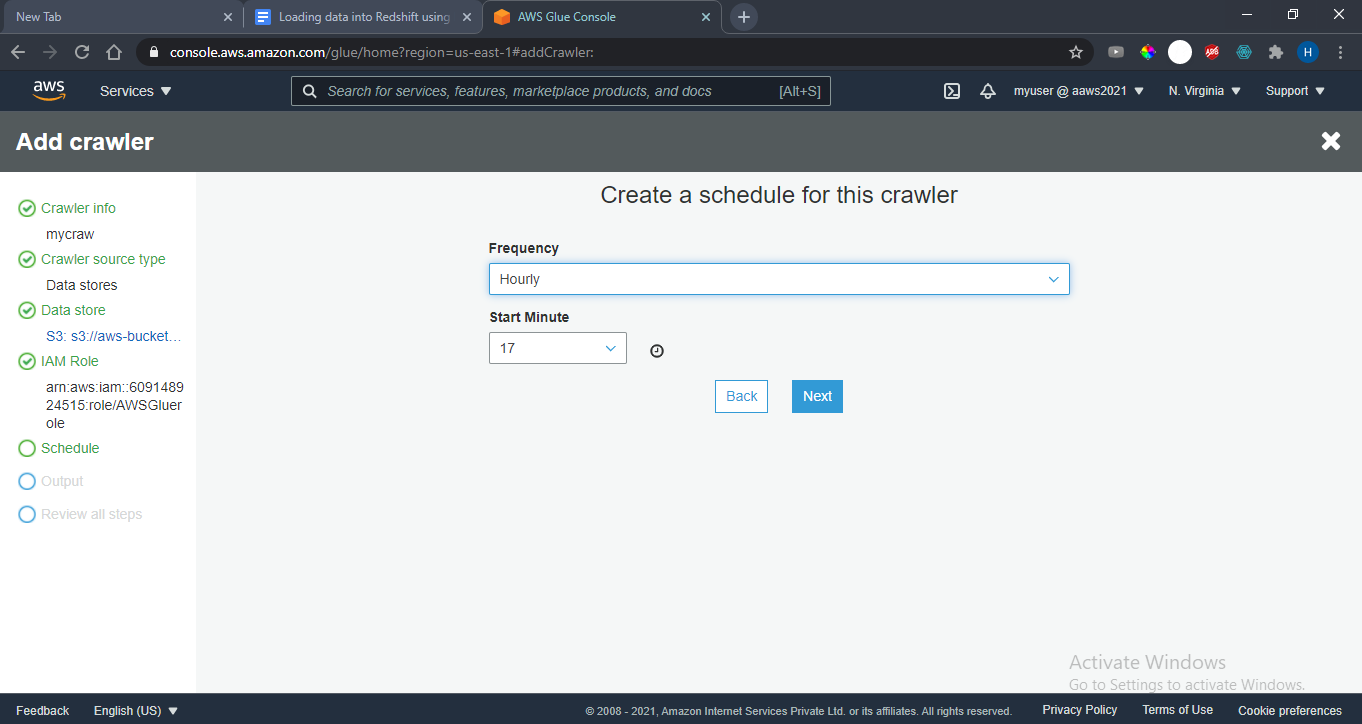
Create a schedule for this crawler. For this example, we have selected the Hourly option as shown.
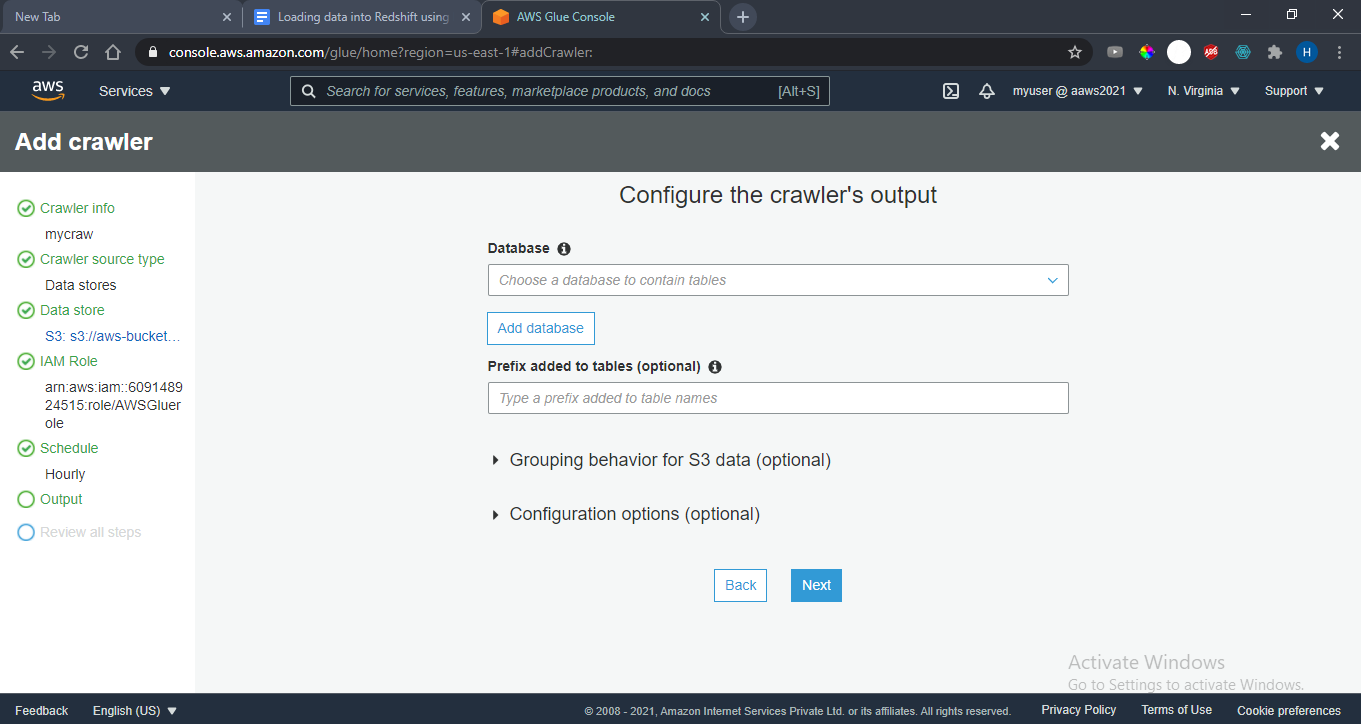
Add and Configure the crawler’s output database . This is a temporary database for metadata which will be created within glue. You can give a database name and go with default settings.
Validate your Crawler information and hit finish.
When running the crawler, it will create metadata tables in your data catalogue.
Step2:
Create another crawler for redshift and then run it following the similar steps as below so that it also creates metadata in the glue database.
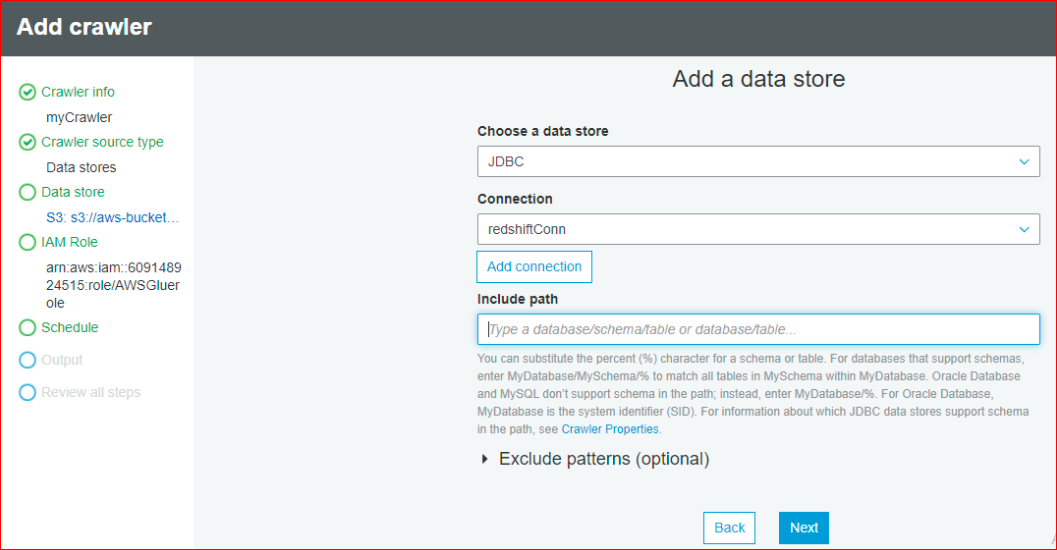
- Select data store as JDBC and create a redshift connection
- Select it and specify the Include path as database/schema/table.
- In case of our example, dev/public/tgttable(which create in redshift)
- Choose the IAM role(you can create runtime or you can choose the one you have already)
- Create a schedule for this crawler
- Add and Configure the crawler’s output database
- Validate your Crawler information and hit finish.
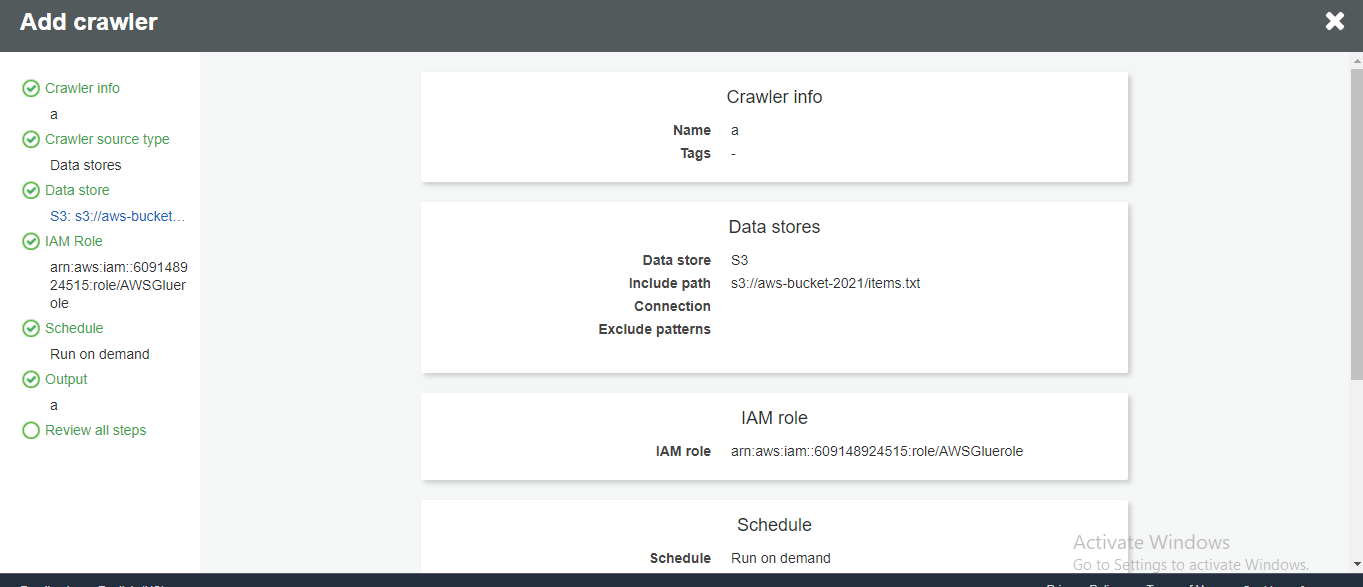
Then Run the crawler so that it will create metadata tables in your data catalogue.
Step3:
Create an ETL Job by selecting appropriate data-source, data-target, select field mapping.
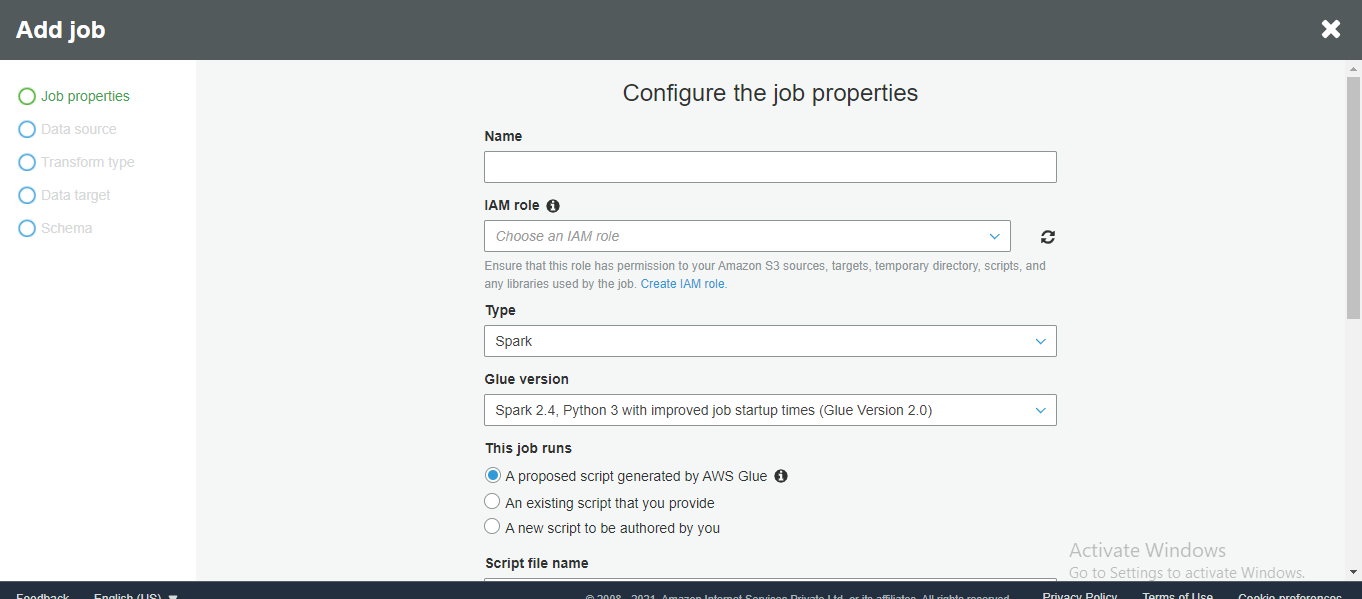
Step4:
Run the job and validate the data in the target
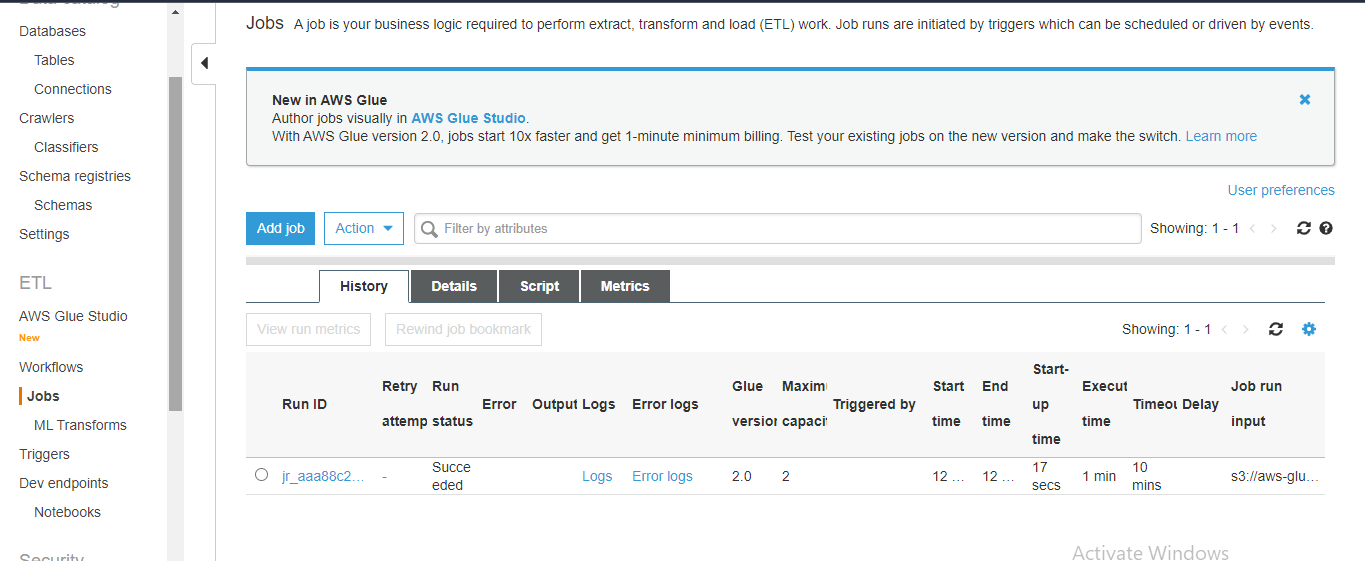
Now, validate data in the redshift database.
You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers.
Conclusion
The aim of using an ETL tool is to make data analysis faster and easier. There are various utilities provided by Amazon Web Service to load data into Redshift and in this blog, we have discussed one such way using ETL jobs. AWS Glue is provided as a service by Amazon that executes jobs using an elastic spark backend. Using Glue helps the users discover new data and store the metadata in catalogue tables whenever it enters the AWS ecosystem.