Blogs
Driving Innovation: Leveraging Open-Source LLMs with Domain Data
Enterprises must balance preserving control over their data and models with maximizing the potential of large language models (LLMs) in today’s data-driven environment. Open-source learning management systems (LLMs) present a strong alternative, giving institutions the adaptability and clarity required to spur creativity and make wise choices. Enterprises can have total control over their model ecosystem and tailor and optimize models to meet their specific goals by utilizing open-source LLMs.
However, the real promise of LLMs is found in their capacity to use domain-specific data to enhance their skills and understanding. Businesses can further improve the relevance and accuracy of generated insights by integrating domain-specific data into LLMs using the retrieval augmented generation approach. According to this innovative method, businesses can now effortlessly integrate the strength of pre-trained LLMs with real-time data retrieval, giving them unprecedented access to actionable insights from their data.
Organizations can get ultimate value from a multitude of use cases when they enhance open-source LLMs with domain-specific data utilizing the retrieval augmented generation (RAG) technique. These use cases include financial services, healthcare, and beyond.
In the financial services industry, for example, banks and investment firms can use this methodology to evaluate investment opportunities, analyze market trends, and give clients individualized financial advice based on real-time market data. Medical practitioners can increase diagnostic accuracy, create individualized treatment regimens, and carry out large-scale medical research by using open-source LLMs supplemented with domain-specific medical literature and patient data. Similarly, e-commerce businesses can improve customer experiences by utilizing open-source LLMs trained on domain-specific product catalogs and customer interactions to generate personalized product suggestions, optimize search results, and automate customer assistance. These are only some instances of how industries can be revolutionized and new avenues for growth and innovation can be opened up by integrating open-source LLMs with domain-specific data.
There are a variety of Open source models available for you to select and use based on your need and use case. You can select and choose from the models available at Huggingface.
In one of our earlier blogs, we looked at using multi-modal techniques to extract data from PDF tables and use it for the knowledge augmentation of LLMs.
In this blog, we will be looking at using Open-source LLMs with augmented knowledge to fit into any application scenario that needs LLMs enhanced with domain-specific know-how.
RAG with Mistral models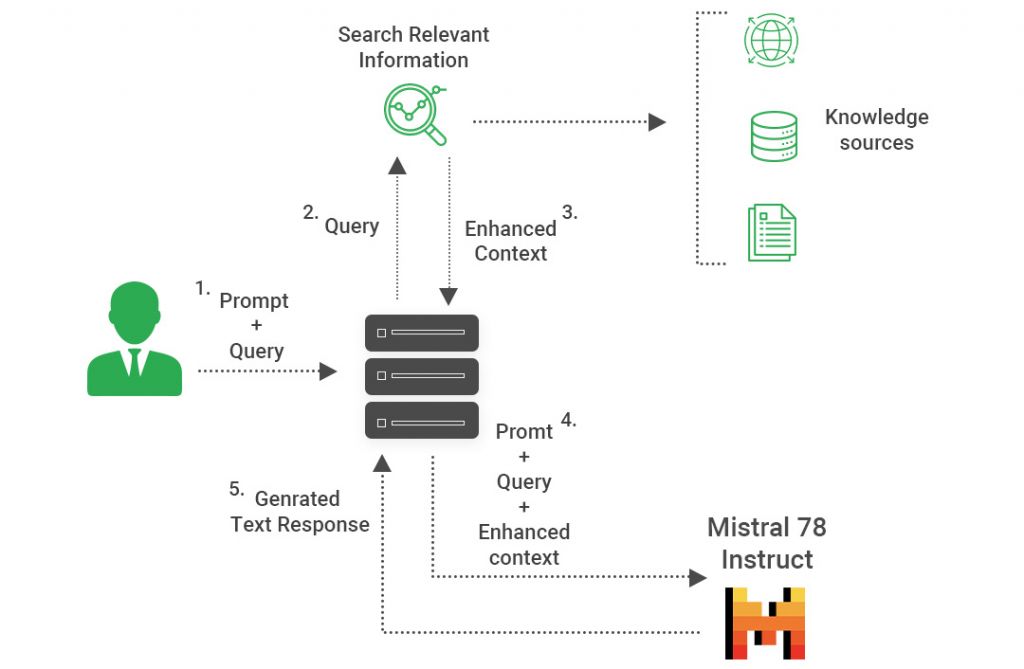
The Open-source model Mixtral 8x7B will be used in today’s blog post. The Mistral models are emerging as one of the greatest open-source LLM substitutes.

Mixtral 8x7B is a high-quality sparse mixture of expert models (SMoE) with open weights, licensed under Apache 2.0.
- It outperforms Llama 2 70B on most benchmarks, delivering 6x faster inference.
- Mixtral is the strongest open-weight model available with a permissive license, offering the best cost/performance trade-offs.
- It matches or outperforms GPT3.5 on most standard benchmarks.
- Mixtral gracefully handles contexts of up to 32k tokens.
- It supports multiple languages including English, French, Italian, German, and Spanish.
- Mixtral exhibits strong performance in code generation tasks.
- It can be fine-tuned into an instruction-following model, achieving a score of 8.3 on MT-Bench.
|How to run the Mixtral model
The open-source models can be used in the cloud or on your personal computers. Many cloud service providers offer endpoints for using open-source LLMs, like as Mistral.
To run on-premise
With the technical specifications of an NVIDIA RTX 6000 Graphic Card and
using the Ollama library you can run the instance of the model on your system.
Using providers like Groq
This is a more straightforward and practical method of using open-source models without requiring additional infrastructure investments.
We will be using the Mixtral model through Groq provider in this blog. This is a really practical method of using the LLMs that are available to try out the different models and decide which one is most suitable for your use case. Other suppliers include together.ai and DeepInfra.
Sign up in Groq and get your API key
Select the API keys when visiting the console playground. Make a fresh API key for yourself.
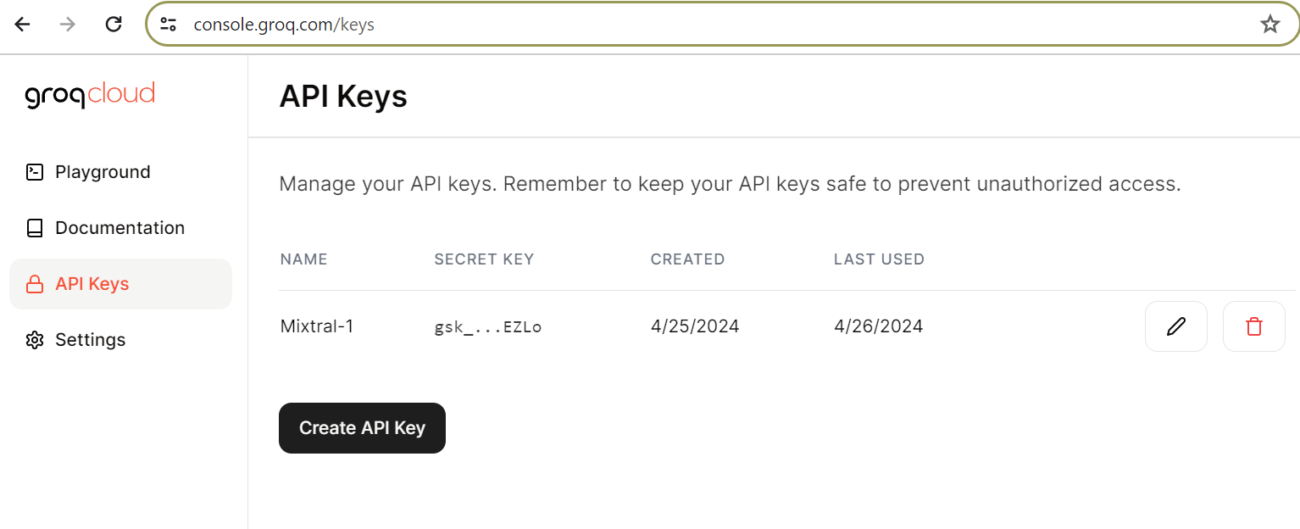
Once you have the API key, all you need to do is assign it to the environment variable GROQ_API_KEY.
This is to begin utilizing the product; if you are using it for a production use case, you can request an enterprise version.
Installing the Prerequisites to get started
The prerequisites required for this use case are listed here. In this example, I’ll be employing our Case Studies PDF document and using Mixtral to create an RAG over top of it.
!pip install faiss-cpu “mistralai>=0.1.2” !pip install chromadb !pip install unstructured “unstructured[pdf]” !pip install groq !pip install fastembed !pip install transformers -U !pip install llama-index !pip install pdf2image !apt-get install poppler-utils ! apt install tesseract-ocr ! apt install libtesseract-dev !pip install langchain langchain_groq ! pip install Pillow ! pip install pytesseract
Create your Vector DB with embeddings
Let’s place the document in the data folder and start by creating a vector database as below
Include the imports.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from groq import Groq
from langchain_groq import ChatGroq
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Create vector database
def create_vector_database():
"""
Creates a vector database using document loaders and embeddings.
This function loads data,
splits the loaded documents into chunks, transforms them into embeddings using FastEmbed,
and finally persists the embeddings into a Chroma vector database.
"""
# Reading documents and setting up the system prompt
# documents = SimpleDirectoryReader("./data").load_data()
loader = DirectoryLoader('./data/', glob="**/*.*", show_progress=True)
documents = loader.load()
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
#len(docs)
print(f"length of documents loaded: {len(documents)}")
print(f"total number of document chunks generated :{len(docs)}")
#docs[0]
# Initialize Embeddings
embed_model = FastEmbedEmbeddings(model_name="BAAI/bge-base-en-v1.5")
# Create and persist a Chroma vector database from the chunked documents
vs = Chroma.from_documents(
documents=docs,
embedding=embed_model,
persist_directory="chroma_db_llamaparse1", # Local mode with in-memory storage only
collection_name="rag"
)
print('Vector DB created successfully !')
return vs,embed_model
Let’s invoke the function and create the vector database as shown below.
vs,embed_model = create_vector_database()
Set up the retriever for Question answering on top of the Vector DB
import os
#Instantiating the Groq Chat Model
chat_model = ChatGroq(temperature=0,
model_name="mixtral-8x7b-32768",
api_key=os.getenv("GROQ_API_KEY"),)
vectorstore = Chroma(embedding_function=embed_model,
persist_directory="chroma_db_llamaparse1",
collection_name="rag")
#
retriever=vectorstore.as_retriever(search_kwargs={'k': 3})
custom_prompt_template = """Use the following pieces of information to answer the user's question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Context: {context}
Question: {question}
Only return the helpful answer below and nothing else.
Helpful answer:
"""
def set_custom_prompt():
"""
Prompt template for QA retrieval for each vectorstore
"""
prompt = PromptTemplate(template=custom_prompt_template,
input_variables=['context', 'question'])
return prompt
#
prompt = set_custom_prompt()
prompt
########################### RESPONSE ###########################
PromptTemplate(input_variables=['context', 'question'], template="Use the following pieces of information to answer the user's question.\nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\n\nContext: {context}\nQuestion: {question}\n\nOnly return the helpful answer below and nothing else.\nHelpful answer:\n")
qa = RetrievalQA.from_chain_type(llm=chat_model,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": prompt})
response = qa.invoke({"query": "Give case studies related to Finance"})
Below are some responses provided by the model, which are both accurate and correct!
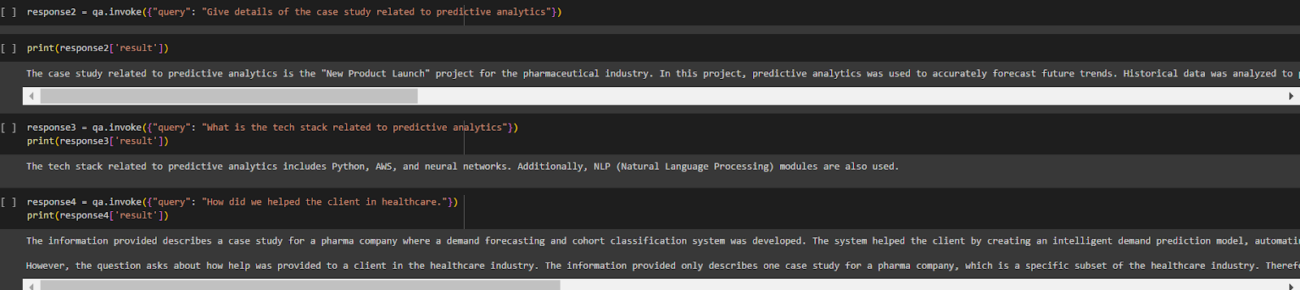
You can now start enhancing the effectiveness of Open-source LLMs by tailoring them to your specific use case by augmenting their knowledge, fine-tuning with domain-specific data, integrating relevant APIs, and employing transfer learning techniques.
Through the use of Retrieval-Augmented Generation (RAG) and open-source models, businesses can unlock value from their extensive document archives that were previously unrealized. This strategy is perfect for companies who are investigating the possibilities of GenAI but are hesitant to implement closed models. Through the utilization of these potent models, either in-house or via specialized cloud providers, enterprises can initiate a revolutionary shift towards sophisticated intelligent document extraction and improved Q&A capabilities.
Employing open-source models such as Mixtral and enhancing their expertise with pre-existing document libraries and applications, businesses may effectively leverage their data and stimulate creativity. By utilizing RAG architecture to bridge the gap between language models and domain-specific data, organizations may leverage the complete control and flexibility of open-source models along with the richness and precision of generated replies.
Businesses may now use the combined knowledge contained in their data to their advantage and customize AI models to fit their unique domain expertise without requiring a great deal of pretraining or fine-tuning.
For more insights, check out our webinar recording: Navigating Open Source Potential for Enterprise Growth by WalkingTree Technologies