Blogs
Fine-Tuning Open Source Language Models for Business Applications Using Predibase
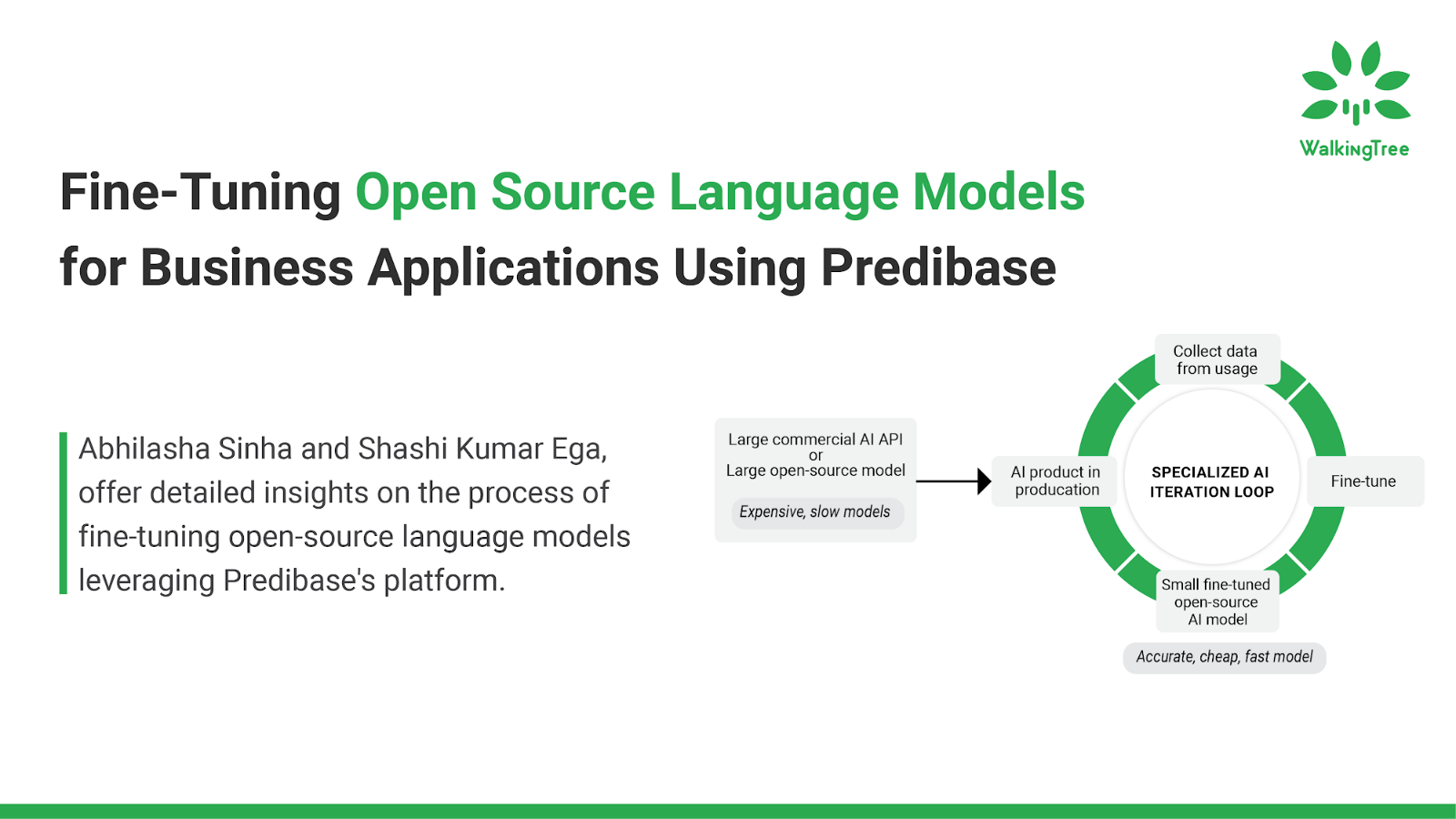
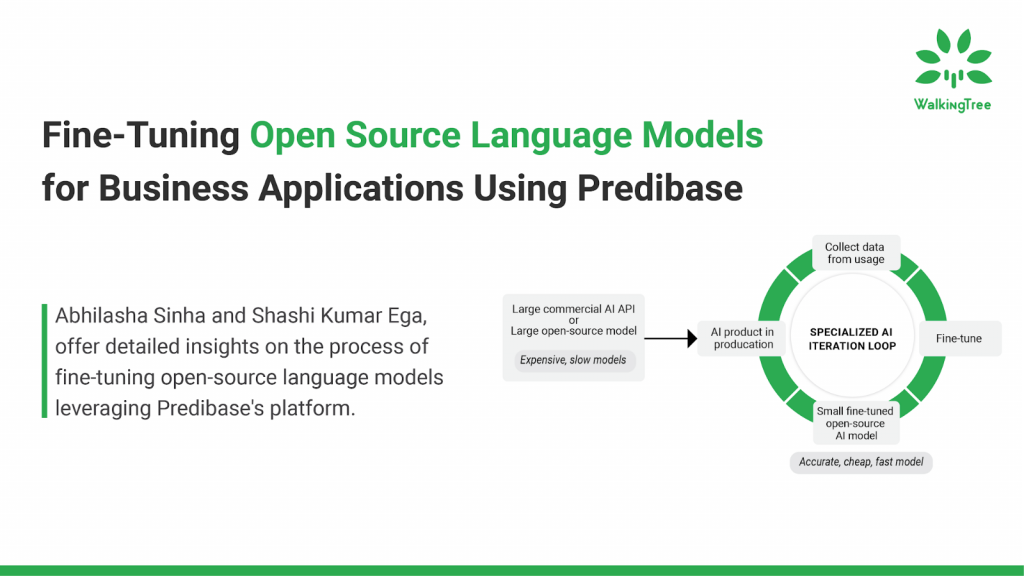
The advent of open-source language models has transformed the field of natural language processing (NLP) and brought more power and flexibility to the hands of users with additional transparency. These models, pre-trained on extensive datasets, provide a robust foundation for various linguistic tasks. However, to further enhance their potential for specific business applications, fine-tuning can be an excellent approach making the model tuned to your requirements. If you wish to learn more about the Fine-tuning process, you can refer to our previous blog, which explores how fine-tuning pre-trained language models, such as those from Meta and Mistral, can be customized to meet specific business requirements. It emphasizes the benefits of fine-tuning, such as improved model performance and efficiency, while also addressing potential challenges and providing solutions for effective implementation.
In this blog, we’ll explore the technical intricacies of fine-tuning open-source models, particularly Mistral-7B, using Predibase. We will delve into the step-by-step process, from model selection to deployment, highlighting the critical aspects that make this approach highly effective for enterprise-level applications.
|Selecting a Pre-Trained Model and Platform
Selecting the appropriate pre-trained model and deployment platform is crucial for the success of fine-tuning tasks. Ensuring the model’s architecture, capabilities, and supporting tools align with your specific business needs and objectives is essential for achieving optimal performance and desired outcomes.
Choosing Mistral-7B
Mistral-7B, a powerful pre-trained language model, offers a versatile foundation for numerous NLP tasks. Its architecture, based on transformer networks, allows it to process and generate human-like text efficiently. This model’s extensive pre-training on diverse datasets makes it a suitable candidate for fine-tuning to meet specific business needs.
Utilizing Predibase
Predibase stands out as an ideal platform for fine-tuning due to its comprehensive tools and user-friendly interface. It facilitates seamless integration with pre-trained models and offers extensive customization options for fine-tuning. Creating an account on Predibase and securing an API token is the initial step towards leveraging its capabilities.
Follow the below steps to Create a Predibase account and Predibase API Token
Step 1: Go to https://app.predibase.com/ and Click on try predibase.

Step 2: Click on sign up
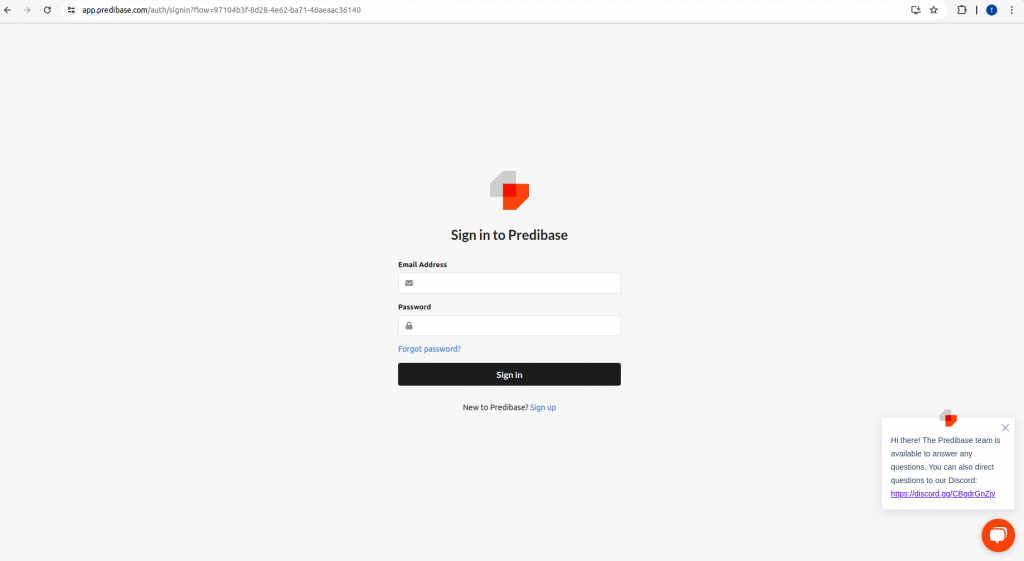
Step 3: Fill in the necessary fields, for How would you like to try predibase (use predibase cloud only)default one, and click on submit.
Step 4: You will see the below window.
Step 5: Open mail and click on accept an invitation.
Step 6: Enter your email address.
Step 7: Enter your email address, create a password and give first and last names.
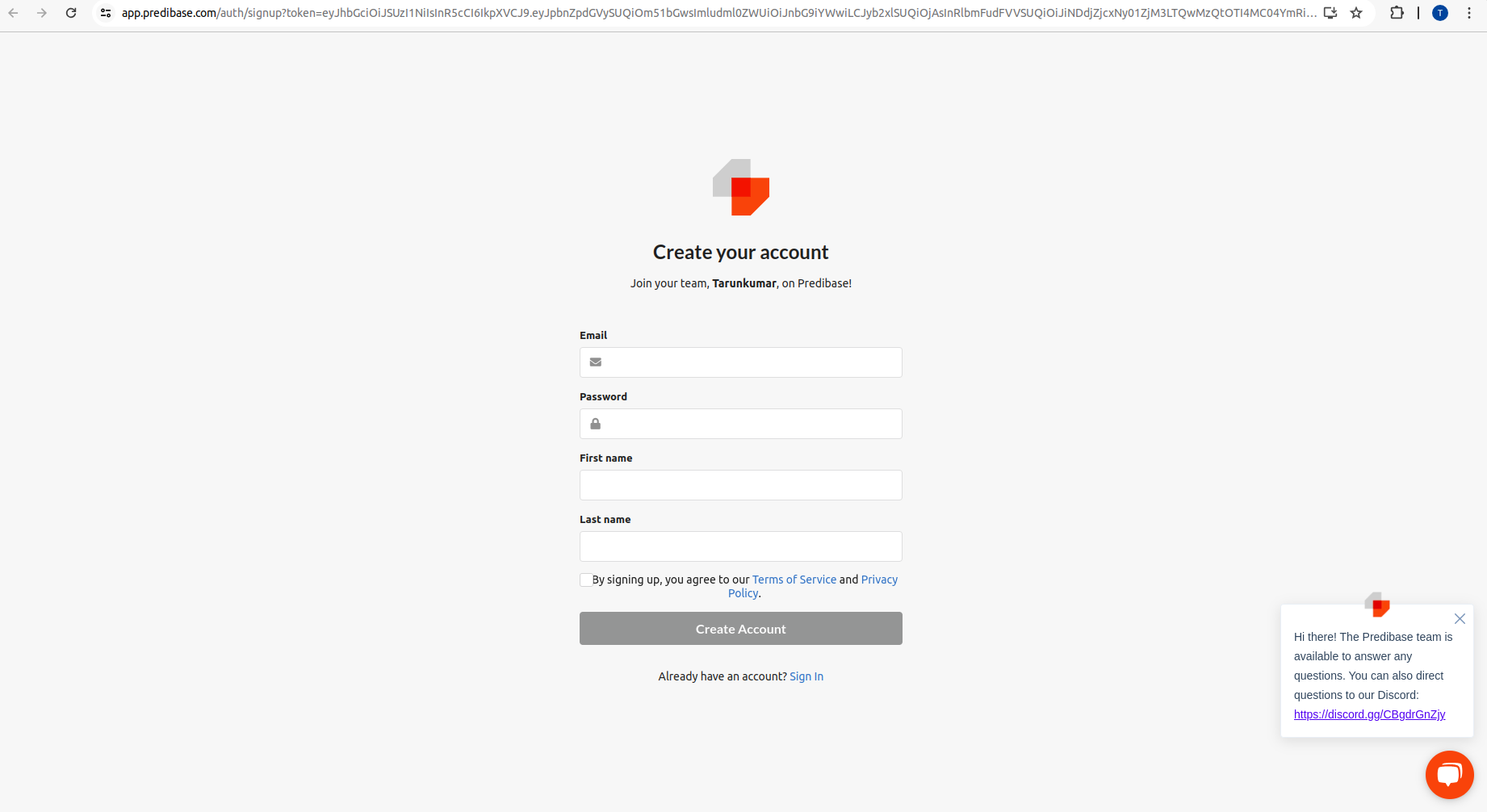
Step 8: Click on generate, and you will get an API Token
|Preparing the Dataset
Data set preparation is the most important step to ensure an effective fine tuning outcome. The data set should cover a wide variety of cases and also be free from any kind of biases.
Data Collection
The first step in preparing a dataset involves collecting relevant data.
In this blog we will use the example of fine-tuning the model for Named Entity Recognition (NER) for resume related fields, for which collecting a large number of resumes can provide a rich dataset. These resumes, typically stored in various formats like .docx, .doc, and .pdf, need to be standardized for processing as part of data preparation.
Data Extraction and Formatting
Using Python packages such as Textract, PyPDF2, and PaddleOCR, text can be extracted from the collected resumes. The extracted text should be stored in a CSV file, ensuring uniformity. This process involves reading the files, extracting the text, and writing it into a structured CSV format.
The code below is an example for extracting text from a PDF file using PyPDF2. Similarly, you need to collect examples for extracting text from DOCX and DOC files using Textract.
import textract
import PyPDF2
import pandas as pd
# Example of extracting text from PDF
def extract_text_from_pdf(file_path):
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfFileReader(file)
text = ''
for page in range(reader.numPages):
text += reader.getPage(page).extractText()
return text
# Storing extracted text in a CSV file
resumes = ["resume1.pdf", "resume2.pdf", "resume3.pdf"]
data = []
for resume in resumes:
text = extract_text_from_pdf(resume) if resume.endswith('.pdf') else textract.process(resume).decode('utf-8')
data.append({"Resume Text": text})
df = pd.DataFrame(data)
df.to_csv("resumes.csv", index=False)
Entity Extraction
Once the text is extracted, the next step is to extract entities. This involves using an entity extraction script that processes the text and identifies relevant entities such as names, email addresses, job titles, and companies. We will create the data set with the extracted entities using a more powerful model like GPT4o or Mixtral 8x7B(Hosted on Groq).
import pandas as pd
from groq import Groq
import json
from datetime import datetime
from dotenv import load_dotenv
load_dotenv()
GROQ_API_KEY = os.environ["GROQ_API_KEY"]
CSV_FILE_PATH = "resumes.csv"
current_date = datetime.now().strftime("%Y-%m-%d")
# Read the CSV file into a DataFrame
df = pd.read_csv(CSV_FILE_PATH)
df = df.iloc[:3000] # Limiting to 3000 for processing
client = Groq(api_key=GROQ_API_KEY)
json_str_list = []
for index, row in df.iterrows():
resume_text = row["Resume Text"]
system_message = f"""<s>[INST]
Today's Date: {current_date}
**Task** - Extract entities from resume text.
**Attributes**: First Name, Last Name, Email ID, Mobile number, Location, Designation, Company, Experience, Primary Skills.
[/INST]"""
user_message = f"{resume_text}"
messages = [{'role':'system', 'content': system_message}, {'role':'user', 'content': user_message}]
chat_completion = client.chat.completions.create(model="mixtral-8x7b-32768", messages=messages, temperature=0.0)
text = f"{messages[0]['content']} {messages[1]['content']} {chat_completion.choices[0].message.content} </s>"
json_data = {'text': text, "index": index}
json_str = json.dumps(json_data)
json_str_list.append(json_str)
with open('output_file.jsonl', 'a') as jsonl_file:
jsonl_file.writelines(json_str_list)

|Fine-Tuning the Model
Uploading the Dataset to Predibase
With the dataset prepared, the next step is to upload it to Predibase. This involves converting the JSONL file into a CSV format required for fine-tuning and then using the Predibase API to upload the dataset.
python
Copy code
import pandas as pd
# Convert JSONL file to DataFrame
df = pd.read_json("output_file.jsonl", lines=True)
# Preparing data for fine-tuning
prompts = []
completions = []
for text in df['text']:
prompt = text.split("\n\n####")[0].replace("<s>[INST]", "").strip()
passage = text.split("\n\n####")[1].split("####")[0]
prompts.append(f"{prompt}\n\nPassage:{passage}\n\nSummary:[/INST]")
completions.append(text.split("####")[1])
# Convert lists to DataFrame
fine_tuning_data = pd.DataFrame({'prompt': prompts, 'completion': completions, 'split': ['train'] * len(prompts)})
fine_tuning_data.to_csv("fine_tuning_data.csv", index=False)

|Configuring Fine-Tuning Parameters
Predibase offers extensive options for customizing the fine-tuning process. Parameters such as epochs, rank, and learning rate can be adjusted to optimize the model’s performance.
Epochs:
An epoch is one complete pass through the entire training dataset. During one epoch, the model processes each training example once, allowing it to learn from the data. Multiple epochs are often used during training because one pass through the data is typically not enough for the model to learn effectively. By using multiple epochs, the model has multiple opportunities to adjust its weights and improve its performance.
Rank:
In the context of neural networks, “rank” can have a couple of meanings:
- Tensor Rank: This refers to the number of dimensions of a tensor. For example, a scalar has rank 0, a vector has rank 1, a matrix has rank 2, and so on.
- Model Rank: In some contexts, especially in collaborative filtering and recommendation systems, “rank” can refer to the number of latent factors or features in matrix factorization techniques.
Learning Rate
The learning rate is a hyperparameter that controls the step size at each iteration while moving toward a minimum of the loss function. It determines how quickly or slowly a model learns. A smaller learning rate means the model learns slowly but can converge more precisely, while a larger learning rate can speed up the training process but might cause the model to overshoot the minimum and not converge effectively. Choosing an appropriate learning rate is crucial for the training process, affecting the model’s ability to find the optimal solution.
|Illustration of these concepts in training a neural network:
- Epochs: Imagine reading a book multiple times. Each complete reading is an epoch. The more times you read it, the better you understand the content.
- Rank (Tensor Rank): Consider a spreadsheet. If it has just a single row (a vector), its rank is 1. If it has multiple rows and columns (a matrix), its rank is 2.
- Learning Rate: Think of learning to ride a bike. If you make big adjustments quickly (high learning rate), you might overshoot and fall. Making small adjustments (low learning rate) takes longer, but you gradually get better without losing too much.
from predibase import Predibase, FinetuningConfig
PREDIBASE_API_TOKEN = 'your_predibase_api_token'
pb = Predibase(api_token=PREDIBASE_API_TOKEN)
# Upload the dataset to Predibase
dataset = pb.datasets.from_file("fine_tuning_data.csv", name="NER_Dataset")
# Fine-tuning configuration
finetuning_config = FinetuningConfig(
base_model="mistral-7b",
epochs=3,
rank=16,
learning_rate=0.0002
)
# Start fine-tuning
adapter = pb.adapters.create(
config=finetuning_config,
dataset=dataset,
repo="ner-model-repo",
description="Fine-tuning Mistral-7B for NER"
)
|Deployment and Testing
Deploying the Fine-Tuned Model
Deployment involves setting up a serverless endpoint on Predibase, allowing seamless integration of the fine-tuned model into business applications.
# Deploy the model
deployment = pb.deployments.create(
model="mistral-7b",
adapter_id="ner-model-repo/1",
deployment_name="NER_Model_Deployment"
)
# Test the deployment
lorax_client = pb.deployments.client(deployment.deployment_name)
test_prompt = "Provide the entities from the following resume text..."
result = lorax_client.generate(test_prompt)
print(result.generated_text)
Testing and Validation
Rigorous testing is crucial to ensure the model performs as expected in real-world scenarios. This involves running the model against various test cases and evaluating its performance.
test_prompts = ["Extract entities from resume text: John Doe, john.doe@example.com, Software Engineer at ABC Corp...",
"Identify entities in this text: Jane Smith, jane.smith@example.com, Data Scientist at XYZ Inc..."]
for prompt in test_prompts:
result = lorax_client.generate(prompt)
print(result.generated_text)
Hyperparameter Optimization
Fine-tuning does not end with the initial training. Continuous optimization of hyperparameters like epochs, rank, and learning rate can further enhance the model’s performance.
# Reconfiguring hyperparameters for further fine-tuning
optimized_config = FinetuningConfig(
base_model="mistral-7b",
epochs=5,
rank=8,
learning_rate=0.0001
)
# Start a new fine-tuning job with optimized parameters
optimized_adapter = pb.adapters.create(
config=optimized_config,
dataset=dataset,
repo="ner-model-repo",
description="Optimized fine-tuning for NER"
)
|Handling Errors and Troubleshooting
Common Issues
During fine-tuning, some common errors which can arise.
Error 1: ValueError: Trailing data
This error typically occurs when reading a JSON file that is not correctly formatted.
import json
# Handling JSON formatting issues
def validate_json(json_string):
try:
json.loads(json_string)
return True
except ValueError as e:
print(f"Invalid JSON: {e}")
return False
with open('output_file.jsonl', 'r') as file:
lines = file.readlines()
valid_lines = [line for line in lines if validate_json(line)]
with open('validated_output_file.jsonl', 'w') as file:
file.writelines(valid_lines)
Error 2: API Token Issues
Another common issue is an incorrect or undefined API token. Ensuring that the correct token is used and properly defined in the environment variables can prevent such errors.
import os
# Ensure correct API token usage
PREDIBASE_API_TOKEN = os.getenv('PREDIBASE_API_TOKEN')
if not PREDIBASE_API_TOKEN:
raise EnvironmentError("Predibase API token not defined")
|Conclusion
Fine-tuning open-source language models like Mistral-7B using Predibase empowers businesses to tailor NLP capabilities to their unique needs. With WalkingTree Technologies‘ expertise, meticulous dataset preparation, parameter configuration, and rigorous model testing, enterprises can significantly enhance their AI-driven applications. Continuous optimization ensures reliability and efficiency, driving innovation across business processes.
This comprehensive guide underscores the technical depth and precision required to fine-tune language models effectively, providing valuable understanding for users aiming to leverage AI for competitive advantage. Visit our website and explore how our solutions can benefit your organization.