Blogs
LangSmith: Elevating Performance via Effective Evaluation

 At the heart of every remarkable LLM based application lies a critical component that often goes unnoticed: Evaluation. In continuation to my previous blog where we got introduced to LangSmith, in this blog we explore how LangSmith, a trailblazing force in the realm of AI technology, is revolutionizing the way we approach LLM based applications through its effective evaluation techniques.
At the heart of every remarkable LLM based application lies a critical component that often goes unnoticed: Evaluation. In continuation to my previous blog where we got introduced to LangSmith, in this blog we explore how LangSmith, a trailblazing force in the realm of AI technology, is revolutionizing the way we approach LLM based applications through its effective evaluation techniques.
Evaluation stands as a cornerstone in the development and deployment of Large Language Models (LLMs) and the applications they underpin, a fact that underscores both its importance and the intricate challenges it presents. With the remarkable capabilities of LLMs to generate human-like text, robust evaluation becomes paramount to ensure the quality, coherence, and reliability of the output. However, the complexity of language nuances, contextual understanding, and the subjective nature of creative content make traditional evaluation methods fall short.
The inherent diversity of user needs and expectations further complicates matters. Striking a balance between automated metrics and human judgment is a delicate art, as one must capture the depth of linguistic expression, relevancy, and intent. As LLMs continue to permeate various sectors, devising evaluation strategies that can holistically gauge their performance, adaptability, and ethical considerations becomes a challenging pursuit—one that necessitates innovative solutions to accurately assess and enhance the efficacy of these powerful language technologies.
In this blog, we will look at the approaches to evaluating the LLM-based apps using Langsmith.
As an example, I have used an Entity-extraction use case where we are using LLMs to extract entities from different resumes in different formats to convert them into structured searchable data formats.
The expected response is in a Structured Json format so that the extraction and comparison can be more straightforward. Even if it is plain text, it can be used to score by comparing expected result with actual result.
Irrespective of the format of the response, the main idea of evaluation is being able to score how well your actual results are matching your expected results.
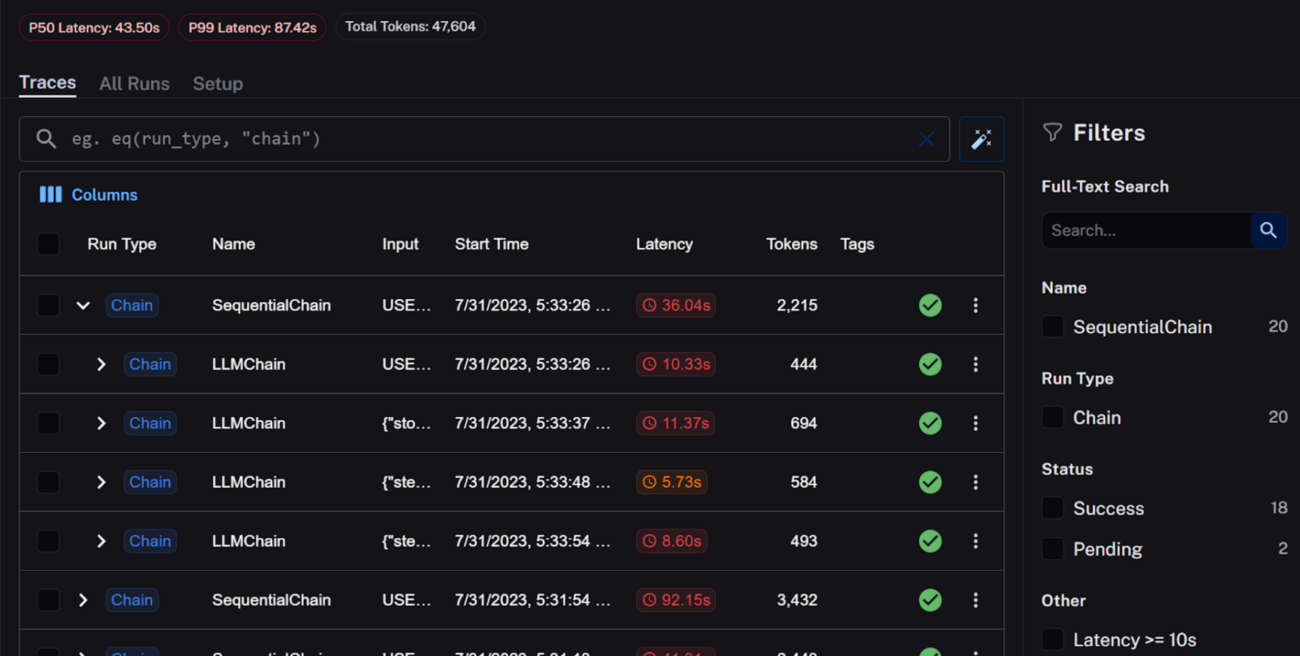
|Getting started with prerequisites
After having installed LangChain and Openai and configuring your environment to connect to LangSmith, follow the below steps to get started.
pip install -U "langchain[openai]" export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com export LANGCHAIN_API_KEY=<your api key>
|Preparing the Dataset
The first step to evaluation is preparing a dataset with inputs and expected outputs. Depending on your use case, you can either use existing datasets and build on top of that or prepare datasets from scratch.
As part of Langsmith, you can prepare datasets from your actual runs by using the option of Add to Dataset and work to evaluate your runs through the same. You can prepare your dataset by
1. Using examples from existing runs by Adding to Dataset
2. Generate examples outside the system and add them to datasets using the upload option. You can create CSV for input and output datasets and upload them directly here too.

Using LLM for generation of examples
You can use LLM to generate examples for Question answering use cases based on your data as shown below.
from langchain.evaluation.qa import QAGenerateChain
example_gen_chain = QAGenerateChain.from_llm(ChatOpenAI())
new_examples = example_gen_chain.apply_and_parse(
[{"doc": t} for t in data[:5]]
)
|Evaluation Approach
In most use cases, we evaluate by comparing the prediction with the expected answer and use a scoring mechanism to quantify the performance intuitively.
Define LLM, chain, or agent to evaluate
Define the chain that you want to evaluate as shown in below example using a RetrievalQA chain and a Vectorstore index(if applicable) to store the data based on which the QA chain works
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
llm = ChatOpenAI(temperature = 0.0)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
verbose=True,
chain_type_kwargs = {
"document_separator": "<<<<>>>>>"
}
)
It can be a regular chain for entity extraction as shown below:
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
def create_chain():
llm = ChatOpenAI(temperature=0)
return LLMChain.from_string(llm, "Given an input extract the entities in json format.
The entities to be included are First Name, Last Name, email, mobile, location and a 1-2 line summary as About the profile. The given extract is {input}.")
|Using StringEvaluator
Below sample code shows the basic implementation of the first approach using StringEvaluator from LangSmith for the entity extraction use case giving the examples as shown.
This approach can be used to define any custom logic for evaluation depending on the use case. You can read more here.
from typing import Optional
from langsmith.evaluation import StringEvaluator
def jaccard_chars(output: str, answer: str) -> float:
try:
"""Naive Jaccard similarity between two strings."""
prediction_chars = set(output.strip().lower())
answer_chars = set(answer.strip().lower())
intersection = prediction_chars.intersection(answer_chars)
union = prediction_chars.union(answer_chars)
return len(intersection) / len(union)
except:
return 1
def grader(run_input: str, run_output: str, answer: Optional[str]) -> dict:
"""Compute the score and/or label for this run."""
if answer is None:
value = "AMBIGUOUS"
score = 0.5
else:
score = jaccard_chars(run_output, answer)
value = "CORRECT" if score > 0.9 else "INCORRECT"
return dict(score=score, value=value)
# Evaluate entities
entities = {'First Name': 'Rishi', 'Last Name': 'Chauhan', 'Email ID': 'ripudmanchauhan7_ptf@indeedemail.com',
'Mobile number': '+06398888166', 'Location': 'Agra, Uttar Pradesh', 'About': 'Experienced Assistant Manager with 3 years of experience in the Accounting, Administrative Assistance, Automotive, Management, and Marketing industries. Skilled in basic computer knowledge, Microsoft Office, Tally, Accountancy, typing, and internet usage.'}
expected_values = {'First Name': 'Rishidaman', 'Last Name': 'Chauhan', 'Email ID': 'ripudmanchauhan7_ptf@indeedemail.com', 'Mobile number': '+06398888166', 'Location': 'Agra, Uttar Pradesh', 'About': 'Experienced Assistant Manager with 3 years of experience in the Accounting, Administrative Assistance, Automotive, Management, and Marketing industries. Skilled in basic computer knowledge, Microsoft Office, Tally, Accountancy, typing, and internet usage.'}
for entity, value in entities.items():
run_output = value # Set the run_output to the extracted value of the entity
answer = expected_values.get(entity) # Get the expected value for the entity
evaluation_result = grader(None, run_output, answer)
print(f"{entity}: {evaluation_result['value']} (Score: {evaluation_result['score']})")
The output will be as follows and provide a scoring of the comparison:
First Name: INCORRECT (Score: 0.5)
Last Name: CORRECT (Score: 1.0)
Email ID: CORRECT (Score: 1.0)
Mobile number: CORRECT (Score: 1.0)
Location: CORRECT (Score: 1.0)
About: CORRECT (Score: 1.0)
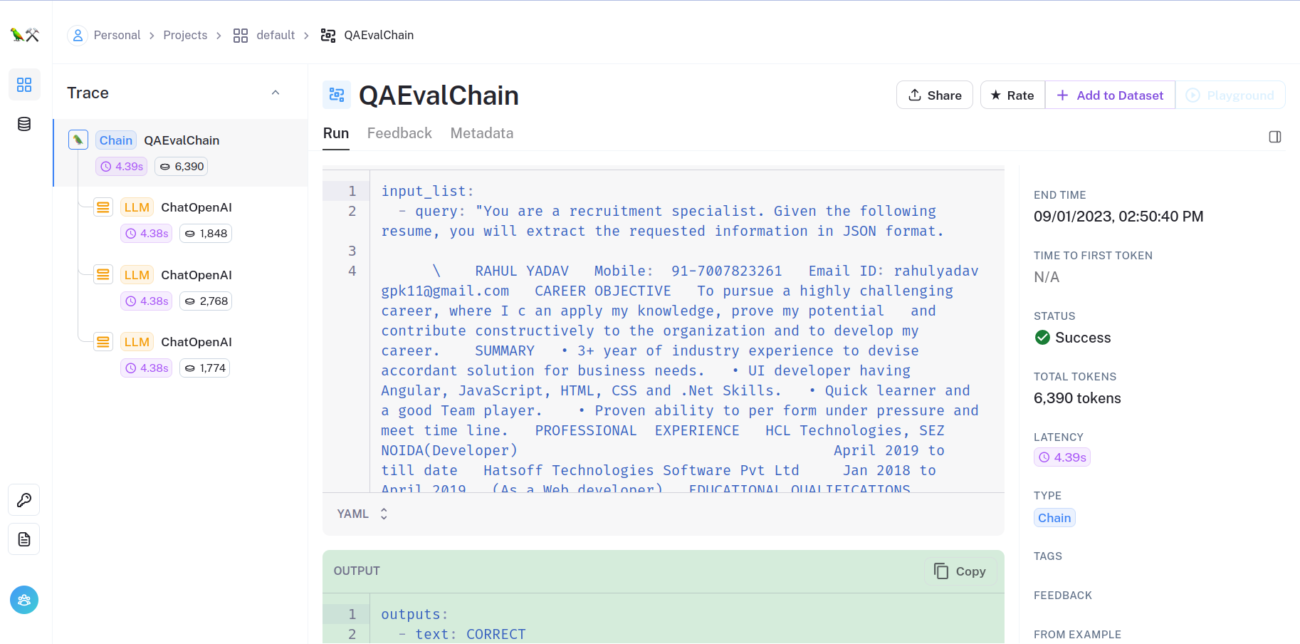
|Using QAEvalChain
This is a mechanism for LLM -assisted evaluation to compare and score your responses with the help of LLMs using a chain of type QAEvalChain as shown below:
from langchain.evaluation.qa import QAEvalChain
llm = ChatOpenAI(temperature=0)
eval_chain = QAEvalChain.from_llm(llm)
//To run the chain on the examples to get the predictions
predictions = qa.apply(examples)
graded_outputs = eval_chain.evaluate(examples, predictions)
for i, eg in enumerate(examples):
print(f"Example {i}:")
print("Question: " + predictions[i]['query'])
print("Real Answer: " , predictions[i]['answer'])
print("Predicted Answer: " + predictions[i]['result'])
print("Predicted Grade: " + graded_outputs[i]['text'])
print()
With this approach you can view the results in your langsmith console as shown below:
To Summarize the LangSmith Evaluators as below:
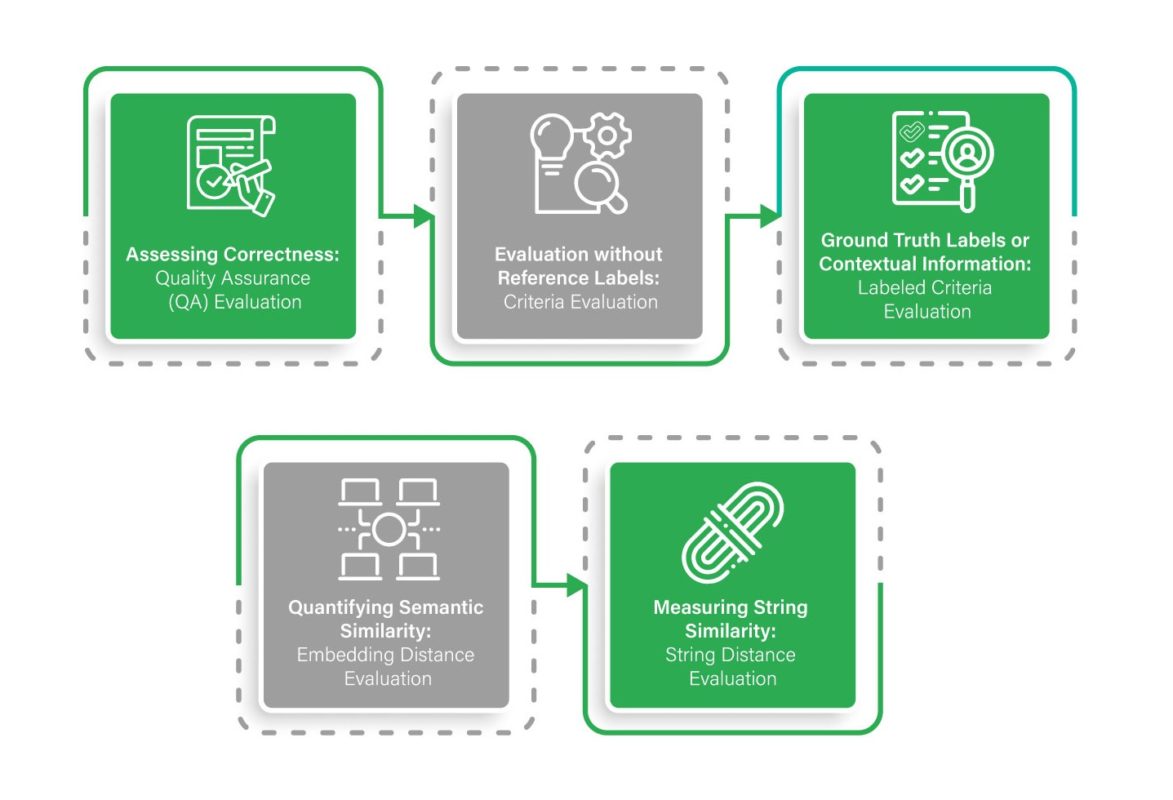
1. Assessing Correctness: Quality Assurance (QA) Evaluation
QA evaluators play a crucial role in gauging the accuracy of responses to user queries or questions. When armed with a dataset containing reference labels or context documents, these evaluators come into play. Three QA evaluators are available for utilization: “context_qa,” “qa,” and “cot_qa.”, cot_qa being the recommended one.
- The “context_qa” evaluator guides the LLM chain to factor in reference “context” (extracted from example outputs) for determining correctness when a more expansive collection of grounding documents is accessible, yet factual answers to queries are absent.
- The “qa” evaluator instructs an LLMChain to directly evaluate a response as “correct” or “incorrect” based on the reference answer.
- The “cot_qa” evaluator closely resembles the “context_qa” evaluator but introduces a “chain of thought” reasoning element before reaching a final verdict. This often leads to responses that exhibit a stronger correlation with human assessments, albeit at a slightly elevated token and runtime cost.
2. Evaluation without Reference Labels: Criteria Evaluation
For scenarios devoid of established reference labels (e.g., evaluating production data or tasks not focused on factual accuracy), the “criteria” evaluator (reference) comes into play. It allows you to assess your model’s performance against a personalized set of criteria. This proves valuable for monitoring higher-level semantic aspects not addressed by explicit checks or rules, like checking whether the response is creative enough or imaginative.
3. Ground Truth Labels or Contextual Information: Labeled Criteria Evaluation
In cases where your dataset features ground truth labels or contextual cues illustrating an output that fulfills a criterion or prediction for a specific input, the “labeled_criteria” evaluator (reference) is applicable.
4. Quantifying Semantic Similarity: Embedding Distance Evaluation
One method to quantify the semantic similarity between a predicted output and a ground truth involves embedding distance. The “embedding_distance” evaluator (reference) aids in measuring the extent of separation between the predicted output and the ground truth.
5. Measuring String Similarity: String Distance Evaluation
An alternative approach for assessing similarity entails computing a string edit distance such as Levenshtein distance. The “string_distance” evaluator (reference) serves this purpose by quantifying the distance between the predicted output and the ground truth, utilizing the rapidfuzz library.
You can read more about evaluation using LangSmith here.
Additionally, you can write your own custom logic for evaluation using StringEvaluator.
In the ever-evolving landscape of evaluating AI models, embracing diverse strategies is crucial to understanding their performance comprehensively. From QA evaluators ensuring precision in responses to criteria-based assessments offering a broader context, and embedding and string distance analyses quantifying semantic and textual resemblances, each approach contributes to a more holistic evaluation process. By adopting a multi-faceted approach tailored to specific needs, developers and researchers can unravel the strengths and weaknesses of their models, fostering continuous improvement and innovation in the world of AI applications. As the AI field continues to advance, the spectrum of evaluation methods will undoubtedly expand, allowing us to refine our models’ capabilities and unlock new horizons.