Blogs
Ensuring Reliability and Trust: Strategies to Prevent Hallucinations in Large Language Models

 Step into the captivating realm of Large Language Models (LLMs) and embark on an exhilarating journey through the fascinating landscape of preventing hallucinations. Just like the human mind can sometimes conjure up vivid illusions, LLMs, with their immense language generation capabilities, may occasionally produce hallucinatory outputs that appear plausible but are far from reality. This comes out as the biggest area of concern for enterprises to include these models into their production environments.
Step into the captivating realm of Large Language Models (LLMs) and embark on an exhilarating journey through the fascinating landscape of preventing hallucinations. Just like the human mind can sometimes conjure up vivid illusions, LLMs, with their immense language generation capabilities, may occasionally produce hallucinatory outputs that appear plausible but are far from reality. This comes out as the biggest area of concern for enterprises to include these models into their production environments.
In this blog, we equip you with a treasure trove of strategies, techniques, and cutting-edge approaches to tame the hallucinatory tendencies of LLMs, especially the pre-trained models like ChatGPT, GPT4 and be able to power your enterprise applications with the great possibilities they bring.
Models can exhibit hallucinations due to several factors. One reason is the inherent complexity of language and the vast amount of diverse information available. Models may encounter ambiguous or incomplete data, leading to the generation of inaccurate or nonsensical outputs. Additionally, the training process involves learning patterns and relationships from vast datasets, which can result in models extrapolating or generalizing beyond what is intended. The limitations of training data and the biases inherent in the data can also contribute to hallucinations. Furthermore, the fine balance between creativity and accuracy in language generation can sometimes tilt towards generating imaginative but incorrect responses. These factors contribute to the phenomenon of hallucination in language models, highlighting the need for careful handling and mitigation strategies when deploying them in real-world applications.
This can be controlled and tamed to be able to utilize the immense potential of Large Language Models like ChatGPT.
Let’s look at how we can power our enterprise-grade applications with LLMs with utmost trust and without any fear of misrepresentation and twisted facts.
| Contextual Prompt Engineering
Carefully craft and design prompts to guide the model’s generation process. Use explicit instructions, contextual cues, or specific framing techniques to narrow down the range of possible outputs and minimize hallucinations. Experiment with different prompts to find the ones that yield the most reliable and coherent responses.
Introduce constraints that enforce consistency and adherence to factual information within the generated text. For example, you can utilize external knowledge sources or fact-checking mechanisms to validate the generated content and filter out potential hallucinations.
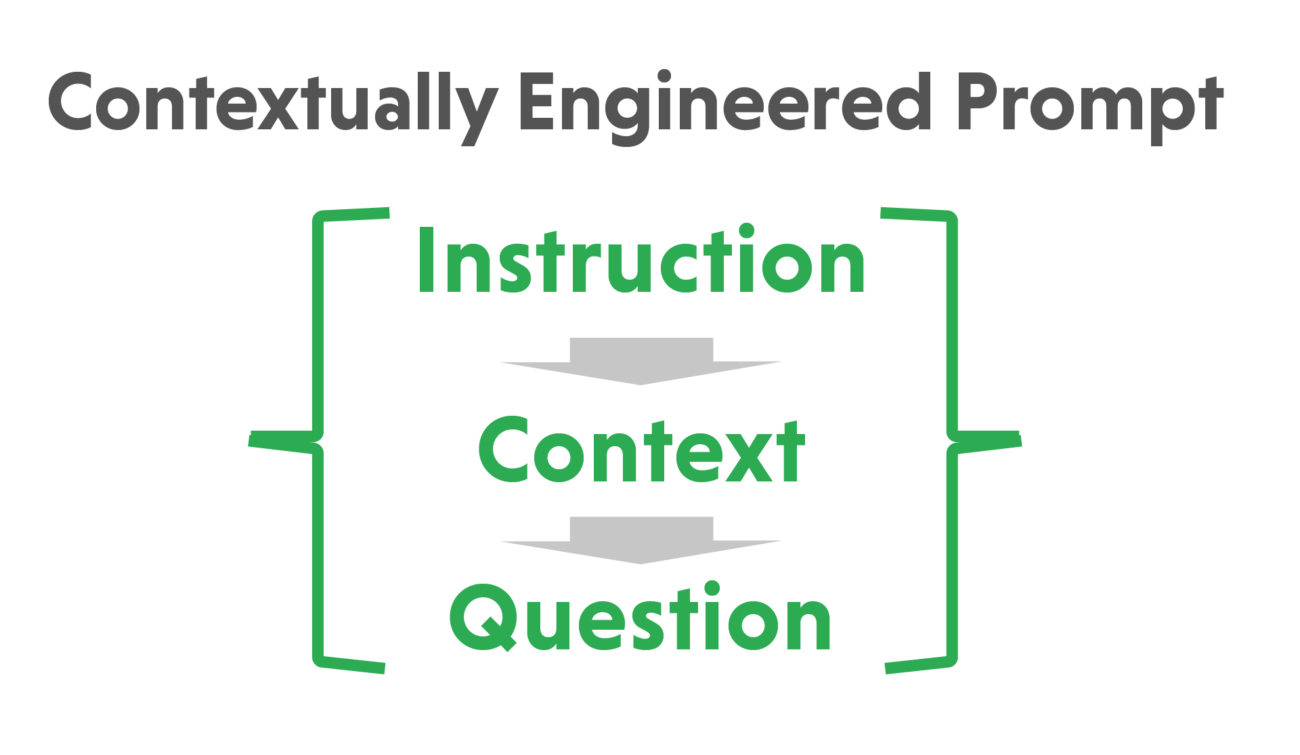
For example,
- Giving references to the format in which you are expecting the output by giving a sample output.
- Giving instructions to answer truthfully with the knowledge available only to prevent misstating facts.
- Giving references to the required schema with instructions on table relationships to be used if you are using the LLM to generate queries.
etc.
| Domain Adaptation and Augmentation
Domain-specific knowledge can be provided by augmenting the knowledge base of the LLM. As the token size is limited and also charged for usage, you would want to be able to send relevant domain knowledge to be used to answer queries and generate relevant responses.
The LLM provides answers to user queries based not only on the knowledge captured in the dataset the LLM was trained on, but augmented with knowledge coming from searching additional data sources which could comprise of Domain specific documentation, Data from internet websites, Data maintained in relational and graph databases, vector stores etc.
This is enabled using technologies like Llama-Index and LangChain which enable to connect to different data sources, search and send the relevant information to the LLM to be used to generate the responses.
Another approach is Fine-tuning the pre-trained model on domain-specific data to align it with the target domain and reduce hallucinations. By exposing the model to domain-specific patterns and examples, it can learn to generate more accurate and contextually appropriate responses.
Fine-tuning LLMs with domain-specific data can further improve their performance and reduce hallucination tendencies. By training the model on task-specific datasets and fine-tuning it to suit the desired application, we can further enhance the model’s understanding of context and generate more reliable outputs.
| Feedback, Monitoring, and Improvement mechanism
Having a well-defined evaluation and feedback mechanism will ensure the model response is controlled and all possible hallucinations are filtered out before it goes into production with a real user.
Below are some factors which should be considered to ensure an effective monitoring and improvement system.
Active Learning and Feedback Loop: Engage in an active learning process where the prompt or the tuning dataset is continually refined based on user feedback and interactions. Collect feedback from users to identify instances of hallucinations and incorporate corrective measures into the model prompt engineering and fine-tuning pipeline, as applicable for pre-trained models.
Bias Mitigation: Address biases in the pre-trained model by actively detecting and reducing biased responses. Implement debiasing techniques to ensure fair and equitable outputs, minimizing the risk of hallucinations caused by biased training data or skewed language patterns.
Adversarial Testing: Conduct rigorous adversarial testing to identify vulnerabilities and potential sources of hallucinations. By exposing the model to carefully designed adversarial examples, weaknesses, and potential hallucination triggers can be discovered and mitigated.
Human-in-the-Loop Validation: Incorporating human validation and review processes is crucial in preventing LLM hallucinations. By involving human experts to assess and verify the generated outputs, we can catch and correct any inaccuracies or distortions, ensuring the reliability and trustworthiness of the model’s responses.
Post-Processing Techniques: Applying post-processing methods to LLM outputs can help refine and filter the generated content. Techniques such as filtering based on relevance, fact-checking, or sentiment analysis can aid in removing or flagging potentially hallucinatory information, improving the overall quality of the generated outputs.
Ethical Considerations: It is essential to take into account the ethical implications of LLM outputs. Building awareness and sensitivity towards potential biases, misinformation, or harmful content generated by LLMs is crucial in preventing unintended consequences and ensuring responsible use.
Continuous Monitoring and Updates: The field of LLM research is ever-evolving, with ongoing advancements and updates. It is essential to stay up-to-date with the latest developments, techniques, and best practices to continually improve the reliability and accuracy of LLM outputs and adapt to emerging challenges.
| Structured Control with GuardRails
Guardrails is an innovative Python package designed to enhance the reliability and quality of outputs generated by large language models (LLMs). With Guardrails, users can introduce robustness and integrity to LLM outputs by implementing a range of valuable functionalities.
Key features of Guardrails include:
- Its ability to perform comprehensive validation on LLM outputs, akin to the popular pydantic library. This validation includes semantic checks that detect potential issues such as bias in generated text or bugs in generated code. By ensuring that outputs meet specified criteria, Guardrails helps maintain the desired level of quality and accuracy.
- If validation fails, Guardrails takes corrective actions to address the issues. For instance, it can trigger the LLM to generate new outputs or perform additional processing steps to rectify the problem. This ensures that the final outputs meet the desired standards and align with the intended purpose.
- It also enforces structure and type guarantees on the outputs, such as adhering to a JSON format. This consistency and adherence to predefined specifications contribute to the overall reliability of the LLM outputs.
To facilitate the implementation of these features, Guardrails introduces a file format called “.rail” (Reliable AI markup Language). This format allows users to define the desired structure, type information, validators, and corrective actions for LLM outputs. By leveraging rail files, users can easily specify the requirements and constraints for the LLM outputs, tailoring them to their specific use cases.
![]()
Additionally, Guardrails provides a lightweight wrapper around LLM API calls, streamlining the integration of the specified requirements and ensuring the desired functionality is applied to the outputs.
In summary, Guardrails is a powerful tool that empowers users to introduce structure, validation, and corrective actions to LLM outputs. By leveraging rail files and the comprehensive features offered by Guardrails, users can enhance the reliability, quality, and integrity of their LLM-based applications and workflows.
With all these approaches in action, get ready to witness the awe-inspiring power of language models while preserving the integrity and truthfulness of their generated content and unleashing their true potential by using them in your applications.