


Blogs
Transforming Unstructured Data into Actionable Knowledge Graphs for Enterprises
In today’s data-driven world, organizations grapple with the monumental task of turning unstructured information into actionable insights. Vast repositories of data hold immense potential, yet extracting meaningful patterns often feels like searching for a needle in a haystack. Traditional approaches to building Knowledge Graphs (KGs), a key tool for structuring and connecting data, are fraught with limitations. They lean heavily on rigid, predefined ontologies, demand labor-intensive supervised learning processes, and lack the flexibility to adapt across diverse use cases. As a result, many enterprises find themselves unable to fully unlock the transformative power of their data assets.
The advent of Large Language Models (LLMs) has changed the game. These models have opened up exciting possibilities for structuring and analyzing data, paving the way for innovative applications. A particularly promising approach is the use of Retrieval-Augmented Generation (RAG) to integrate enterprise-specific data into LLMs. By providing contextual grounding, RAG enables models to perform enterprise-specific tasks, such as powering intelligent chatbots or acting as virtual data analysts.
However, taking such solutions from concept to production presents its own set of challenges. Reliability and predictability are paramount, and this is where the synergy between RAG and Knowledge Graphs proves invaluable. While RAG leverages the dynamic capabilities of LLMs, Knowledge Graphs bring in the precision, structure, and control needed to ensure data integrity. Together, they offer a robust framework for building powerful, context-aware enterprise applications.
Despite this potential, converting large volumes of unstructured data into accurate Knowledge Graphs is no small feat. The process demands meticulous attention to detail to ensure that the generated graphs are reliable and accurate. Human review becomes an essential step in this journey, as it bridges the gap between automated processes and the trustworthiness of the final solution. Only through rigorous oversight can organizations confidently deploy solutions that balance the creative potential of LLMs with the data accuracy required for critical decision-making.
By combining the best of RAG and Knowledge Graphs, enterprises can build scalable, reliable, and innovative solutions. These technologies, when thoughtfully implemented, empower organizations to not just navigate but thrive in the ever-expanding ocean of data.
In the process of designing reliable and intelligent autonomous agents for our customers, we have explored multiple approaches to achieve the required accuracy of the system.
iText2KG, an impactful zero-shot approach for constructing Knowledge Graphs is one such approach which holds promise and sidesteps the limitations. By leveraging the power of large language models (LLMs), iText2KG enables organizations to incrementally transform raw, unstructured data into cohesive and semantically rich KGs. Its plug-and-play design, enhanced by a customizable blueprint schema, makes it an adaptable solution for varied business needs—from organizing scientific insights to structuring customer information or even parsing web content into actionable intelligence.
This blog explores how iText2KG empowers enterprises to move beyond data silos, streamlining decision-making, and fostering innovation in knowledge management. Discover the potential of this transformative tool and how it bridges the gap between raw data and intelligent business solutions.
The paper introduces iText2KG, a zero-shot, topic-independent method for incremental knowledge graph (KG) construction using large language models (LLMs).
|The main points covered by this approach include:
1. Challenges in Traditional KG Construction:
‣ Dependency on predefined ontologies and supervised learning methods.
‣ Issues with unresolved and duplicate entities and relations, requiring extensive post-processing.
‣ Topic-dependence of current methods limits their general applicability.
2. Proposed Approach (iText2KG):
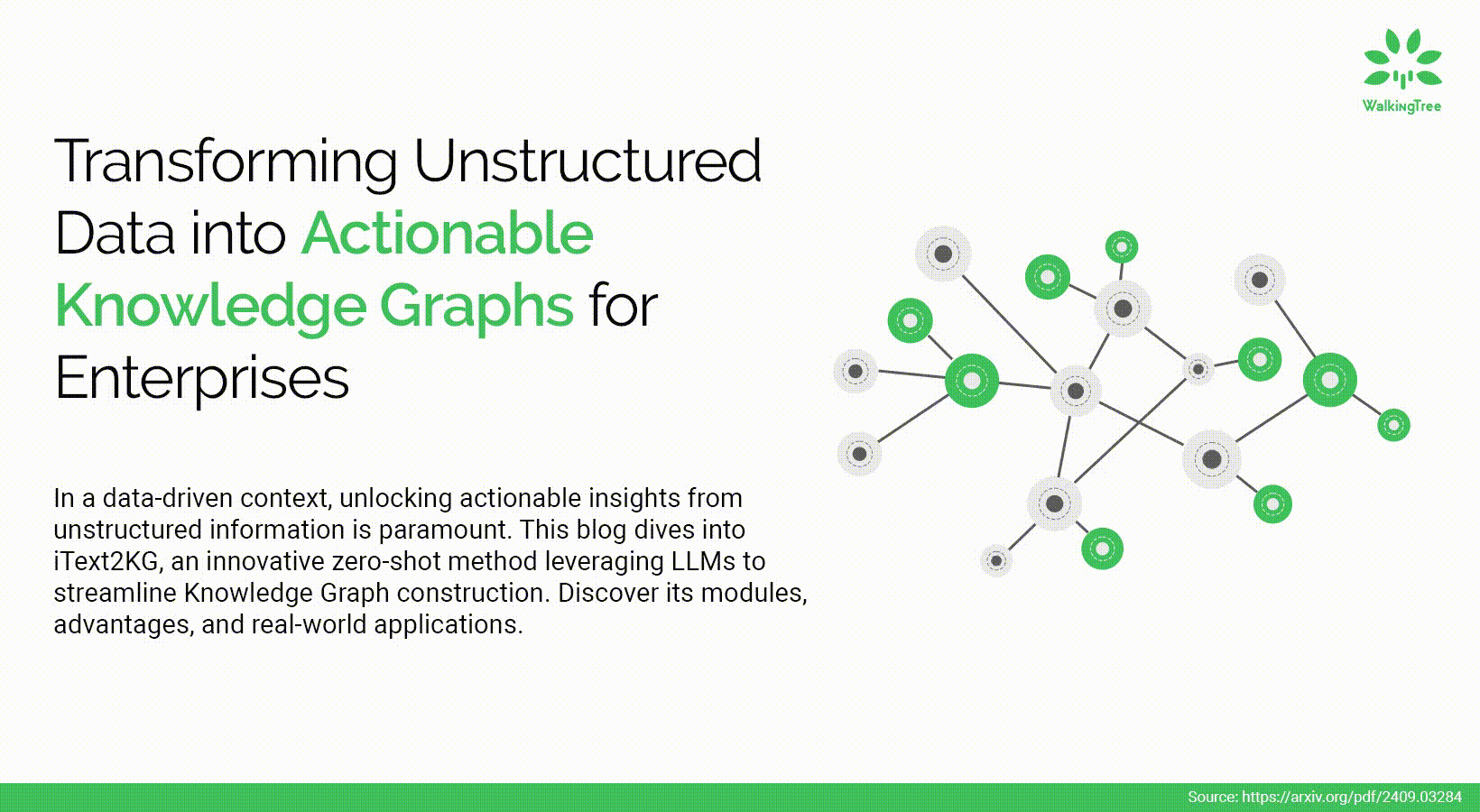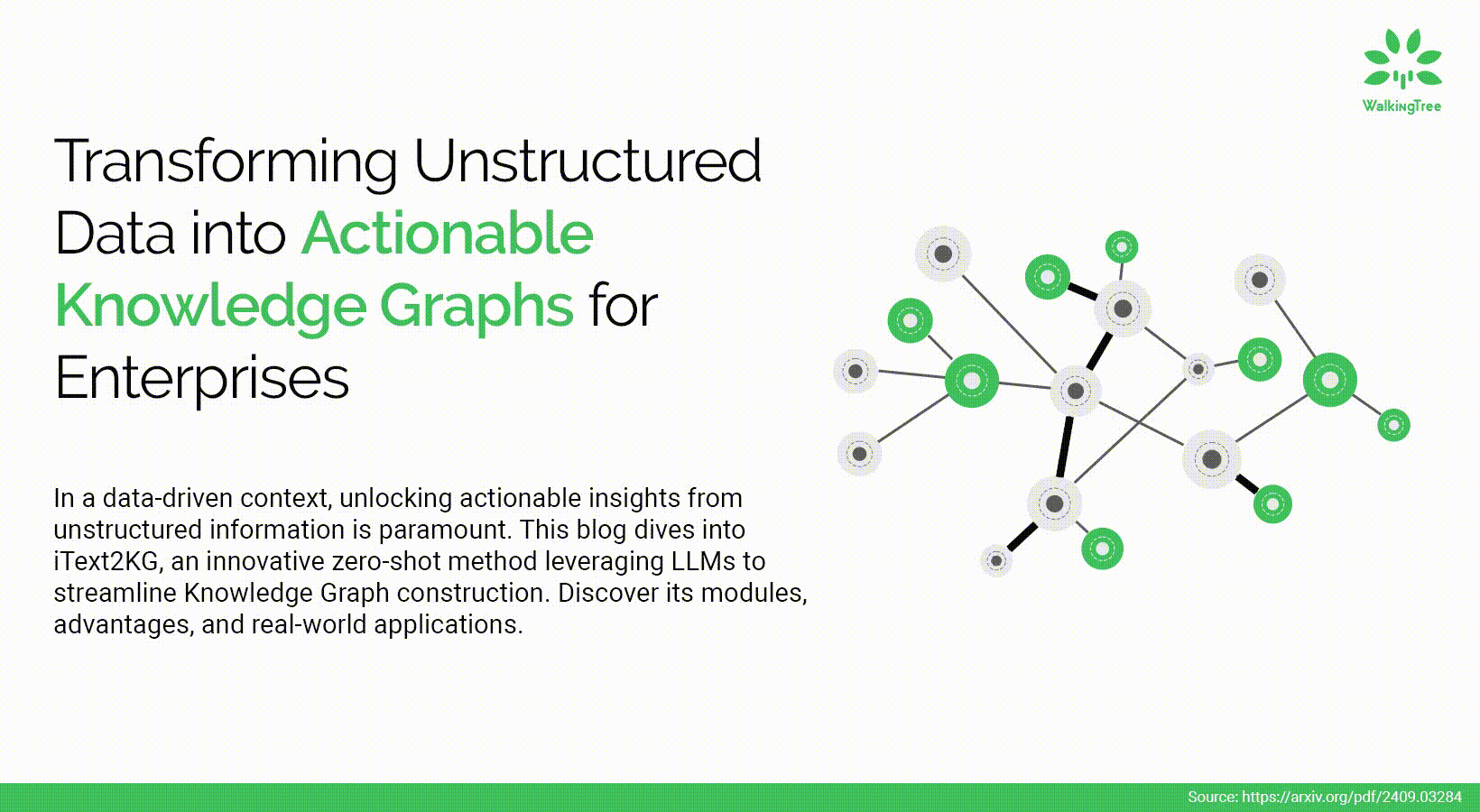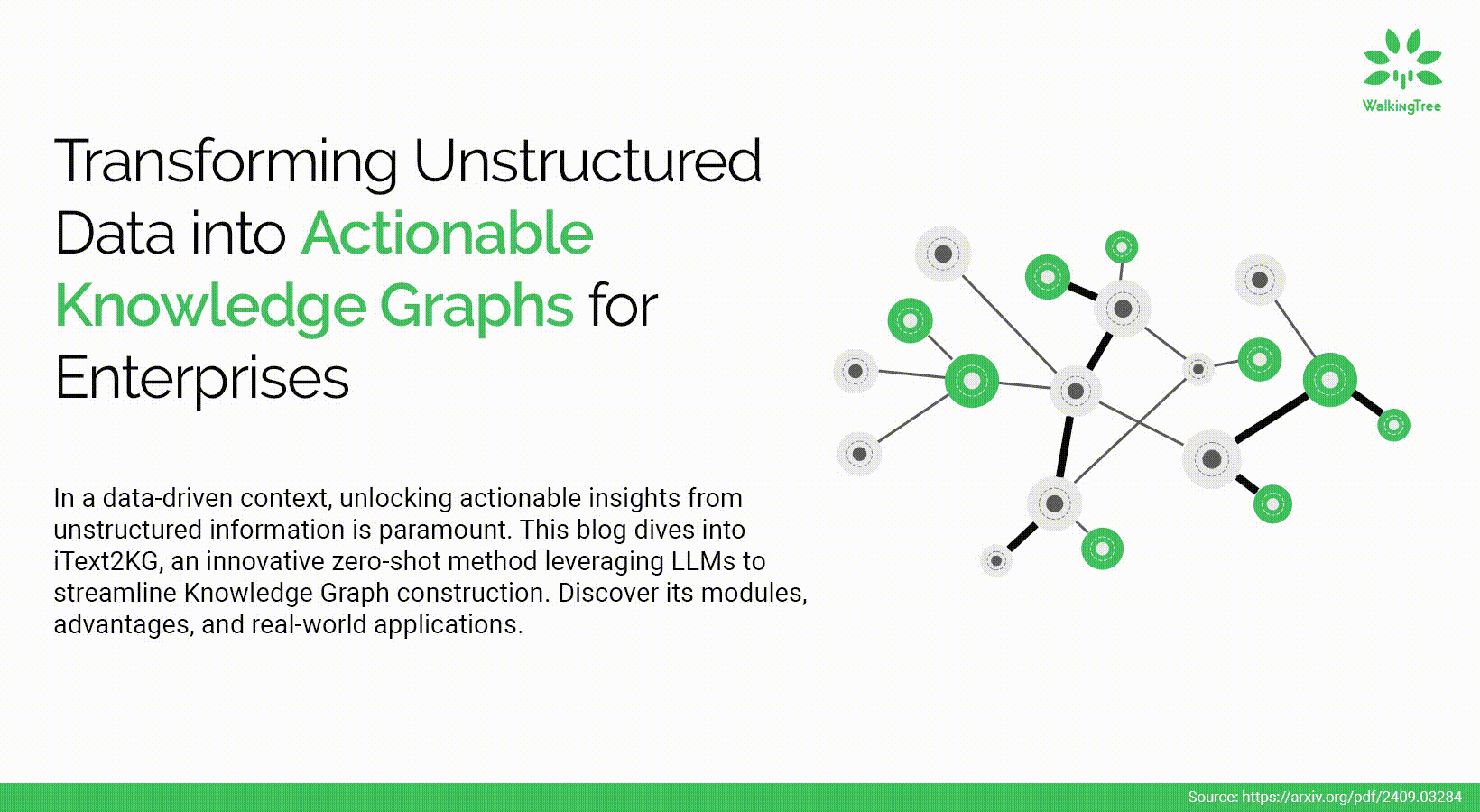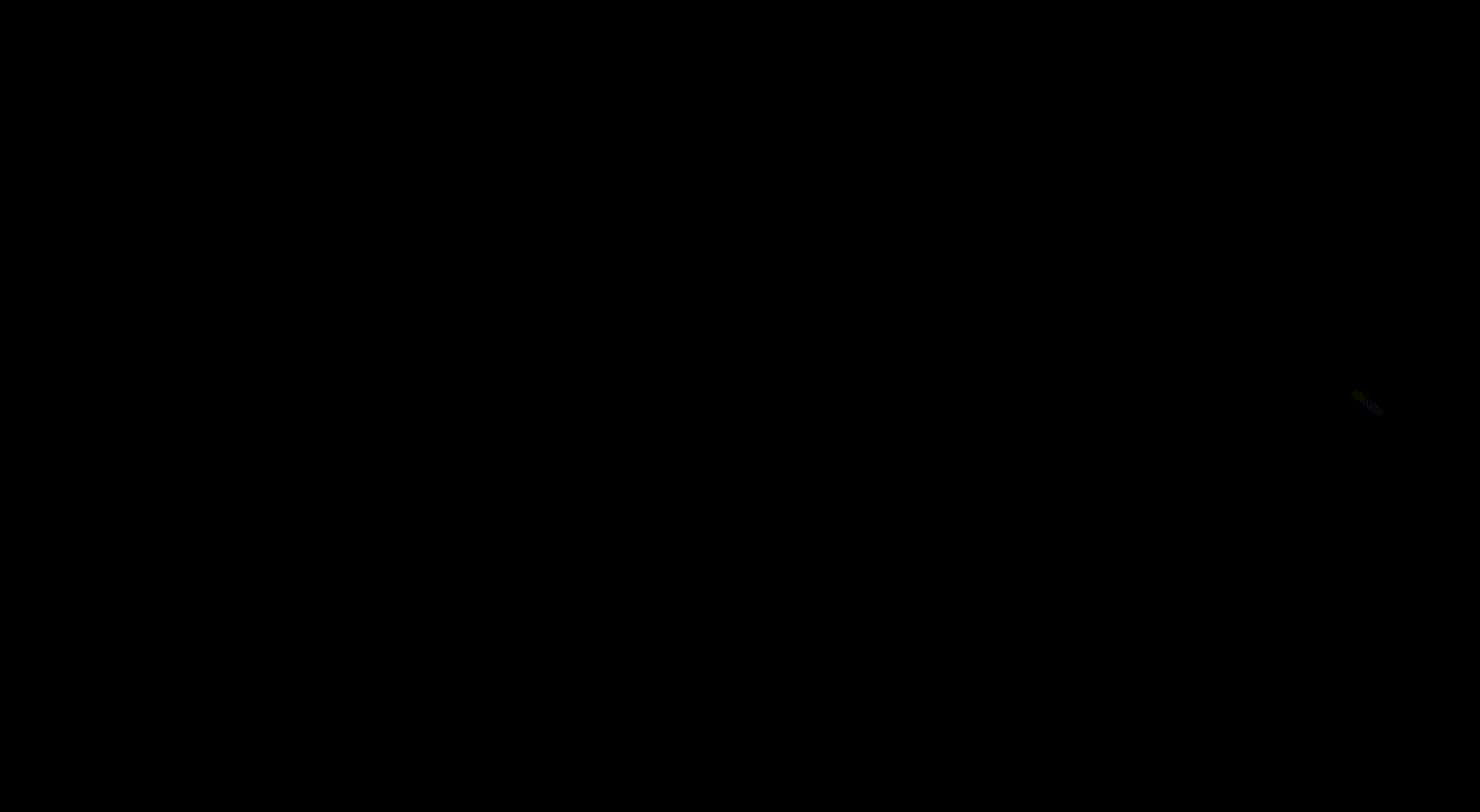
▸Comprises four modules:
• Document Distiller: Reformulates input documents into structured semantic blocks using a flexible blueprint schema.
• Incremental Entity Extractor: Extracts and resolves unique entities while ensuring semantic clarity.
• Incremental Relation Extractor: Identifies relationships between entities with options for local or global context-based processing.
• Graph Integrator: Visualizes the resulting graph using Neo4j.
▸The approach eliminates the need for post-processing and operates in a zero-shot manner.
3. Advantages of iText2KG:
▸ Achieves high schema and information consistency across different document types (scientific articles, CVs, and websites).
▸ Separates entity and relation extraction processes to enhance precision and reduce semantic redundancies.
▸ Adapts to a variety of scenarios due to its blueprint-based design.
4. Performance and Evaluation:
▸ Demonstrates superior performance over baseline methods like OpenAI Function, Langchain, and LlamaIndex in metrics like entity/relation resolution and schema consistency.
▸ Effective in handling both structured and unstructured text data.
5. Future Directions:
▸ Enhance entity/relation matching by refining cosine similarity metrics.
▸ Develop an automated threshold-setting mechanism and integrate entity types as parameters.
Now that we understand the overall approach, let’s set this up and see it in action with an example. For the sake of example, we will take the SEC filing document of Amazon and use the same to extract some key attributes and build a knowledge graph.
|1. Extracting and Preparing Data
The first step in building a Knowledge Graph is to extract information from unstructured documents. In this example, we use a company’s SEC filing and try to extract the key attributes from the SEC document and create a knowledge graph.
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
openai_llm_model = ChatOpenAI(api_key=openai_api_key, model="gpt-4o-mini", temperature=0)
openai_embeddings_model = OpenAIEmbeddings(api_key=openai_api_key, model="text-embedding-3-small")
loader = PyPDFLoader("./Amazon_sec.pdf")
pages = loader.load_and_split()
Here, we load a PDF document and split it into pages for easier processing. These pages form the raw material for the subsequent steps.
|2. Distilling Information with a Flexible Blueprint
from itext2kg.documents_distiller import DocumentsDistiller
from pydantic import BaseModel, Field
from typing import List, Optional
class Executive(BaseModel):
name: str = Field(..., description="Name of the executive")
title: str = Field(..., description="Title of the executive in the company")
compensation: Optional[str] = Field(None, description="Compensation details for the executive")
class FinancialMetric(BaseModel):
metric_name: str = Field(..., description="Name of the financial metric (e.g., revenue, net profit)")
value: str = Field(..., description="Value of the financial metric")
year: Optional[int] = Field(None, description="Year for the metric")
class BusinessSegment(BaseModel):
segment_name: str = Field(..., description="Name of the business segment")
contribution: Optional[str] = Field(None, description="Contribution of the segment to the company's revenue or profits")
class RiskFactor(BaseModel):
description: str = Field(..., description="Description of a specific risk factor affecting the company")
class Litigation(BaseModel):
case_name: Optional[str] = Field(None, description="Name of the litigation case")
details: str = Field(..., description="Details about the litigation or legal proceeding")
class SECFilingContent(BaseModel):
company_name: str = Field(..., description="Name of the company")
fiscal_year: Optional[int] = Field(None, description="Fiscal year of the SEC filing")
business_overview: str = Field(..., description="Summary of the company's business and operations")
executives: List[Executive] = Field(..., description="List of executives and their roles in the company")
financial_metrics: List[FinancialMetric] = Field(..., description="Key financial metrics from the filing")
business_segments: List[BusinessSegment] = Field(..., description="Details of the company's business segments")
risk_factors: List[RiskFactor] = Field(..., description="List of risk factors affecting the company")
litigations: Optional[List[Litigation]] = Field(None, description="Details of ongoing or past litigations")
competitive_landscape: Optional[str] = Field(None, description="Overview of the company's competition")
recent_developments: Optional[str] = Field(None, description="Recent developments or news from the filing")
future_outlook: Optional[str] = Field(None, description="Company's outlook for the future as per the filing")
document_distiller = DocumentsDistiller(llm_model=openai_llm_model)
IE_query = """
# DIRECTIVES :
- Act like an experienced company researcher who understands any kind of company reports, SEC filings and other statements.
- You have an SEC quarterly report.
- If you do not find the right information, keep its place empty.
"""
distilled_sec = document_distiller.distill(
documents=[page.page_content for page in pages],
IE_query=IE_query,
output_data_structure=SECFilingContent
)
semantic_blocks_sec = [
f"{key} - {value}"
for key, value in distilled_sec.items()
if value not in ([], "", None)
]
The blueprint schema, defined as SECFilingContent, specifies the key entities and relations to extract (e.g., executives, financial metrics). The output is semantic blocks containing distilled and relevant information.

The blueprint mentioned in the paper refers to a flexible, user-defined schema that guides the transformation of raw documents into structured semantic blocks during the Document Distiller module of the iText2KG approach.
Key Characteristics of the Blueprint:
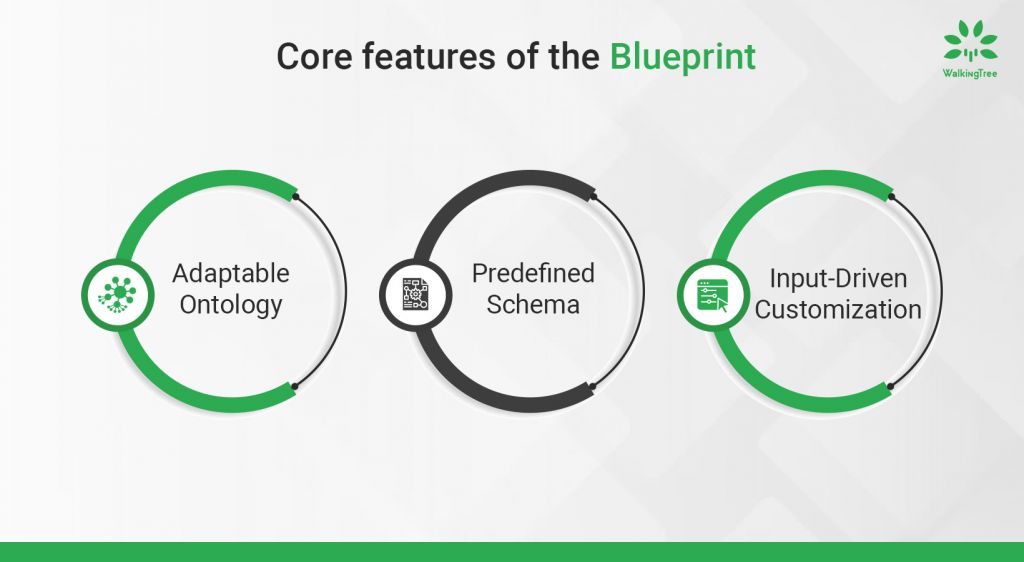
● Adaptable Ontology:
▸ Unlike traditional ontologies, which are rigid and domain-specific, the blueprint is more adaptable and general-purpose.
▸ It acts as a structured guide but doesn’t impose strict limitations.
● Predefined Schema:
▸ Functions like a JSON structure with specific keys that direct the LLM to extract and organize relevant information.
▸ Allows the user to specify what components are critical for their use case (e.g., title, authors, and relations for a scientific article).
● Input-Driven Customization:
▸ Designed to align with the user’s goals, enabling the method to adapt to different document types (e.g., CVs, websites, or research papers).
▸ Helps increase the signal-to-noise ratio by focusing on extracting relevant and structured data.
Benefits:
▸ Enhances flexibility across various Knowledge Graph (KG) construction scenarios.
▸ Reduces noise and redundant information in the extracted data.
▸ Supports domain independence, making the iText2KG approach applicable to diverse industries and applications.
In essence, the blueprint serves as a guiding template that helps streamline the process of extracting and organizing unstructured data, enabling the construction of consistent and meaningful Knowledge Graphs.
|3. Building the Knowledge Graph
With the distilled information ready, the next step is to incrementally construct a KG using iText2KG.
from itext2kg import iText2KG
itext2kg = iText2KG(
llm_model=openai_llm_model,
embeddings_model=openai_embeddings_model
)
kg = itext2kg.build_graph(
sections=[semantic_blocks_sec],
ent_threshold=0.6,
rel_threshold=0.6
)
This step uses thresholds to resolve duplicate entities and relationships, ensuring the graph’s semantic clarity and uniqueness.
|4. Visualizing the Graph
To make the data actionable, the KG is visualized using a Neo4j database. If you are using Neo4j for the first time, you can go to https://neo4j.com/ and sign up for a free account and create a free AuraDB instance and use the URL and Key given as you set up and open the instance.
from itext2kg.graph_integration import GraphIntegrator URI = "neo4j+s://xxxxx.databases.neo4j.io" USERNAME = "neo4j" PASSWORD = "xxxxxx" GraphIntegrator(uri=URI, username=USERNAME, password=PASSWORD).visualize_graph(knowledge_graph=kg)
Neo4j provides an intuitive interface to explore the graph, enabling deeper insights into the structured data.
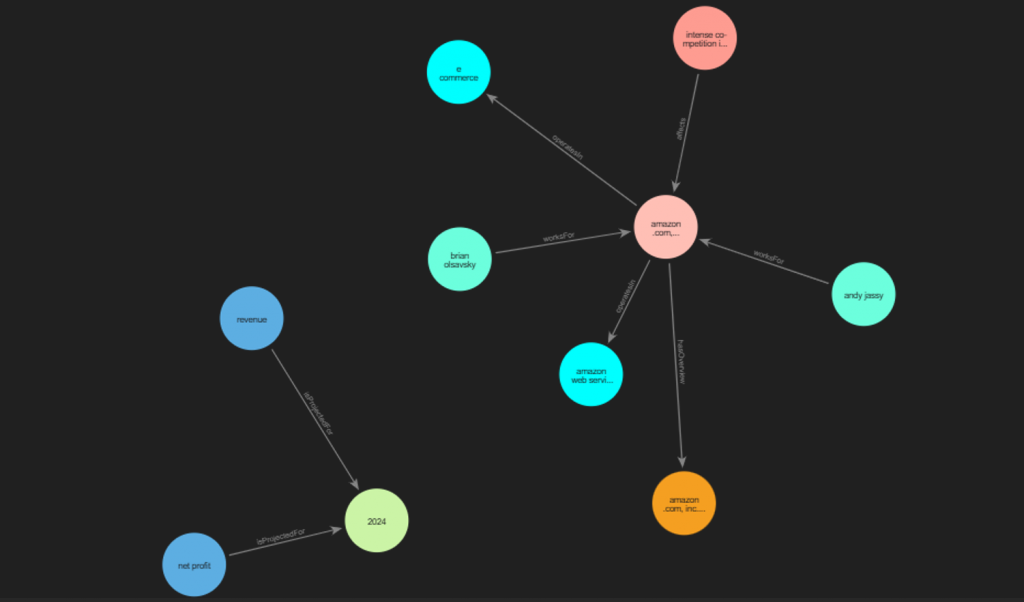
|5. Querying the Knowledge Graph
Finally, to retrieve insights from the KG, we use Cypher queries integrated with a language model using the langchain chain GraphCypherQAChain which provides this capability directly taking the text query as input, matching the relevant nodes using cypher and then finally using the extracted data to formulate a proper response by providing the context from the extracted graph data.
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
graph = Neo4jGraph(uri=URI, username=USERNAME, password=PASSWORD)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke("Who are the key executives for the business?")
print(result)

This query system combines the KG’s structured nature with the interpretive power of LLMs to answer complex business questions.
This step can be further broken down into sub steps to have greater control and improved accuracy over the flow and bring in other elements of check and validation, for example using neighbouring nodes for improved answer accuracy, checking relevancy score for the derived nodes and rerank based on greater relevancy, etc.
By applying a combination of different approaches, we arrive at a more structured representation of the data and also ensure we are able to extract the most relevant information to be provided as context in RAG to get an accurate answer from the model.
|Conclusion
By automating the process of converting raw, unstructured data into a rich and navigable Knowledge Graph, iText2KG bridges the gap between data and actionable insights. Enterprises can leverage this approach for applications like risk assessment, financial analysis, and strategic planning—uncovering relationships and insights hidden in plain sight. The flexible blueprint and zero-shot methodology ensure adaptability across industries, making iText2KG a valuable tool in today’s data-driven world.
At WalkingTree Technologies, we pride ourselves on pioneering digital transformation. Our expertise in advanced analytics, AI-driven applications, and agile execution empowers businesses to extract meaningful insights and foster growth. Partner with us to turn your complex data challenges into opportunities for success. Visit WalkingTree Technologies to learn more.











