Blogs
Talking to Your Data: Unleashing the Power of Text-to-Query for Insightful Interactions with Your Databases

Imagine being able to ask your company’s data questions just like you would ask a colleague. Need last quarter’s sales figures? Simply ask. Want to analyze trends in customer feedback? Just phrase it as a question. This concept of “talking to your data” has gained significant traction, transforming how we interact with vast information repositories. The magic behind this interaction lies in Large Language Models (LLMs), which translate natural language queries into structured database queries, delivering precise, actionable insights in seconds.
While modern LLMs like GPT-4 and ChatGPT have propelled this functionality to new heights, text-to-query isn’t entirely new. In fact, one popular early adopter of this technology is ESPN’s AskCricInfo platform, which lets cricket enthusiasts ask questions about game stats and records in simple language. Now, as enterprises adopt similar technology and want to be able to extract more value out of their data at the tip of their tongue, employees across industries can access complex data insights by phrasing natural language questions. With this, organizations are finding ways to make data easily accessible, leading to faster, data-driven decision-making.
In this blog, we’ll explore how you can implement a structured, reliable system of agents to make your data accessible via natural language. We’ll discuss each step, from setting up secure connections to your databases to building a predictable structure that will make interacting with data as easy as having a conversation.
In a large enterprise environment, data is often siloed across departments, making it challenging to access and analyze effectively. Imagine a company with a complex data ecosystem where sales data is only one component of a vast network of interconnected information. Other critical areas include inventory, customer feedback, supply chain metrics, marketing performance, and financial reporting. For such an organization, a robust text-to-query system can provide transformative capabilities—empowering users to quickly access insights across these diverse data points.
|The Challenge: Complex Data Schema and Multi-Aspect Querying
In this example, the company’s data schema is intricate, with each department holding detailed records that need to be mapped out and queried accurately. For instance:
- Sales Data: Includes fields like product name, region, sales figures, and customer details.
- Inventory Data: Tracks product availability, restocking dates, warehouse locations, and SKU details.
- Customer Feedback: Contains review scores, comments, timestamps, and product references.
- Supply Chain Metrics: Includes shipment dates, delivery status, supplier ratings, and cost details.
- Marketing Performance: Holds campaign names, target audience segments, conversion rates, and ad spend.
- Financial Reporting: Covers income statements, cash flow, balance sheets, and projections.
Given this complexity, any effective text-to-query solution must do more than simply parse a question—it must understand the underlying schema, identify the specific data aspects being referenced, and construct queries that fetch relevant information from multiple interconnected datasets.
Additionally, when designing AI-powered applications that interact with databases, especially through autonomous queries, it’s essential to protect data integrity and confidentiality from potential injection attacks. To ensure that automated queries don’t inadvertently expose or compromise sensitive data, a robust security design is critical. This includes:
- Permission Hardening: Assign specific roles and permissions to restrict access to sensitive tables and limit SQL commands that can be executed. For example, permissions can be defined to control access based on the user’s role and the sensitivity of the data, preventing unauthorized queries or modifications.
- Query Rewriting: This approach uses nested SQL queries or views based on user permissions, ensuring that only the necessary data is accessed. By rewriting queries dynamically according to permissions, even user-generated queries can be restricted to prevent unauthorized data exposure.
The referenced paper underscores the importance of incorporating these security practices to mitigate risks such as prompt-to-SQL (P2SQL) injections, which can lead to significant data breaches if not properly managed.
|Building a Text-to-Query System for Complex Data
To address the enterprise’s needs, we employ an agent-driven architecture that leverages LLMs to accurately parse, interpret, and construct queries that handle multiple data aspects. This approach enables users from different departments to interact with the data seamlessly, without needing to understand the technical intricacies of database management. Below is a step-by-step breakdown of how each part of the system handles complex data requests.
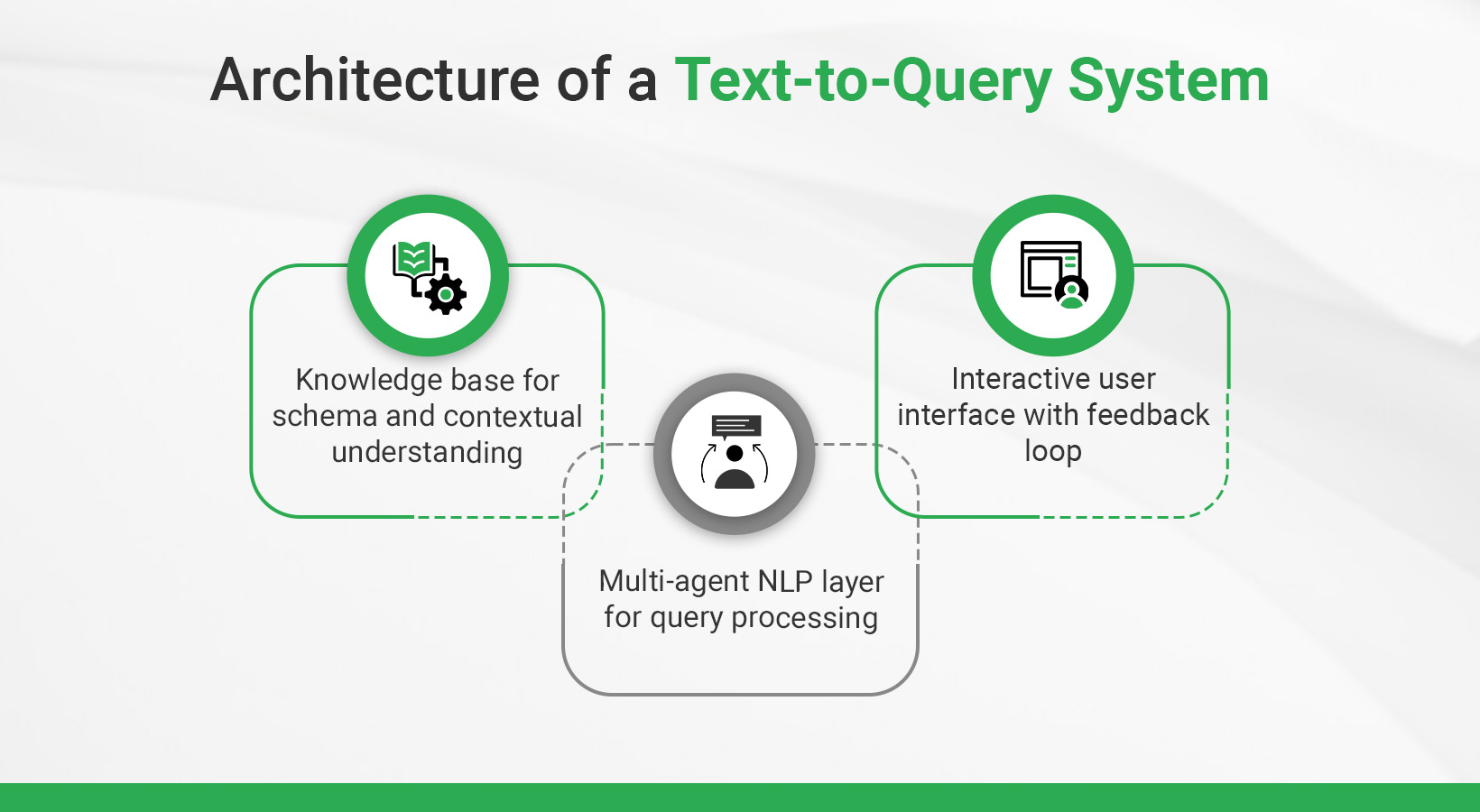
1. Knowledge Base for Schema and Contextual Understanding
The cornerstone of this system is a well-defined knowledge base that serves as a comprehensive map of the organization’s data schema. This data can be a single Relational Database or across multiple types of databases, structured and unstructured, nosql, graph etc. but the same approach can be applied and modified as per the data in consideration.
- Defining the Schema: For each data entity (e.g., sales, inventory, feedback), we catalog relevant fields, data types, and relationships. For example, sales records may link to inventory data by SKU, while customer feedback may relate to both product and sales data by product ID. This map enables the system to identify relationships across different departments.
- Contextual Examples for Each Aspect: To improve query accuracy, we build a set of predefined examples with solutions for each data category stored in the vector store along with the metadata schema definition. These queries serve as models that guide the LLM in understanding common questions. For instance:
▸ Sales: “Show sales for Q1 by product category.”
▸ Inventory: “List items below reorder level by warehouse.”
▸ Feedback: “Summarize customer feedback for product X in the last quarter.”
▸ Financials: “Get net income for the last fiscal year.”
This structured knowledge base is critical for creating the context packages used in query generation, ensuring that the system accurately interprets user input across data types. This metadata minimizes the ambiguity in the natural language query and makes the context more specific and reliable.
2. Multi-Agent NLP Layer for Query Processing
The system’s NLP layer is designed with specialized agents to handle the nuances of complex, multi-aspect queries.
2.1 Context Detection Agent
This agent interprets the user’s input and identifies the specific data categories and relationships involved in the query. For instance, if a user asks, “Show all sales transactions above $50,000 with products that have low inventory levels,” the agent recognizes the two key components (sales and inventory) and identifies “sales transactions,” “amount,” “product name,” and “inventory level” as relevant fields.
- Natural Language Parsing: The agent breaks down the query into specific attributes and conditions.
- Knowledge Store Interface: It accesses the schema map, identifying relevant entities (sales and inventory) and any predefined relationships, such as the SKU linking sales to inventory data. It also includes query examples picked from the vector store using a combination of metadata search and similarity search to find relevant query which can provide specific context and behavior to replicate.
- Context Package Creation: The agent then bundles these details into a context package that guides the query generation process, ensuring that all specified data aspects are correctly mapped.
2.2 Query Generation Agent
With the context package in hand, the Query Generation Agent powered by the Language Model constructs a query that spans multiple data entities. In our example, this means building a query that fetches sales data with conditions on transaction amount and product inventory.
- Query Building Engine: The LLM generates queries in the expected format(for e.g SQL query ) by aligning the user’s input with the schema and specified conditions, using logical operators to combine them.
· For instance: SELECT * FROM sales JOIN inventory ON sales.SKU = inventory.SKU WHERE sales.amount > 50000 AND inventory.level < 20.
- Validation Check: The agent runs preliminary checks to confirm that the query is correct, complete and includes all necessary fields and filters, ensuring accurate results.
2.3 Query Review Agent
Before sending the results to the user, the Query Review Agent validates the query’s completeness, accuracy, injection-detection and consistency. This is an extra evaluation layer to ensure the reliability of the solution where the query is validated with a combination of logic and LLM capabilities. The following aspects are verified:
- Completeness: Ensures all specified data components (e.g., sales amount and inventory level) are included.
- Accuracy: Cross-checks the constructed query with the schema requirements and predefined query patterns to catch any errors.
- Confidence Scoring Engine: LLM Scores the query based on criteria like field alignment and logical consistency. If the confidence score is low, the query is returned to the Query Generation Agent for refinement.
- Undesired Behavior check: This is another very important aspect to ensure the query generated is not actually the result of a prompt injection attack trying to perform undesirable activities like :
· Drop tables, deleting data or any such undesired data loss
· Unauthorized access to users by surpassing access privileges by using clauses like “OR 1=1” which will result in by passing all checks
This acts like an LLM Guard to detect potential P2SQL injections.
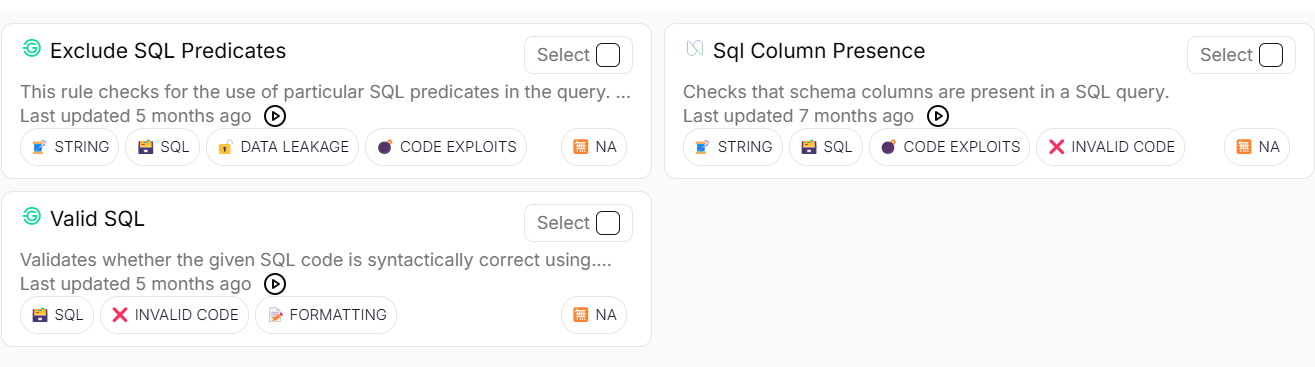
This can be included as a pre-processing step early in the flow to skip the processing if the input is undesirable or includes some kind of prompt injection using libraries like Guardrails.ai
Some useful validators which can be applied in this case include as shown below:
3. Interactive User Interface with Feedback Loop
The user interface provides an intuitive way for users to interact with the data, featuring real-time query generation along with capability to provide suggestions and options for feedback.
- Dynamic Query Suggestions: Using a cache (e.g., Redis), the system offers commonly used queries or suggestions based on similar past queries, enhancing efficiency of overall interaction. This ensures that if it’s a commonly used query, it can skip the entire generation process and get the data/query in a jiffy from the cache.
- Visual Data Representation: Results can be displayed as tables, charts, or graphs, depending on user preference. For instance, sales trends could be shown as a line chart, while inventory levels might be displayed in a bar graph. The solution can be enhanced to generate the output in the required format by incorporating relevant examples.
Below is an example of how we can talk to our data and generate charts to visualize the data –


- Feedback Collection: Users can rate the accuracy of the results, suggest modifications, or add notes. This feedback is integrated back into the knowledge base to continuously improve query interpretation and accuracy.
This interface enables users to give feedback, suggest corrections, or provide new examples in direct response to generated queries. The user feedback will be aligned with the existing schema and context, identifying any gaps or areas that need refinement. The updates will be incorporated in the form of
· Adds improved mappings, additional examples, or updated schema information to the knowledge base.
· Integrates new data relationships or context from user input to improve the precision of future queries.
· Reviews feedback patterns to fine-tune parsing, mapping, and query-building processes.
· Enhances the Context Detection Agent’s ability to accurately interpret similar queries in the future. A Human reviewer can be included in the flow who can review the updates before they are committed to the Knowledge base.

|Benefits of the Text-to-Query System for Enterprises
This solution offers several significant advantages:
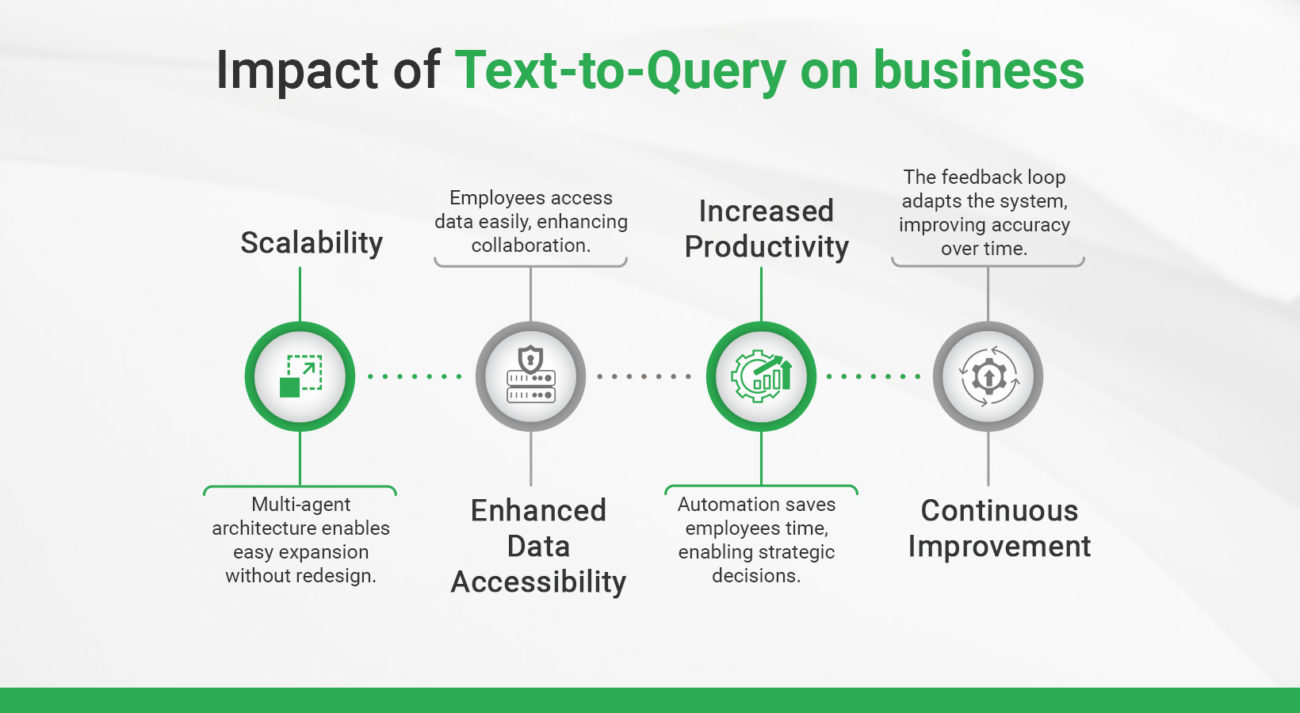
- Scalability: The multi-agent architecture and flexible schema mapping make it easy to expand the system to new data categories or departments without redesigning the entire system.
- Enhanced Data Accessibility: Employees across departments can retrieve complex data insights with a single query, breaking down silos and enabling better cross-functional collaboration.
- Increased Productivity: By automating the data querying process, employees spend less time manually sorting through data and more time making strategic decisions.
- Continuous Improvement: The feedback loop ensures the system adapts to evolving needs, with improved accuracy over time.
|Conclusion
A text-to-query system like the one outlined here can be transformative for enterprises with complex data landscapes. By combining LLMs with a well-structured schema, multi-agent query processing, and an interactive feedback-driven interface, companies can easily empower their teams to access and analyze data. Whether it’s sales, inventory, customer feedback, or financial data, such a system brings new agility and intelligence to enterprise operations, making data accessible and conversational.
As more organizations adopt this technology, “talking to your data” will become a cornerstone of business intelligence, allowing everyone from analysts to executives to unlock the full potential of their data with a simple question.
WalkingTree Technologies, with its extensive expertise in leveraging Large Language Models (LLMs) and building advanced AI-driven solutions, is at the forefront of transforming how enterprises interact with their data. Our reliable approach to developing secure, versatile, and user-centric text-to-query systems empowers organizations to unlock actionable insights with ease and efficiency. By integrating advanced AI, multi-agent architectures, and tailored strategies, we help businesses bridge data silos and accelerate decision-making processes. To explore how WalkingTree can implement a custom text-to-query solution tailored to your unique needs, contact us today and take the first step toward revolutionizing your data access.