Blogs
Apache Superset for Production workloads and Enterprise grade dashboards

Data visualization and dashboarding tools as part of the modern-day Business Intelligence (BI) ecosystem have evolved in features and capabilities. While most of these tools are proprietary, Apache Superset brings an exception to this. You can check on our earlier blog post on data exploration scopes through Apache Superset.
Apart from being open-source, Apache Superset is also acclaimed for its scalability and capability of handling tons of data for powerful visualizations and intuitive dashboards. When you consider an open-source data visualization and dashboarding platform with enterprise-grade custom visualization capabilities, Apache Superset offers the most credible solution.
In this blog post, we aim to explain the Apache Superset capabilities for building scalable data visualizations and dashboards to meet different enterprise needs.
| Understanding Apache Superset Architecture
Apache Superset is a powerful and scalable data visualization tool that has been deployed in production environments, such as at Airbnb, Dropbox, Twitter, Udacity, Lyft, Alibaba and many others. It utilizes a load balancer and scaling group to separate the web servers and workers, allowing for independent scaling. Additionally, it has a configurable cache using Redis to decrease the load on the data warehouse.
Superset can be easily deployed using tools like docker-compose or the helm chart. It is also built on SQLAlchemy, which provides support for connecting to a variety of databases and cloud data warehouses. Additionally, it is capable of OAuth authentication to support role-based security and data masking.
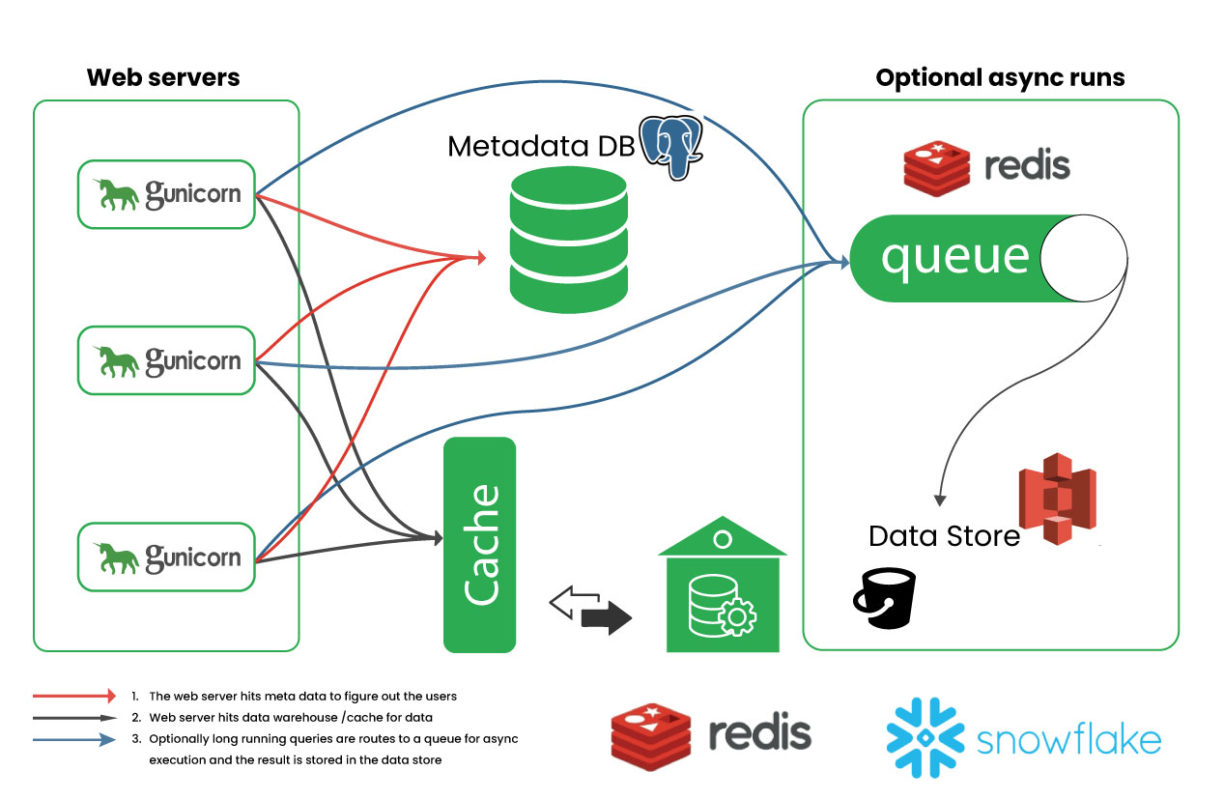
Thanks to the cloud-based architecture examples on leading platforms such as AWS, Microsoft Azure and GCP, the documentation for Apache Superset becomes explicit. These examples can be easily demonstrated with tools such as Terraform or Pulumi that can manage metadata across different managed databases.
| An overview of performance in a big enterprise setting
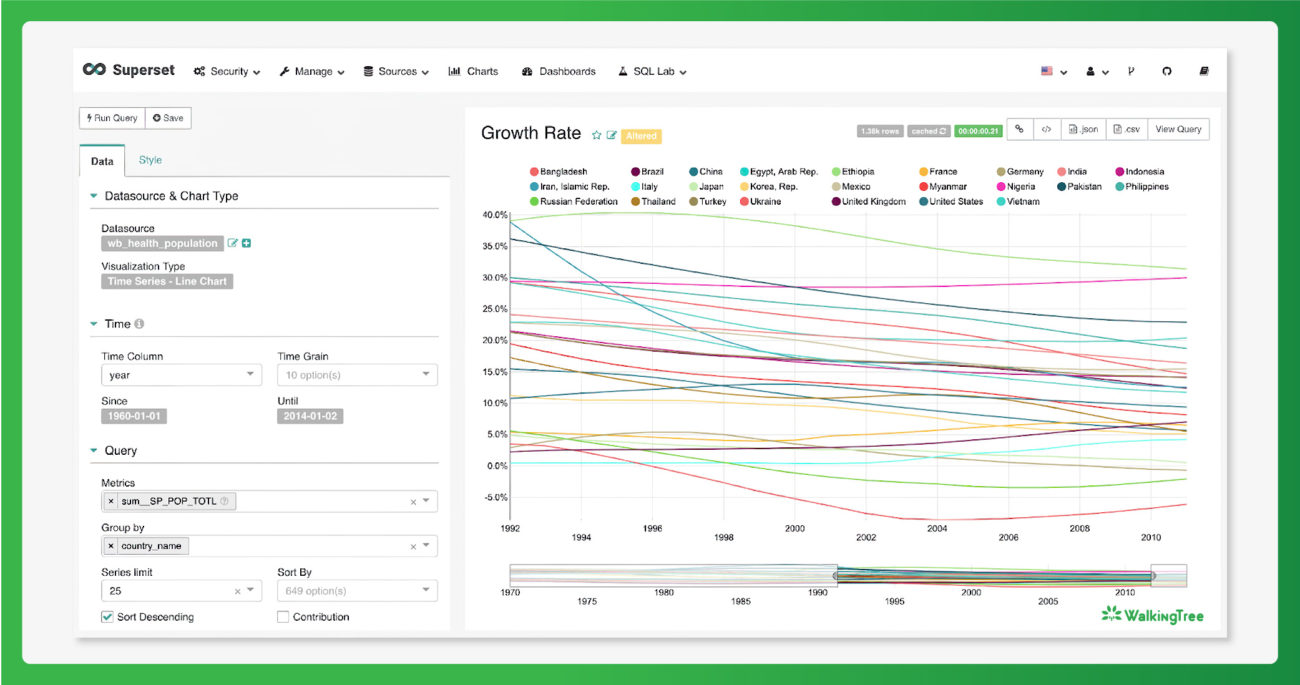
For any enterprise scaling up data exploration always remains a key concern and in this respect, Apache Superset stands out in the competition. Here are some characteristic capabilities of Apache Superset that address the scalability challenges.
- Web-based data consumption layer: Apache Superset is a web-based data visualization stack and hence it allows the heavy lifting of data through a connected database instead of storing the data within the platform. This gives more scalability to the data consumption layer. Also it provides the flexibility to customize the look and feel of the application and add custom visualizations based on the enterprise needs.
- Cloud-native architecture: Apache Superset comes with cloud-native architecture allowing more flexibility to choose between different metadata engines, caching mechanisms, and web servers. Because of these cloud-native characteristics, Apache Superset can be handled both through in-house native systems or third-party SaaS providers.
- Semantic analysis ingrained: Apache Superset makes use of semantic layers to help reuse past queries relentlessly and this ensures faster response time and scalability.
- Granular-level security filtering: In an enterprise setting, scalability of data-driven processes cannot compromise security concerns and Apache Superset allows the creation of granular-level role-based controls and filters ensuring stringent authentication and session handling.
- Preventing timeouts for extended queries: As part of its scalability features, Apache Superset offers a robust caching mechanism. Besides caching metadata and charts, Superset allows caching asynchronous queries so that users don’t face timeouts for lengthy and extended queries.
- Sharing across multiple teams: Apache Superset offers great flexibility for sharing among several teams through streamlined accessibility of data.
| Embracing Apache Superset for Optimum Scalability
So, Apache Superset comes equipped with all the features and capabilities that guarantee optimum scalability of dashboards and data visualizations. Now for ensuring scalability, Apache Superset requires 3 customization steps such as matching the Superset container with the specific use case, using rigorous caching for handling multiple and extended queries, and using a multitude of integrations as per the use case requirements.
Let’s explain each one of them here below.
Matching container with Superset use case
Irrespective of the target operating system platform you choose for running Apache Superset, to ensure scalability you need to customize the container for your specific use case. This will also help you run Superset on multiple platforms for orchestration such as Kubernetes.
You need to pick the Apache Superset image available officially on DockerHub. Now for matching this with your specific use case you need to incorporate a lot of dependencies such as your preferred database drivers.
Make sure you save the all-new custom configuration in the superset_config.py file after making changes in the main configuration file of Apache Superset. When configuring anew you can set new authentication rules for timing out queries.
When you finish loading the new configuration to the container, Apache Superset after recognizing the same will implement it.
Role-Based Access Control (RBAC)
Apache Superset has a built-in Role-Based Access Control (RBAC) feature that allows you to control access to the various features and functionality of the platform based on user roles. With RBAC, you can assign specific roles to users and restrict access to certain parts of the application or data based on those roles.
The roles available in Superset are: “Admin”, “Alpha”, “Gamma”, “Viewer”, and “Public”. The “Admin” role has the highest level of access and permissions, while the “Public” role has the lowest level. This feature can be accessed via the “Access” tab in the “Manage” section of the Superset web interface, where you can assign roles to users and groups, and manage access to dashboards, slices, and datasets.
Single Sign-On (SSO)
It does not have a built-in Single Sign-On (SSO) feature. However, it can be integrated with external SSO solutions such as Okta, Auth0, and Keycloak to enable SSO for Superset users. This can be achieved by configuring Superset to use the external SSO service for authentication and authorization.
| Custom UI capabilities

Apache Superset provides a web-based user interface (UI) that allows users to interact with and explore data. The UI is customizable to some extent, allowing users to change the layout, color scheme, and branding of the interface.
It is possible to create custom visualization types and custom actions, by creating new charts and/or customizing the existing ones, Superset provides a set of built-in visualization types, such as bar charts, pie charts, and line charts. Additionally, it allows to extend the functionality of the platform by creating custom Python code and integrating it with the Superset UI. It also allows to create custom actions that can be performed on the data, such as filtering and aggregation.
Superset also allows you to create custom dashboards, where you can arrange and display different visualizations and data sources in a way that makes sense for your organization. You can also customize the look and feel of the dashboards by adjusting the layout and applying different styles.
Overall, Superset provides a good degree of flexibility and customization capabilities, it’s important to note that it requires Python and web development knowledge to achieve more advanced customizations.
Data Alerts
Apache Superset provides an alerting feature that allows users to set up alerts on the data they are analyzing. This feature can be used to notify users when certain conditions are met, such as when a metric exceeds a certain threshold.
The alerting feature in Superset allows for the creation of alerts on specific charts and dashboards. Once an alert is set up, Superset will periodically check the data against the specified conditions, and if the conditions are met, an alert will be triggered. Alerts can be delivered through various channels such as email, Slack, and PagerDuty, and can be configured to notify specific users or groups of users.
It’s important here to note that Superset alerting feature is based on a celery task, this means that the alerting feature requires a running celery worker to function, and that the alerts are triggered periodically, not in real-time. Also, it’s important to configure the schedules and the workers accordingly to the desired alerting frequency.
Different caching techniques for scalability
A common problem we face when aligning multiple databases with Apache Superset is the challenge of facilitating too many queries after opening a dashboard. Running multiple queries will work as an obstacle to scalability.
To solve this problem, Apache Superset allows several different ways of caching. As soon as you create a chart, Apache Superset will save the same in the newly configured cache. This will help make the data instantly accessible to the user without requiring fresh queries. This not only boosts performance but also ensures better query-handling capabilities.
Apache Superset is built with Flask AppBuilder and naturally, it uses the inbuilt caching solution called Flask Cache. This caching solution offers support to several different caching backend platforms including Redis and Celery. The latter can also be used for configuring the backend to accommodate asynchronous long queries.
Apache Superset Integrations: Just ask what you need
One of the biggest reasons to use Apache Superset is the awesome range of custom integrations available to ensure scalable app performance. From data storage to cloud support to leading databases to a lot of SaaS platforms, Apache Superset practically offers a whole array of integrations supporting every dashboard development and deployment requirement.
Some of the most prominent integrations available for Apache Superset include Data Lake & Storage like Amazon S3, Azure Blob, Azure Table, Couchbase, Google Cloud, databases like Amazon DocumentDB, Azure Cosmos DB, Azure SQL, PostgreSQL, MongoDB, and an extensive range of SaaS solutions.
| Ending Notes
From custom configuration to robust data exploration capabilities, from the power of cloud-native architecture to granular-level data coverage, Apache Superset offers almost everything that a scalable enterprise-grade data visualization software can promise. It’s open-source but offers more robust capabilities than many proprietary dashboarding tools.