


Blogs
Smart AI Evolution: Strategies for Building Self-Improving Autonomous Agents


The year 2025 marks a pivotal moment for Artificial Intelligence as autonomous agents become ubiquitous in production systems. From text-to-SQL converters to chatbots to code and content generation tools, these intelligent systems seamlessly integrate into mainstream workflows. As they become indispensable, monitoring their performance has emerged as a critical priority. Numerous tools now enable real-time observability, evaluation and tracking of agent behaviors, ensuring operations remain efficient and aligned with expectations.
However, as these systems stabilize, a new frontier will gain prominence: the ability to collect and utilize feedback effectively. While much of this feedback is currently managed manually by users or human reviewers, the real breakthrough lies in enabling agents to autonomously leverage this feedback to self-improve their behavior in enterprise solutions. This shift toward self-improvement opens up a world of possibilities, offering the potential to refine agent performance dynamically without human intervention.
Several methodologies can be incorporated to make self-improvement a fundamental part of these systems.
The user experience (UX) for agent interactions should be designed to facilitate feedback collection, tailored to the use case and the chosen feedback mechanism. Feedback can be gathered from designated users during testing phases or integrated seamlessly into the application itself, allowing continuous collection of user input. This ongoing feedback loop ensures the agent’s performance is consistently refined and improved based on real-world interactions.
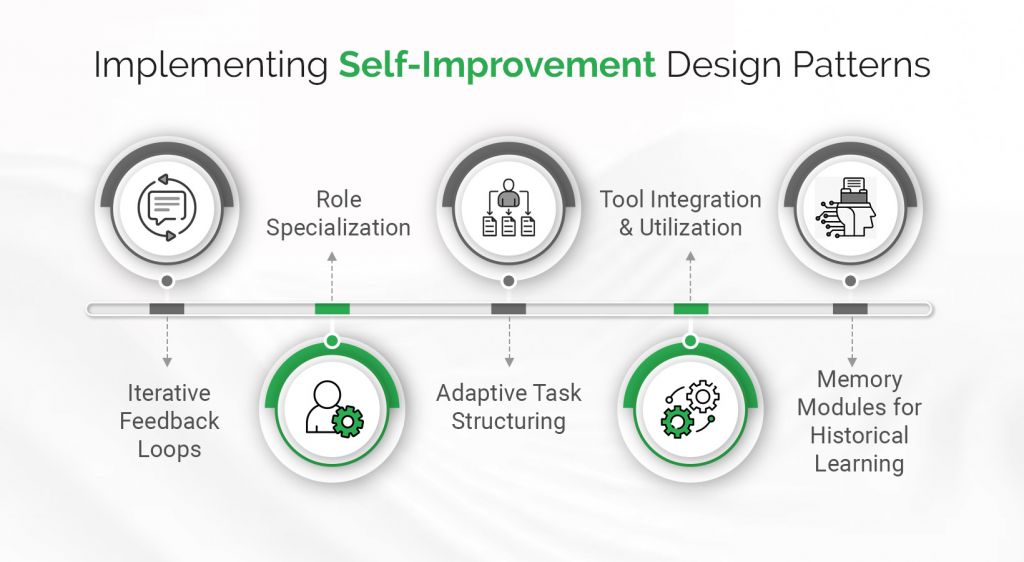
Let’s explore these self-improvement design patterns and their practical implementation approaches.
1. Iterative Feedback Loops
How It Works
The agent continuously evaluates its outputs, generates hypotheses for improvement, and implements changes. This cycle repeats until the system reaches an optimal state.
Example
A market research agent might start with a basic analysis of customer preferences. Over time, user feedback helps identify gaps (e.g., missing demographic data), leading to iterative refinements that result in more comprehensive insights.
Implementation
• Define Baseline Metrics: Set evaluation criteria such as clarity, relevance, and execution time.
• Feedback Collection: Use LLM agents for first-level review. Additionally, collect human user feedback as part of performance reviews.
• Hypothesis Generation: Enable the agent to propose changes, such as adding new data sources or refining methodologies, also considering the user-provided feedback.
• Execution: Implement and test the hypotheses, comparing the new outputs with previous results.
• Termination Criteria: Stop when performance stabilizes or reaches a predefined threshold.
The outcome of this feedback loop will be incorporated into the main flow in the form of either updated prompts with additional instructions or additional examples for short learning.
2. Role Specialization
How It Works
Agents are assigned specific roles, focusing on discrete tasks such as feedback collection, task execution, or quality evaluation. This enables feedback to specifically map to the role and adjust/improve it accordingly.
Example
In a medical imaging AI system, agents specialize as:
• Regulatory compliance monitors.
• Patient engagement advocates.
• Performance optimizers.
Implementation
• Identify Core Tasks: Break down the system’s goals into specialized functions.
• Agent Design: Develop agents tailored for each role, ensuring they have the required tools and capabilities.
• Task Assignment: Use a task allocator to distribute responsibilities.
• Integration: Ensure smooth communication between agents to avoid silos.
• Evaluate Specialization: The feedback evaluation agent will review the user feedback, and make recommendations to improve other role-specific agent prompts.
We can further try to force the user to provide very specific feedback, which helps the agent decide which role was not performed well and/or the feedback is related to which role, which enables the agent to suggest improvements to the specific role.
The advantage of this approach is the specificity of each role which improves the accuracy of the overall autonomous agent workflow, making it self-improving.
3. Adaptive Task Structuring
How It Works
Tasks are dynamically restructured based on complexity and changing requirements, ensuring workflows remain efficient. The feedback caters to directing the agent on which tools or methodologies it should prefer to use to achieve better results.
Example
A content creation agent might initially rely on templates for LinkedIn posts. As engagement metrics evolve, it adapts by creating personalized content based on audience data.
Implementation
• Dynamic Workflow Design: Use algorithms to adjust task parameters in real-time based on feedback.
• Task Prioritization: Develop priority queues to address high-impact tasks first.
• Context Awareness: Incorporate contextual analysis tools to tailor tasks to situational needs.
• Reevaluation Cycles: Periodically assess whether the task structure aligns with system goals.
The collected feedback will advise the system to dynamically adjust the workflow nodes and tasks deciding on the priority, context, etc. and hence enable the system to be self-improving.
4. Tool Integration and Utilization
How It Works
Agents utilize specialized tools such as web scrapers or APIs to enhance their capabilities. This system would require additional knowledge/context enhancement to improve the system results.
Example
In a supply chain management system, agents might use:
• Web scraping tools for supplier analysis.
• Optimization algorithms for logistics planning.
• APIs for automated communication.
Implementation
• Select Domain-Specific Tools: Identify and integrate tools tailored to the agent’s role.
• Train Agents: Equip agents with the knowledge to use these tools effectively with the capability to enhance with newly provided sources.
• Performance Testing: Regularly evaluate tool effectiveness and update integrations as necessary.
• Automation: Develop APIs or scripts to streamline tool usage within workflows.
The user feedback directs the system to use additional context by providing relevant sources(from web) or specific sections/keywords for improving the RAG relevancy. Additionally this could be included in the RAG metadata or the RAG summarized structure to improve future responses from the RAG.
5. Memory Modules for Historical Learning
How It Works
Agents maintain a memory of past outputs, enabling them to learn from mistakes and build on successes. Collect expected responses from the user as part of the feedback so this can be used as the learnable history to make the system self-improving.
Example
A lead generation agent might analyze historical campaign data to refine targeting strategies, improving future results.
Implementation
• Memory Storage Design: Implement databases to store key outputs and evaluation metrics.
• Retrieval Mechanisms: Develop APIs to access historical data during decision-making.
• Learning Algorithms: Can make use of machine learning models to identify patterns in historical performance to provide proper recommendations to the agent.
• Periodic Cleanup: Remove outdated or irrelevant data to maintain efficiency. Collect user feedback/rating on the response quality to take certain decisions.
Maintain the sanctity of the historical data by evaluating and adding the data which becomes a first-hand reference for the agent for future interactions.
Self-improving autonomous agents are set to strengthen how AI systems operate, adapt, and scale. By leveraging methodologies such as iterative feedback loops, role specialization, adaptive workflows, and prompt refinement, these agents can dynamically enhance their performance while reducing reliance on human intervention. The integration of user feedback and the ability to refine prompts or update retrieval strategies further position these systems as indispensable tools for tackling complex, real-world challenges.
However, as we advance toward widespread adoption, it is crucial to anchor these developments within a framework of responsible AI and ethical practices. Ensuring transparency, minimizing biases, and respecting user privacy must be core principles in the design and deployment of these systems. Responsible implementation not only safeguards against unintended consequences but also fosters trust and reliability in the broader AI ecosystem.
With thoughtful design and a commitment to ethical AI, self-improving agents can unlock unprecedented potential, driving innovation while upholding the values that make technology beneficial for all. The future of AI is not just autonomous but also accountable, and together, we can shape a world where these systems empower industries and individuals alike.
The full-fledged adoption of LLMs and agents in general in enterprise use, will require patience to gradually adopt piece by piece and give it time to improve, mature and settle by putting the complete ecosystem in place including evaluation, feedback and self improvement aspects. This will help build the credibility of the system and make it more and more autonomous and less and less dependent on human review.
At WalkingTree Technologies, we specialize in building intelligent autonomous solutions tailored to your business needs. With our deep expertise in AI, automation, and enterprise-grade technology solutions, we empower organizations to leverage self-improving AI agents that optimize processes, enhance productivity, and deliver measurable results.
Are we ready to embrace this new paradigm? Let’s make it happen.